
但VLA动作预测使用Diffusion的方法一定比基于Regression的方法效果好吗?著名的OpenVLA团队近期通过提出的OpenVLA-OFT给出了否定答案。该团队通过Regression等一系列优化的微调方法,不仅在指标精度上超过Diffusion,而且在速度和真机表现上也一并超过Diffusion。到底是怎么回事?下面我们就一探究竟。
机器人VLAs通过在大规模机器人数据集上微调预训练的视觉-语言模型,以实现低级机器人控制的策略,这在不同的机器人和任务上展现出了强大的任务执行能力、语义泛化能力和语言跟随能力。
OpenVLA-OFT 研究并给出了在适应新机器人和新任务时的关键设计决策,其整体架构如下图所示,可以总结提炼出VLA微调的3个黄金法则,接下来我就开始逐一为大家分析讲解。
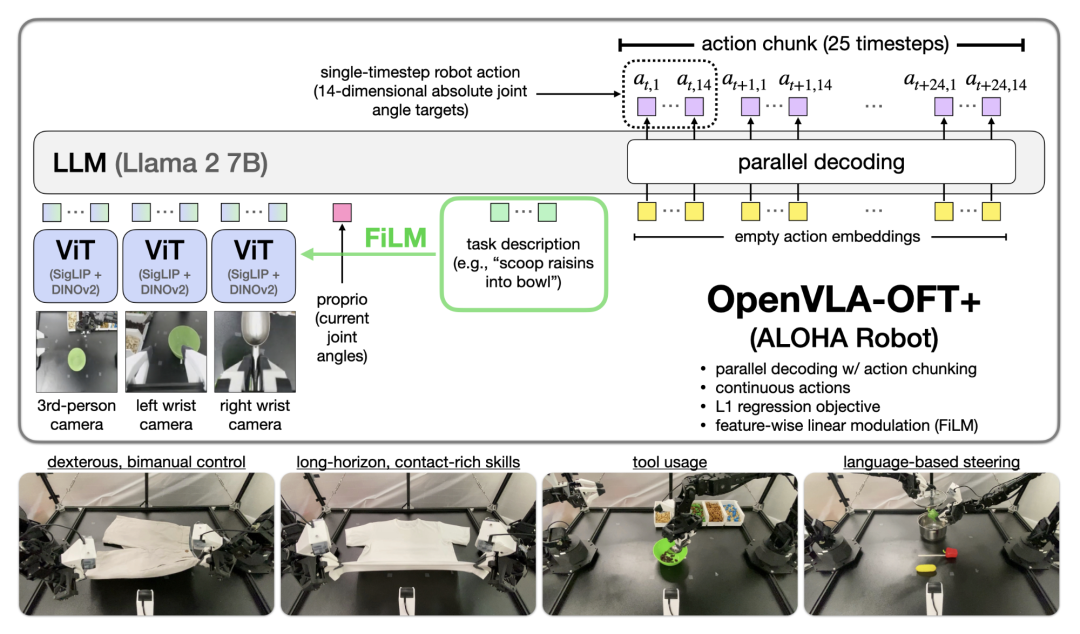
VLA微调黄金法则
OpenVLA-OFT 重点分析了三个关键设计选择:动作解码方案(自回归 vs. 并行生成)、动作表示方式(离散 vs. 连续)以及动作学习目标(下一步标记预测 vs. L1 回归 vs. 扩散模型)。

VLA微调方法对比
法则一: 动作解码方案——并行+分块
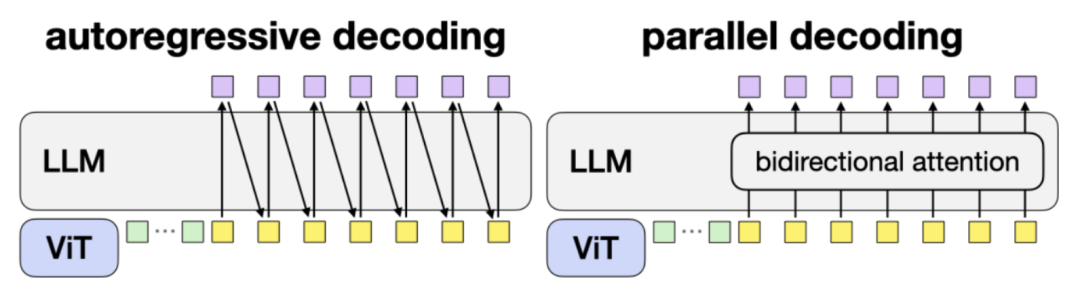
动作解码方案对比
自回归解码的问题
自回归解码(autoregressive decoding):存在需要逐个token生成动作、推理延迟高的问题。
例如,动作维度为 D,分块大小为 K 时,推理需要 K × D 次前向传播。
并行解码的优化
并行解码(parallel decoding):通过输入空动作嵌入(empty action embeddings),并修改因果注意力(causal attention)为双向注意力(bidirectional attention)。
所有动作同时生成,推理时只需 1 次前向传播(降低计算量和耗时)。
动作分块的加持
