
前言
在实际部署智能驾驶方案时,很多不同任务的模型会同时运行,在非正常情况下,模型按设计帧率运行时,每次运行花费的时间会不稳定。在这种情况下,我们要让模型按设计帧率运行,同时实时监测模型推理耗时和带宽使用情况,分析模型耗时不稳定时带宽占了多少。
针对以上情况,本帖将介绍以下内容:
对 hrt_model_exec 工具进行修改,让它能让单个模型按设计帧率运行指定的帧数,还能计算每帧推理耗时和系统时间戳;
运行修改后的 hrt_model_exec 工具和系统软件里的带宽检测工具 hrut_ddr,分析日志,查看模型耗时和带宽的变化情况。
通过示例说明工具的使用和数据分析方法。
hrt_model_exec 魔改方法
通过--perf_fps实现模型在单核单线程下按照设计帧率运行;
通过--frame_count 控制按照设计帧率推理的总帧数;
log中输出系统时间戳、当前推理帧数,推理Latency。
代码修改
main.cpp
parse_util.h
log_util.cpp
function_util.cpp(重点)
修改完代码后进行编译:
使用的时候将上述文件夹传输到板端即可。
参考命令
输出log如下所示:
hrut_ddr 带宽监测工具
hrut_ddr获取请联系地平线支持人员。
示例说明
本节将以一个简单的示例,阐述如何分析设计帧率推理模型的耗时与带宽。通过示例能直观了解其实际运行的用时和带宽情况,下面将详细说明分析的具体步骤。
步骤1 选取模型
智驾方案中一般有很多个模型,建议在实验中选取设计带宽占用比较大的模型,其中设计带宽的计算公式为:
设计带宽=每帧的ddr占用*设计带宽
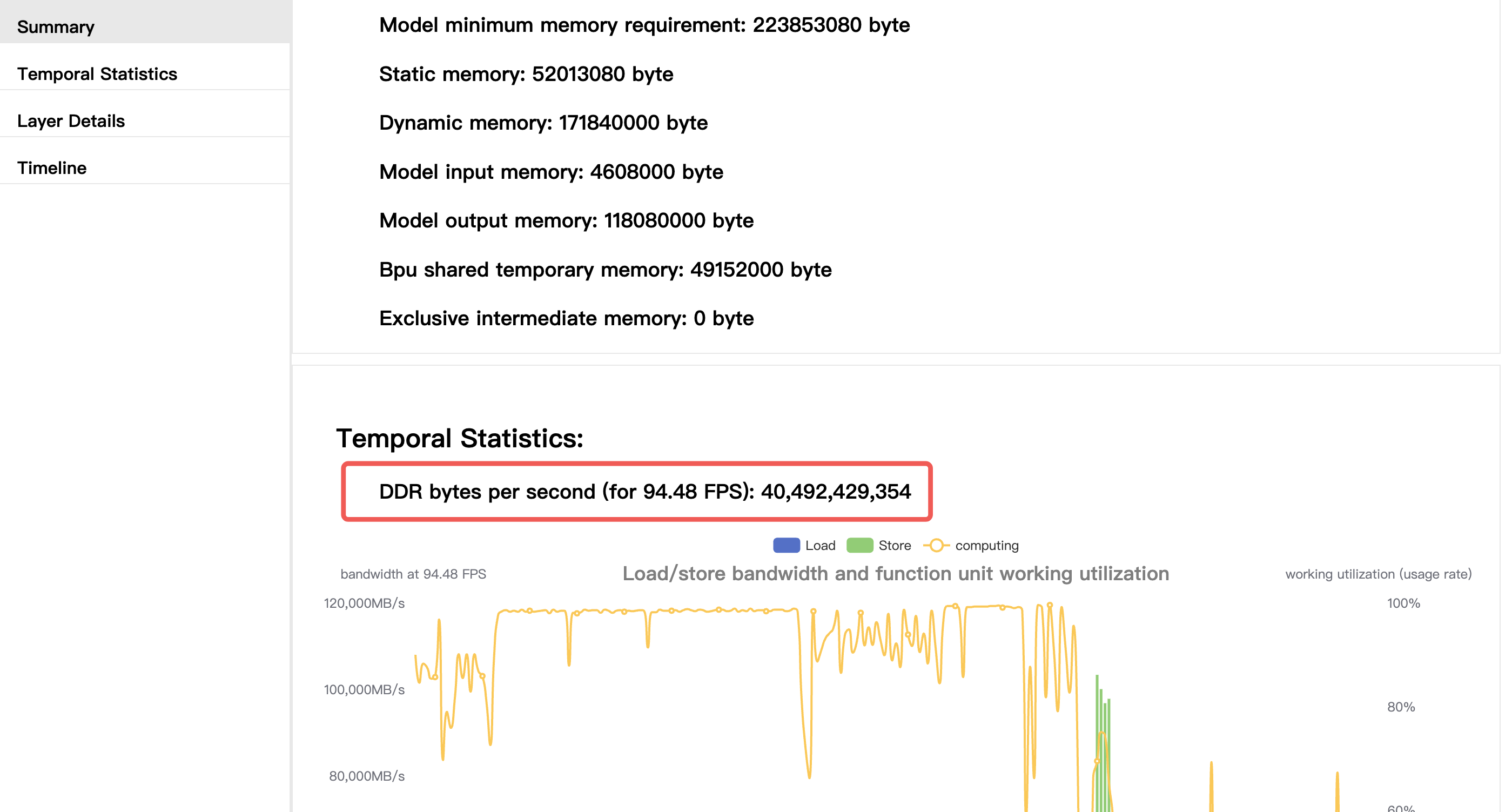
本帖的示例中选取了4个设计带宽比较大的模型model1~model4。
步骤2 模型推理和带宽监测
首先在板端运行hrut_ddr工具,参考命令如下:
然后在板端打开4个终端按照设计帧率分别推理这4个hbm模型:
如果需要将模型运行在不同的BPU core上可以配置core_id参数。
步骤3 数据分析
耗时带宽总体趋势图
将4个模型的耗时带宽变化集成在同一个图像上,由此观察变化趋势,如下所示:
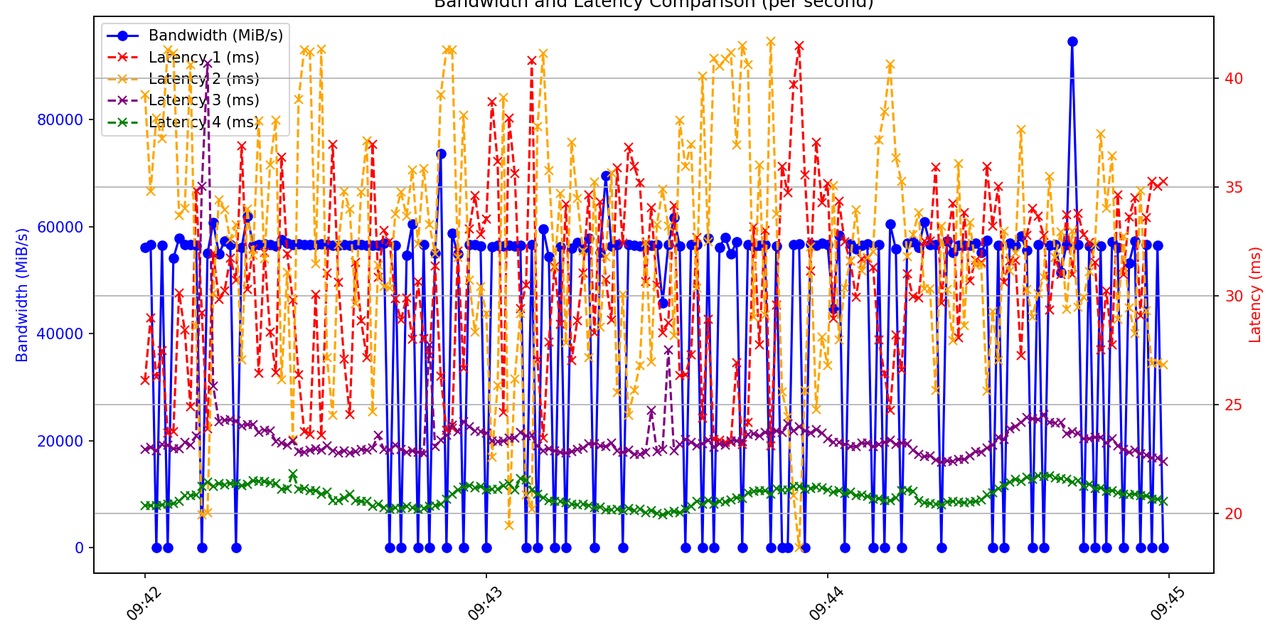
这里提供绘图的脚本,此脚本可以实现以下功能:
指定绘图的时间段,hrut_ddr和hrt_model_exec均有系统时间戳;
计算每秒钟的平均耗时和带宽占用;
将多个模型的耗时和带宽集成在同一张图上。
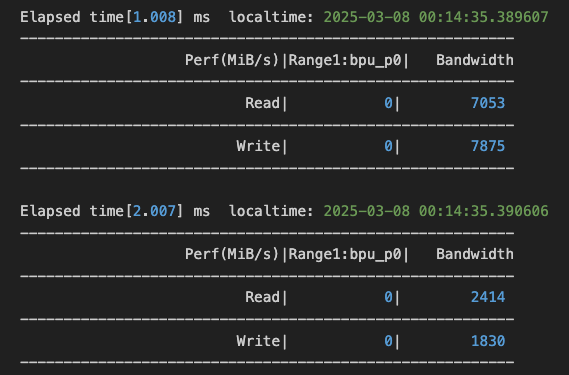
峰值带宽获取
根据hrut_ddr工具的log(如下所示),获取BPU带宽占用(Range1:bpu_p0列)和系统带宽占用(Bandwidth列)Read+Write 最大的20个值和对应的时间戳。
参考代码如下所示:
这样,我们就完成了延迟和带宽的数据获取和分析,后续笔者将分享如何根据获取的数据进行调优。
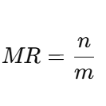

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)