
引言
在进行模型编译和验证的过程中,为了能够更深入地了解模型内部的具体情况以及根据实际需求对模型加以调整,我们常常会有获取模型特定组件属性以及对模型结构进行修改的需求。具体来说,我们可能需要借助 API 来获取 BC/HBM(这里可以理解为模型中特定的模块或者资源)的一系列属性,例如输入输出的名称、量化scale等信息。这些属性对于准确把握模型的输入输出属性以及数据处理方式至关重要。与此同时,我们还可能需要利用 API 对模型做一些修改,像删除某些不必要的节点,以此来优化模型的结构,提高模型的运行效率。
本文将紧密结合模型部署和验证的实际需求,详细罗列相关 API 的具体应用场景,并给出相应的使用代码示例,旨在为开发者提供全面且实用的参考,帮助大家更好地完成模型编译、验证、部署等一系列工作。
export bc参数配置
QAT完成后,导出qat.bc时可能需要做一些配置,这部分在作者之前发布的帖子中进行了详细的描述,欢迎大家去翻阅:
【J6工具链部署实用技巧-1】如何修改bc和hbm模型的输入输出名称和顺序
导出qat.bc时,笔者还想对广大开发者们提出以下建议:
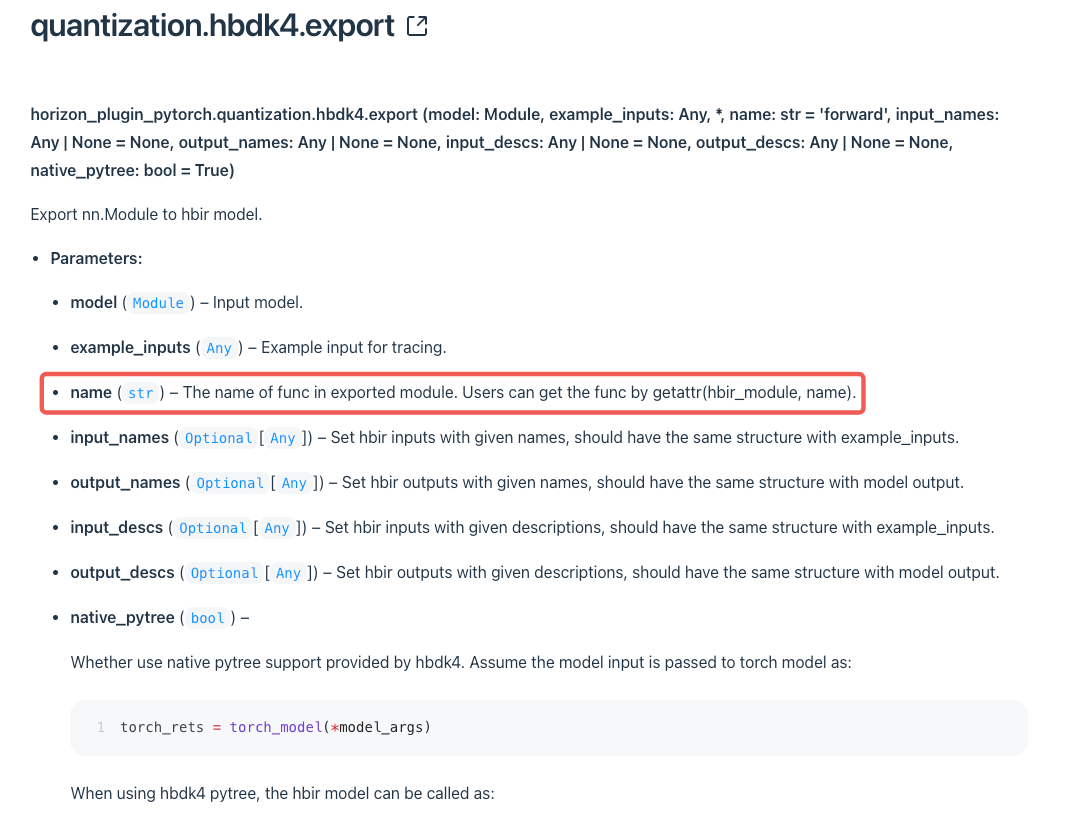
导出bc时建议配置name参数,并且在name中包含模型任务/版本/工具链版本等信息,有利于在部署/验证时辨别:
建议在导出的时候把模型中没有使用到的输入输出在模型forward代码中删除,防止出现未知的问题;
PS:当然,现在工具链也提供了删除无效输入输出节点的api,后文会安利的。
获取quantized.bc输入/输出端的信息
在前面的文章中,我们其实已经多次提及bc/hbm输入输出属性的获取方式了,比如那么,shape,数据类型等信息。但是在用户实际的部署场景中,比如在验证quantized.bc和hbm模型输出一致性时,假如模型输入/输出端的量化/反量化节点被删除了,如果想在python端推理quantized.bc时给输入做量化,或输出做反量化,那么就需要使用python api来获取对应的scale,尤其是在模型具有比较多的输入输出的情况下,使用api来获取scale值,然后做量化和反量化尤为便利。