动作分块(action chunking):在解码器输入中插入 K 个空动作嵌入,使模型直接预测 K 个时间步的动作。
这样,模型可以一次性生成 K × D 个动作,吞吐量提高 K 倍,且额外的推理延迟极小,在并行解码的基础上进一步降低了总的推理延迟。
尽管并行解码理论上可能比自回归方法表达能力稍弱,但实验结果表明,在各种任务上性能并无下降。
相较于自回归解码的方式,并行解码结合动作分块不仅能够提高推理效率,实验结果表明还能提升下游任务的成功率,同时可以增强模型在输入-输出规格上的灵活性(因为并行解码方式更简单了)。
法则二:动作表示方式——连续动作
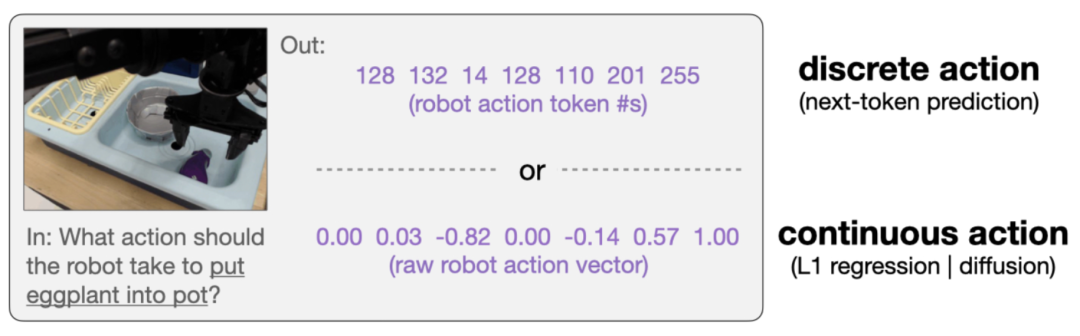
动作表示方式对比
原始 OpenVLA 使用离散动作 token
每个动作维度归一化到 [-1, +1],并均匀离散化为 256 个 bin。
这种方法无需修改模型架构(语言模型标准的Decoder-only架构),但可能损失精细动作信息(动作离散为256 个 bin 划分的固定值)。
两种连续动作学习目标
L1 回归(L1 regression)
将解码器输出层替换为 MLP 动作头,直接映射到连续动作值。
优化目标:最小化预测动作与真实动作的 L1 误差。
优势:保持并行解码的高效性,同时可能提高动作精度。
条件去噪扩散(Conditional Denoising Diffusion)
模型学习预测扩散过程中加入的噪声。
推理过程:从噪声初始化,逐步去噪(50 个扩散步)。
优势:可建模更复杂的动作分布。
劣势:即使结合并行解码,仍需多次前向传播,影响推理速度。
实验结果表明,连续动作(continuous actions)表示相较于离散动作(discrete actions)表示可以进一步提升模型性能(连续比离散动作更精细,连续回归比连续扩散效率更高)。
法则三:动作学习目标——L1 回归
