
前言
【理想汽车智驾方案介绍专题-1】端到端+VLM方案介绍
【理想汽车智驾方案介绍专题-2】MindVLA方案详解
在上述两篇系列帖子中,笔者已对理想汽车VLM和VLA方案的框架进行了全面介绍,但对于其中的前沿技术仅做了初步探讨,未进行更深入的剖析。因此,笔者计划继续以系列文章的形式,介绍其中涉及的相关前沿技术。
首先,将介绍MindVLA中采用的“MoE + Sparse Attention”高效结构。
MoE + Sparse Attention高效结构
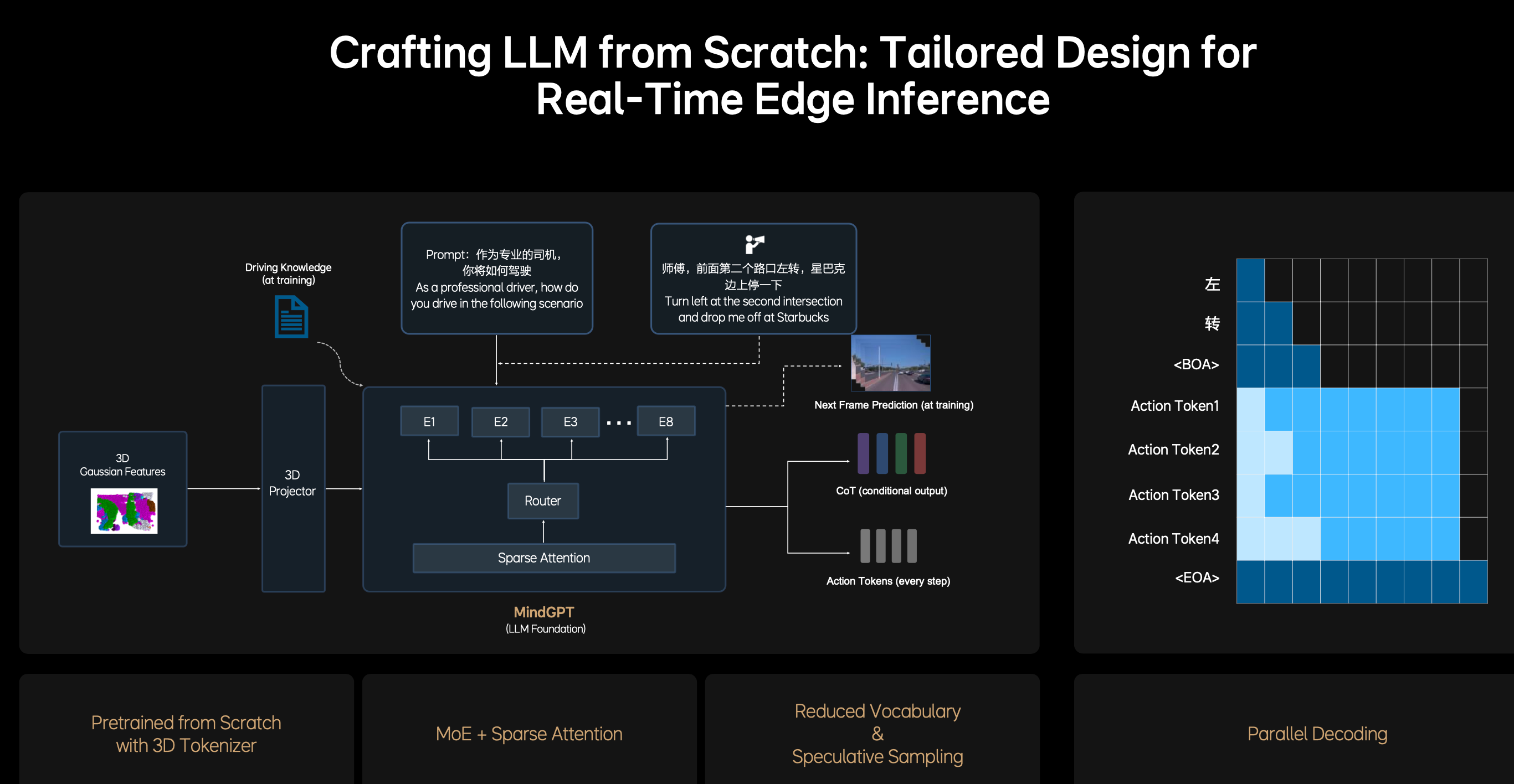
由上图可以看到,MindGPT使用混合专家(MoE)架构(有E1-E8个专家),由Router动态选择激活部分专家(而非全部),只在需要时调用相关子模型。稀疏注意力(Sparse Attention)则限制注意力机制的复杂度,只关注关键输入部分(如相关物体或动作),而不是全局计算。在这张图中,它的实现过程是:
每一层的 token 并不全互相注意,而是:
- 利用 Router 分配 token 给不同的 expert
每个 expert 内部只在局部或关键 token 上建立注意力连接
Sparse Attention
传统 transformer 的全连接注意力复杂度为 $O(n^2)$,对于高维空间场景(例如 3D Token 很多)会显著拖慢速度、增加计算。
稀疏注意力的核心目标是:
减少 token-to-token 的注意力连接(只对一部分 token 建立 attention)
降低计算复杂度,同时保持关键 token 的交互质量
那么它是如何实现目标的呢?下面将结合Sparse Transformer代码进行介绍。
$$O(n^2)$$降低为$$O(n\sqrt n)$$.
Sparse Attention 图结构解析
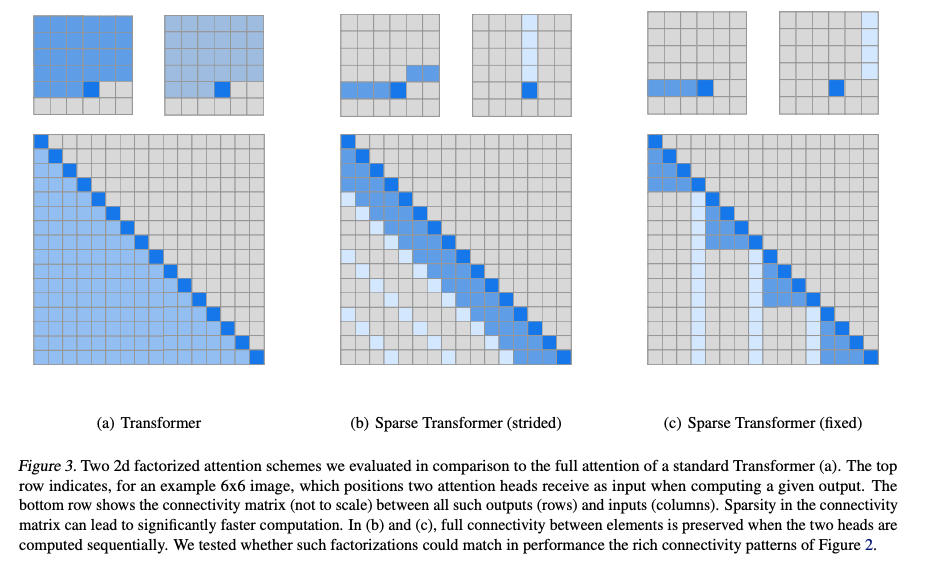
Strided attention(跳跃连接)
每个 token 关注步长为 s 的若干 token,例如:
token 8 会关注 0, 2, 4, 6 这些步长为 2 的 token。
Local attention(局部窗口)
每个 token 也关注自己附近的窗口内 token,比如前后 2 个:
组合结构
这种结构可以保证每个 token 都能快速传播到远端(通过跳跃),并同时保留局部建模能力。
代码实现解析
由于 OpenAI Sparse Transformer 没开源,这里参考了其思想的一个流行实现:[OpenNMT-py 或 custom PyTorch 实现],也可参考 Reformer 等模型实现方式。