如下为python端获取quantized.bc 输入输出端scale的示例代码:
为了方便用户在做一致性验证时对输出输出的处理,这里提供在推理时对quantized.bc浮点输入做量化的示例,如下所示:
删除无效的输入输出节点
在实际操作过程中,部分用户在执行 export qat.bc 这一操作时,会出现不规范的情况。具体而言,当这些用户进行 qat.bc 文件的导出操作时,在 forward 的过程中存在一些并未被实际使用到的无效输入。下面,我们可以通过如下图所示的情况来更直观地了解这种现象:
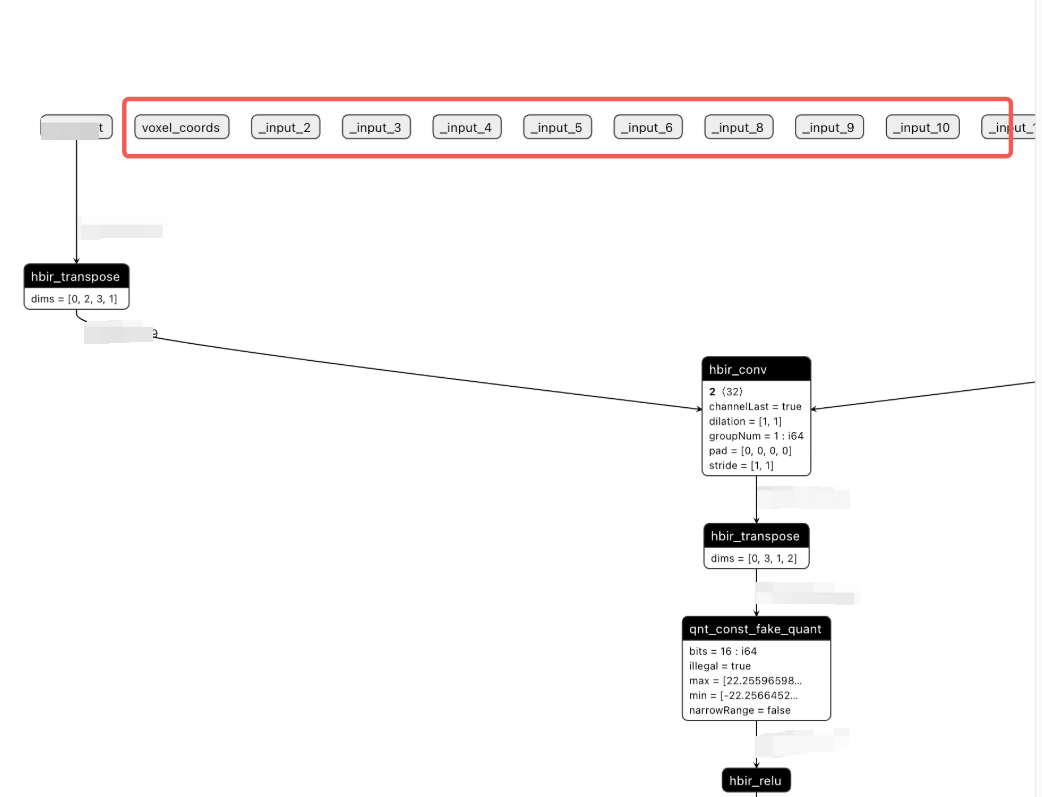
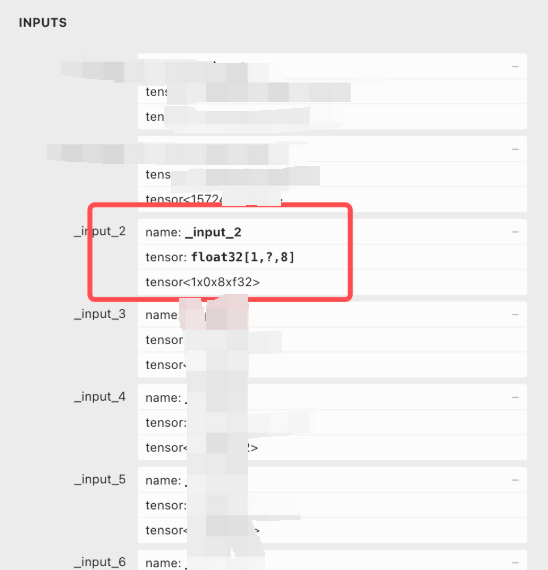
在这种情况下,如果无效输入中存在非法的数据,比如动态输入,会使qat.bc在convert时报错,即下图中的_input_2的shape为[1,?,8],这种非法的输入在convert阶段会报错。
所以工具链中提供了python api来删除bc模型中的无效输入/输出,示例代码如下所示:
bc/hbm一致性验证示例代码
结合以上bc修改的api,本帖提供一份完整的一致性验证代码,其中使用python推理quantized.bc,使用hbm_infer工具推理hbm。示例代码如下所示:
输入数据的读取代码需要用户根据实际的目录和文件格式进行修改,本示例是以.bin文件为例,如果是numpy或者pkl文件,需要根据实际情况进行读取和处理。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)