与普遍认为基于Diffusion的策略(因为其更具表现力并能建模多模态动作)在模仿学习中优于基于L1 Regression的策略的观点相反,OpenVLA-OFT的研究表明:使扩散模型强大的特性——例如其捕捉复杂动作分布的能力——在训练时如果遇到不完美的示范数据,可能会带来问题。具体来说,这些模型可能会精确复现训练示范中的次优行为,从而在实际部署时影响策略的性能。
我们可以通过以下实际示例清楚地看到这一差异:在使用基于Diffusion的微调 VLA(π0)执行椒盐脆饼的舀取任务时,机器人失败了,因为它将勺子插入容器的深度过大。这一问题行为的根源在于,训练示范中存在一些专家示范序列,其中演示者也曾将勺子插入过深(导致策略在收回勺子时遇到困难)。在 12 次实验中,π0 有 2 次复现了这一错误行为。

π0 两次失败案例之一
相比之下,OpenVLA-OFT+(+代表增加语言调制模块,不影响Regression对比Diffusion的结论) 采用 L1 Regression,在学习过程中能够掌握最佳的勺子插入深度——既不会过深,也不会过浅,从而能够更可靠地完成舀取任务,在该任务上实现了 100% 的成功率。

OpenVLA-OFT+ 全部成功案例之一
因此,相较于更复杂的Diffusion方法,采用简单的L1 Regression作为微调目标的VLA在性能上可与基于Diffusion的微调方法相媲美,甚至取得更好的任务表现,同时具备更快的训练收敛速度和推理效率,为VLA适配提供了一种更高效的解决方案。
实验结果
LIBERO模拟任务实验对比
任务成功率对比
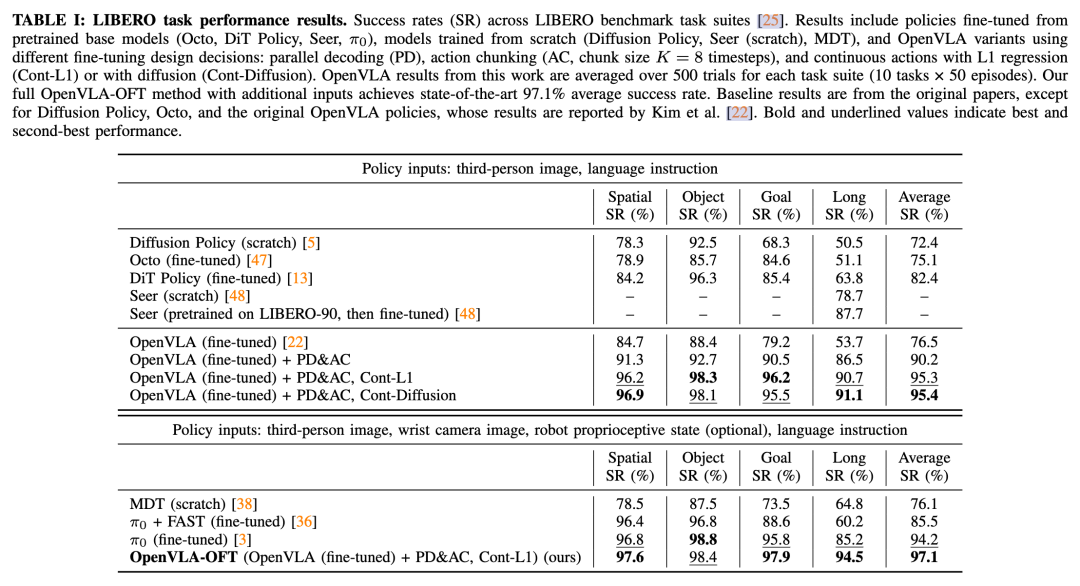
实验结果(见 表 I)表明:
1. 并行解码 + 动作分块不仅提高了吞吐量,还显著提升了任务成功率:
比自回归 OpenVLA 提高 14%(绝对值)。
LIBERO-Long 任务的提升尤为明显,表明:
动作分块有助于捕捉时间依赖关系。
减少累积误差,从而实现更平滑、更可靠的任务执行。
2. 连续动作(L1 回归和扩散)进一步提高成功率 5%(绝对值):