稀疏注意力 mask 构造(关键)
这个 mask 会用于注意力权重:
应用在 Attention 模块
核心 attention 模块不变,只是加了 mask:
这样就可以在不修改 Transformer 主体结构的前提下使用稀疏连接。
以下是一个 9×9 attention matrix 的稀疏连接可视化(● 表示有连接):
复杂度分析
标准全连接 Self-Attention 的公式是:
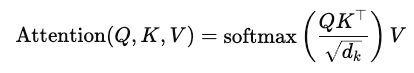
QK^T:产生 n×n 的权重矩阵 → 计算复杂度是:O(n^2*d);
Softmax ()V : O(n^2*d);
整体复杂度为:O(n^2*d,这意味着当序列变长时(如 n=8192),计算量和内存都会剧增。
MoE
MoE(专家混合体)是神经网络的一种架构模式,该模式将一个层或操作(例如线性层、多层感知机或注意力投影)的计算拆分为多个“专家”子网络。这些子网络各自独立地进行计算,其计算结果会被整合,以生成MoE层的最终输出。MoE架构可分为密集型和稀疏型,前者意味着在处理每个输入时都会启用所有专家,后者则表示每个输入仅使用部分专家。因此,MoE架构具备以下优势:
提升计算效率
在不显著增加推理成本的前提下,扩大模型容量(参数量)
这些优势与大模型的应用难题完美匹配,故而在该领域得到了较为广泛的应用。
MoE结构解析
以 PyTorch 为例,MoE 的核心组成部分通常包括以下几个模块:
Gate 模块(路由器)
负责为每个输入样本选择合适的专家(通常是 top-k 策略):
- scores 通常是通过一个线性层获得,表示输入样本对各个专家的偏好程度。
路由器可能带有噪声或正则(如 Switch Transformer 中的 noisy gating)。
Experts 模块(多个子网络)
每个专家是一个独立的神经网络(比如一个 MLP):
通常通过参数共享或并行执行多个专家。
Dispatcher(稀疏调度器)
根据 Gate 的输出,将输入路由给选中的专家,并收集输出:
这一步骤通常要做优化,否则容易成为性能瓶颈。
DeepSpeed-MoE 示例代码
MoE 类(deepspeed.moe.layer.MoE)
作为入口类,集成了路由器、专家、通信逻辑:
- ep_size: 每个专家组的并行数(Expert Parallelism)。
- k: top-k gating。
使用了通信优化如 All-to-All 分发样本。
构造函数 init
- hidden_size:输入和输出的维度;
- expert:作为子模块传入的专家网络(如 MLP);
