
前言
本帖将结合演讲内容和相关学术论文,对理想汽车的智驾方案演进路线进行介绍。
端到端+VLM方案
众所周知,中国的道路因素复杂得令人发指,懂得都懂,且行业标杆Tesla也处理不好这种场景这里就不一一罗列了。因此,大模型技术应该是目前可以解决这种复杂场景最好的办法,理想汽车根据自己的理解提出了端到端+VLM方案。

快慢思考系统
理想的端到端+VLM方案充分借鉴了心理学家丹尼尔·卡尼曼(Daniel Kahneman)提出的快慢思考系统,其核心看法是人类的思维系统由快-慢两个系统组成,详细的介绍如下表所示:
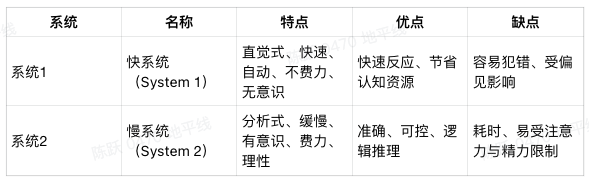
那么在快慢思考系统思想的启发下,理想汽车的端到端+VLM设计方案可以总结为:
system1-action: 快系统,部署E2E端到端模型系统在一颗ORIN X芯片上,只需要输入传感器数据,不需要高精地图等先验知识,端到端模型会根据车载传感器数据直接输出轨迹信息,模型完全由数据进行驱动。
system2-decision: 慢系统,部署VLM大模型在另一颗ORIN X芯片上,VLM为具有22亿参数量的LLM基座模型,具备全局理解与推理能力,实现多模态数据理解和逻辑推理,VLM通过思维链CoT做复杂的逻辑分析,并将结果反馈给智驾决策快系统。
端到端+VLM方案介绍
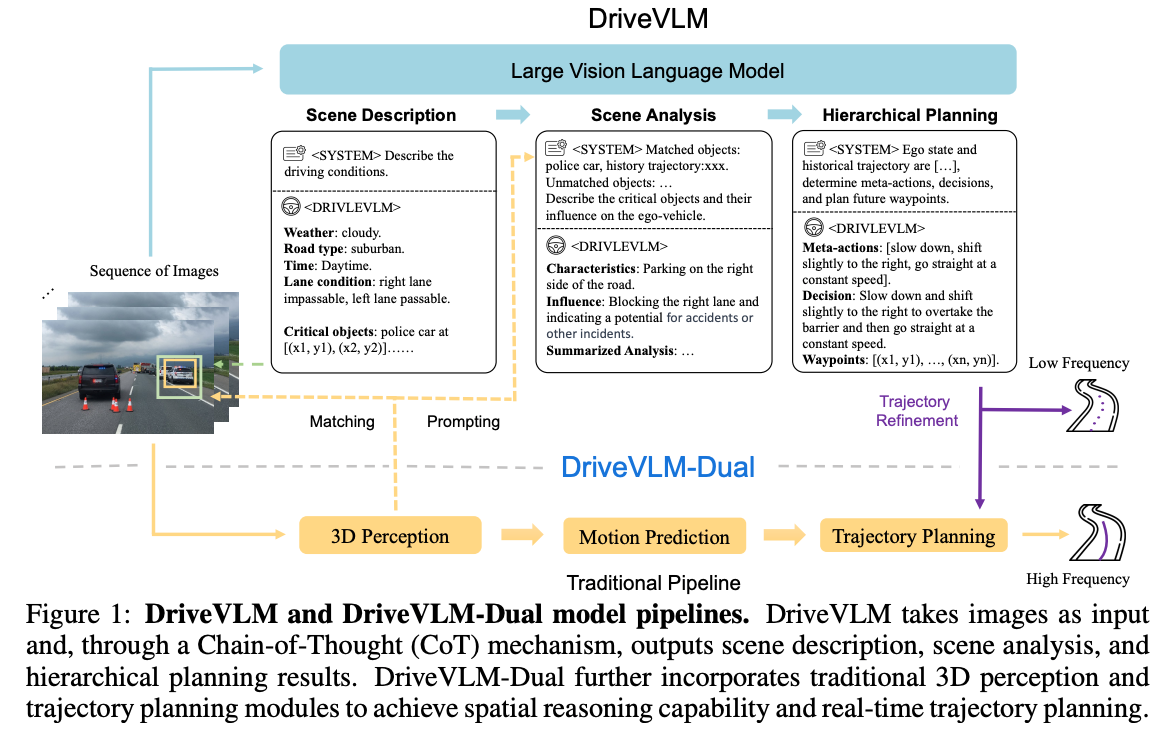
DriveVLM
DriveVLM 输出Scene Description(场景描述)、Scene Analysis(场景分析)和Hierarchical Planning(层级规划),这3个部分的作用分别是:
Scene Description(场景描述)
任务:语言描述当前驾驶环境。
示例输出:
Weather: cloudy
Road type: suburban
Time: daytime
Lane condition: right lane impassable, left lane passable
Critical objects: e.g., police car at bounding box
Scene Analysis(场景分析)
任务:分析关键目标对自车的影响。
示例输出:
Characteristics: “police car 停在右侧”
Influence: “阻挡右车道,存在事故风险”
Hierarchical Planning(层级规划)
任务:生成具体驾驶计划,逐步输出:
Meta-actions(元动作):如减速、右偏等操作单元Decision:对元动作的组合解释Waypoints:一系列(x, y)点构成的未来轨迹
这些输出频率较低,因推理复杂,称为“Low Frequency”。
DriveVLM-Dual
DriveVLM-Dual将 DriveVLM 结果作为提示或指导,结合传统的三维感知、运动预测、轨迹规划模块,这3个模块的作用分别是:
- 3D Perception:将图像中识别的关键目标,与3D检测器匹配,提升空间定位精度。
- Motion Prediction:传统模块预测周围目标未来动作。
- Trajectory Planning:结合 VLM 给出的参考轨迹(如 Waypoints),进行高频实时细化。
Trajectory Refinement
视觉语言模型(VLM)虽然擅长理解复杂场景,但存在两大弱点:
- 推理慢:不能实时运行(比如每秒几次);
- 空间精度不高:输出轨迹点是基于语言生成的,易产生偏差。
Trajectory Refinement 的流程可以用以下公式描述:

端到端+VLM在量产中的不足
虽然DriveVLM-Dual 系统解决了部分问题,但是在实际量产中发现了诸多不足,如下所示:
虽然可以通过 异步联合训练让端到端和VLM协同工作,但是由于他们是两个独立的模型且运行频率不同,所以在做联合训练和优化是非常困难的;
其次,VLM模型是基于开源的LLM大语言模型,使用了海量的互联网二级图文数据做预训练,导致其在3D空间理解和驾驶知识方面是有所不足。尽管可以通过一些后训练手段进行弥补,但是它的上限仍然不是很高;
自动驾驶芯片如Orin-X和Thor-U的内存带宽和算力是不及GPU服务器的,如何进一步提升模型的参数量和能力,同时还能实现在高效的推理,这是个巨大的挑战;
目前驾驶行为的学习更多依赖于transformer进行回归建模,但是这种方法难以处理人类驾驶行为的多模态性,这里的多模态性是指在相同的场景下,不同人的选择是不同的,同样一个人在不同精神状态下的驾驶行为也是不同的。
参考资料

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)