可能由于动作预测精度更高。
L1 回归和扩散模型表现相当:
说明高容量(high-capacity)的 OpenVLA(使用7B LLama2 和 双Vision Encoder: DINOv2和SigLIP;π0 大概是3B多)可以有效建模多任务动作分布,即使使用简单的 L1 回归。
推理效率对比
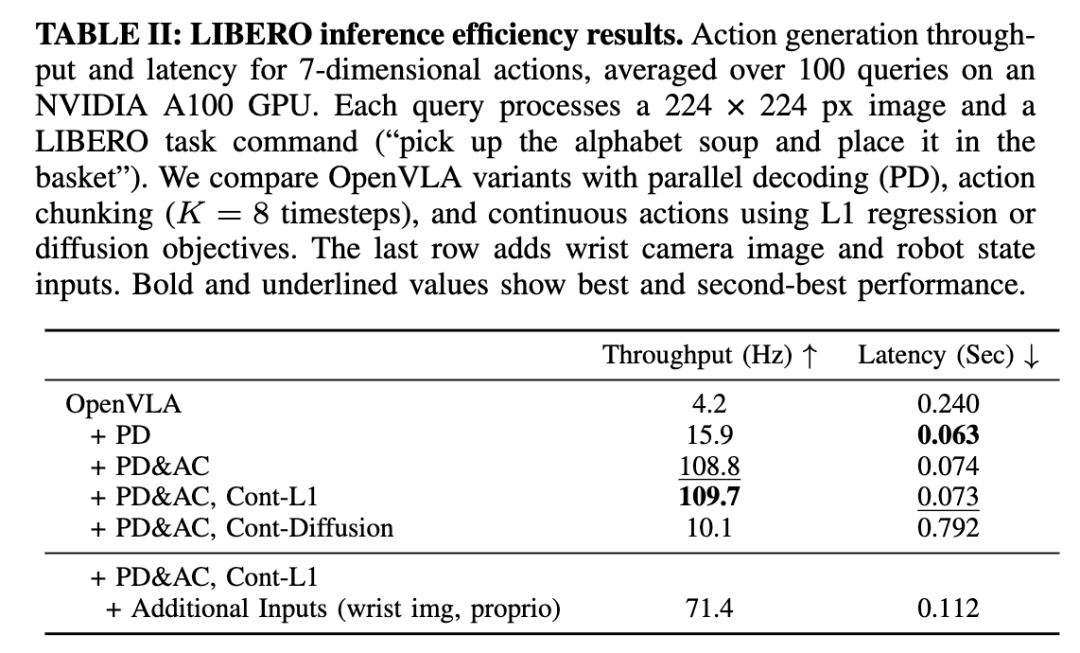
实验结果(见 表 II)表明:
1. 并行解码(PD)提升 4× 吞吐量:
通过用单次前向传播替换 7 次自回归解码,显著减少推理延迟。
2. 动作分块(K=8)略微增加 17% 延迟(由于解码器注意力序列变长),但吞吐量提升 26×:
结合 PD+AC 后,整体加速效果巨大,远超原始 OpenVLA。
3. 连续动作(L1 回归)几乎无额外计算成本:
额外的 MLP 动作头相对于基础模型的计算量可以忽略不计。
4. 扩散模型(Diffusion)推理延迟增加 3×(需 50 轮去噪步骤),但吞吐量仍比自回归 OpenVLA 高 2×:
尽管动作块之间的停顿时间更长,扩散模型仍然比自回归模型更快完成整个任务。
输入-输出灵活性
在前述推理效率评估中可以看到:
并行解码允许 OpenVLA 生成 动作块,几乎不增加延迟,从而提高模型输出的灵活性。
显著的推理加速(PD+AC)还为处理更多输入提供了算力余量。
在 OpenVLA 的基础上引入额外输入:
(1)机器人本体状态(proprioceptive state);
(2)手腕摄像头(wrist-mounted camera)图像。
结果:
(1)视觉 patch embedding 从 256 增加到 512(输入序列长度翻倍)。
(2)推理速度仍保持高吞吐量(71.4 Hz)和低延迟(0.112 秒)(见 表 II)。
在 LIBERO 基准测试中,带额外输入的 OpenVLA 微调策略进一步提高了所有任务集上的平均成功率(见 表 I)。
(1)超越了最先进的 π0 和 MDT:
π0 使用更大规模的预训练数据和更复杂的流匹配(flow matching)目标。
MDT 采用多模态扩散Transformer(Multimodal Diffusion Transformer)。
(2)即使基础模型比最新的 VLA 预训练数据更少,OFT 的设计仍然刷新了 LIBERO 任务的新 SOTA。
总结
(2)扩展模型输入(手腕摄像头 + 本体状态)= 进一步提升任务表现,超越 SOTA。
(3)PD + AC + 连续动作表示 + L1 回归 = 简单高效的VLA训练策略 。
ALOHA真机任务实验对比
任务成功率对比
ALOHA 是一个高频控制的双臂操作平台,任务包括复杂的灵巧操作,且这些任务在 OpenVLA 预训练时从未见过(预训练数据仅包含单臂机器人)。

ALOHA 与 OpenVLA 预训练的差异
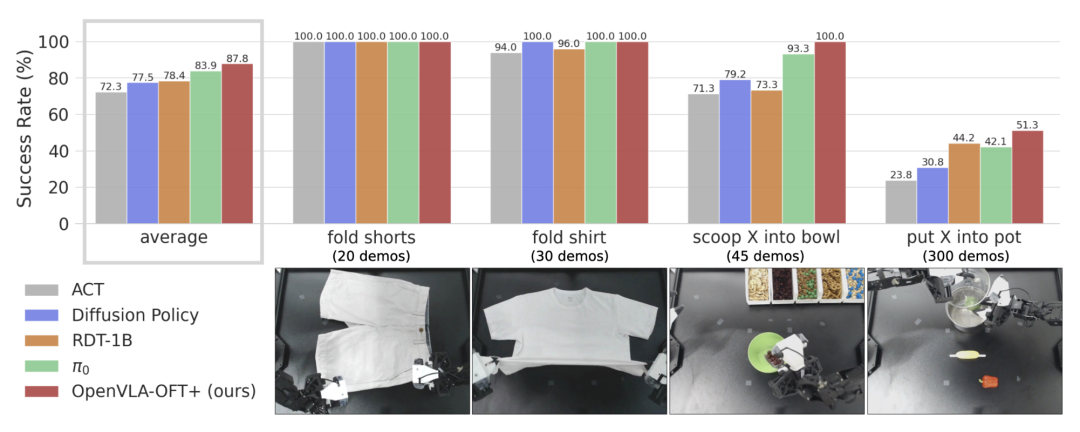
ALOHA操作任务精度对比
1. ACT
基本任务可完成,但动作不精确
在四个任务中表现最差
2. Diffusion Policy
在 折叠衣物 和 舀取食材 任务上,表现接近甚至超过 RDT-1B
在 "put X into pot" 任务上失败(该任务训练数据较多,说明扩散策略的可扩展性有限)
3. RDT-1B
语言理解能力强(交替条件注入)
闭环反馈能力弱:在 "scoop X into bowl" 任务中,如果未能将食材倒入碗中,仍然会继续错误操作
4. π0
任务执行更平稳
能纠正错误(如在 "scoop X into bowl" 任务中,若初次失败,可重新尝试)
语言理解能力略逊于 RDT-1B(其实RDT-1B的语言理解能力也不好)
5. OpenVLA-OFT+
任务执行 + 语言理解能力最优
尽管 OpenVLA 仅预训练于单臂数据,但在双臂任务中仍然超越了 RDT-1B(预训练于双臂操作数据) 和 π0(预训练于双臂操作数据(8K 小时))
微调策略比预训练数据量更关键!