- num_experts:专家总数;
- ep_size:专家并行维度;
- k:选用 top‑k 路由;
- capacity_factor 和 eval_capacity_factor:训练/评估期间专家最大处理 token 数比例;
- min_capacity:每个专家至少能接收的 token 数;
- use_residual:是否启用 Residual MoE 结构;
- noisy_gate_policy、drop_tokens、use_rts:路由噪声、token 丢弃、随机选择;
- enable_expert_tensor_parallelism:专家参数 tensor 切分;
- top2_2nd_expert_sampling:top‑2 第二专家采样策略。
这些选项为 MoE 的训练/推理提供了高度灵活性
前向函数 forward
forward函数定义如下:
forward函数的核心步骤可以总结为以下5部分:
TopKGate 类(deepspeed.moe.layers.gates)
实现 top-k 路由,并支持 noisy gate:
还包括负载均衡 loss。
Expert 通信部分
有 4 张 GPU,每张 GPU 上部署 2 个专家,共 8 个专家;
假设 batch 里的一部分 token 需要被路由到第 3 个专家(在 GPU 2 上),另一部分需要被送到第 6 个专家(在 GPU 4 上);
- 那么就必须跨 GPU 发送这些 token —— 所以通信效率就非常关键。
具体来说:
每个进程(GPU)上都有自己的输入 token;
每个进程根据路由器(Gate)的输出,将 token 分为 N 份,分别属于 N 个专家(也就是 N 个目标 GPU);
- 然后用 all_to_all 一次性把这 N 份数据分发到对应的 GPU 上;
- 所有专家完成前向计算后,再用 all_to_all 把结果发回。
通常输入需要 reshape 成:
之后经过两次 all_to_all:
- tokens 分发阶段:将 token 从本地发送到它所需的专家所在的 GPU;
- 结果收集阶段:将处理后的输出再收集回原始的 GPU。
参考链接
Applying Mixture of Experts in LLM Architectures
https://www.cnblogs.com/theseventhson/p/18247463
https://zhuanlan.zhihu.com/p/1888975857147691214

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)