推理效率对比
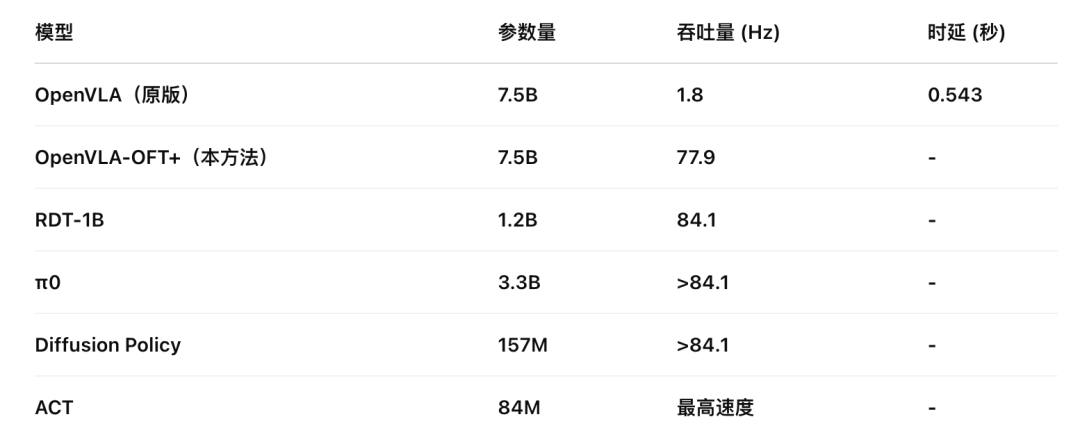
参数量和吞吐量对比
分析
原版 OpenVLA 推理极慢(1.8 Hz)
OpenVLA-OFT+ 提高至 77.9 Hz
推理速度 ACT > π0 > Diffusion Policy > RDT-1B > OpenVLA-OFT+ > OpenVLA
ACT 速度最快(架构最小 + L1 回归)
π0 速度优于 RDT-1B(尽管参数更大,但有 JAX 优化)
总结
OpenVLA-OFT+ 以 7× 参数量,接近 RDT-1B 速度(77.9 vs. 84.1 Hz)
单步推理效率远超扩散模型(RDT-1B 需多步去噪,OpenVLA-OFT+ 仅需一次前向传播)
其他提升经验策略
可选的语言调制模块(FiLM)
在 ALOHA 机器人设置中,多个摄像头(包括腕部安装摄像头)带来的视觉输入冗余,可能导致模型在执行任务时难以正确跟随语言指令。作者观察到以下问题:
训练过程中,策略可能学习到虚假相关性(spurious correlations)
由于视觉输入的复杂性,模型可能依赖于错误的视觉特征来预测动作,而忽视语言指令。
这会导致测试时模型无法准确执行用户命令。
语言输入可能只在任务的特定时刻起关键作用
例如,在“put X into pot”任务中,只有在抓取勺子后,决定舀取哪种食材时,语言信息才至关重要。
如果没有专门的机制,训练模型正确关注语言输入将变得困难。
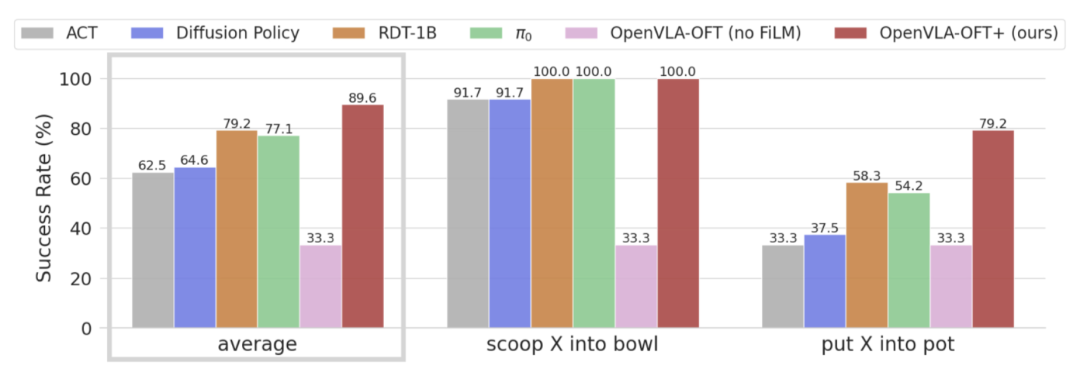
ALOHA 语言跟随结果
在“put X into pot”任务中,作者发现学习到的策略在语言跟随能力方面表现较差,因此尝试显著增加训练数据集的规模,以测试这是否能改善模型的语言理解能力。然而,实验表明,仅仅将数据集规模增加一倍或四倍并不能解决问题,它仅带来了轻微的语言跟随能力提升。为了实现更显著的语言理解能力提升,我们必须采取额外的措施,以鼓励模型更加关注语言信息 —— 例如,在微调OpenVLA策略时使用FiLM,它可以通过在所有视觉特征中注入语言嵌入信息来增强语言理解能力。
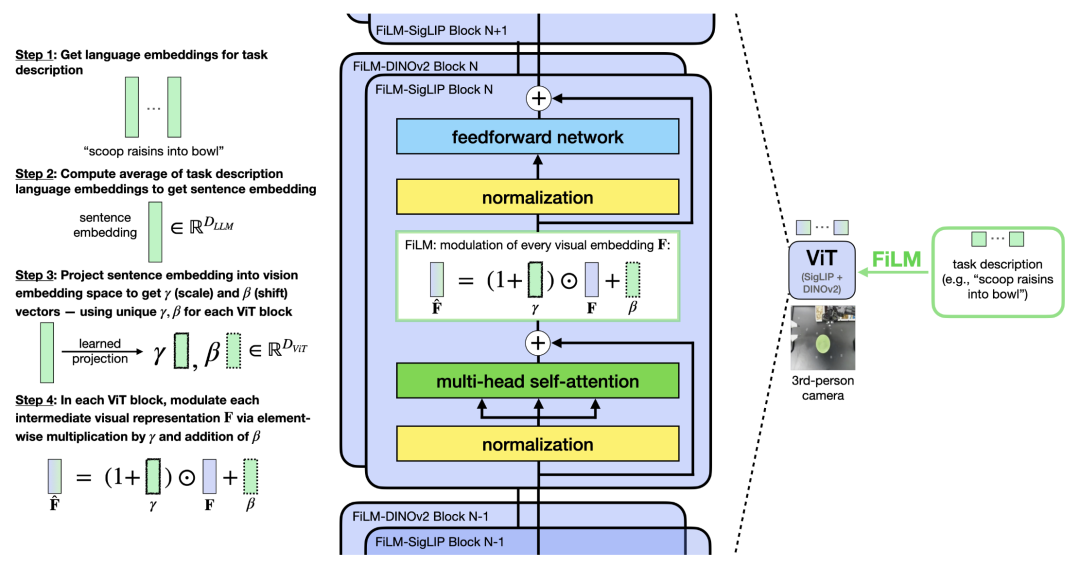
FiLM: Feature-wise Linear Modulation
预训练的影响
微调方法 + 额外输入/输出 会导致训练数据分布偏移(distribution shift),因此,VLA 预训练的表示是否仍然有助于学习?

通过去除 OpenVLA 预训练,直接用 OFT 方案微调 VLM的实验表明:
去除预训练会导致成功率下降 5.2%(绝对值)。
说明 OpenVLA 预训练表示仍然对机器人策略学习至关重要。
一些现象观察和分析
时间推移导致的性能下降
ALOHA操作任务精度对比(put X into pot 成功率显著低于其他任务)
论文题目:Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
论文地址:https://arxiv.org/pdf/2502.19645

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)