
写在前面 && 笔者理解
端到端在当下可谓是炙手可热,它将感知和规划集成到一个统一的、完全可微的网络中。不过,因为物理世界的复杂性和规划意图的不确定性,基于对物理场景的整体理解,也就是空间、语义和时间信息的理解,能够进行多模态运动规划,也是一个比较有挑战性的工作。
论文链接:https://arxiv.org/pdf/2507.00603v1
作者的主要贡献总结如下:
受人类驾驶员决策过程的启发,作者提出了一个意图感知的潜在世界模型,创新性地使用世界模型在不同意图下生成和评估多模态轨迹。
为了增强世界模型对物理世界的理解而不依赖感知标注,作者设计了一个新颖的驾驶世界编码模块,该模块利用视觉基础模型的先验知识来提取驾驶环境的物理潜在表示。
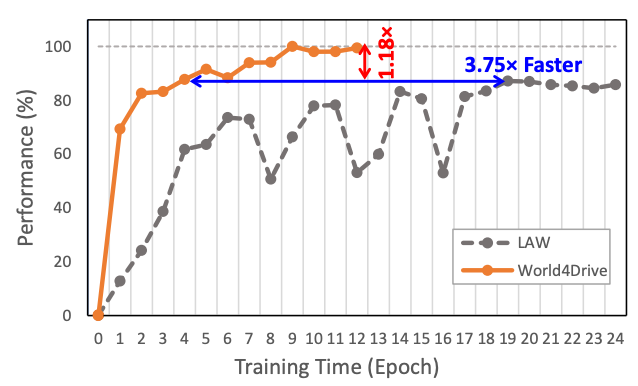
作者的方法在 nuScenes 和 NavSim 基准测试中实现了无需感知标注的端到端规划性能,并显著加快了收敛速度。
相关工作
端到端自动驾驶
自动驾驶世界模型
自动驾驶中的世界模型主要目的是预测在不同动作下场景的演变。这些模型包括基于图像的视频生成、基于点云和占用网格等表示的 3D 世界模型,以及基于潜在特征的未来世界生成。基于图像的视频生成包括使用扩散模型的驾驶视频方法,如 DriveDreamer、Vista 和 Drive-WM,以及基于自回归模型的驾驶视频生成方法,如 DriveWorld 和 GAIA。3D 世界模型包括基于点云的世界模型和基于占用的世界模型。这些模型在 3D 空间中构建模型,以更好地捕捉 3D 场景的动态变化。最近,VaVAM 和 LAW 等方法利用视频生成技术,通过自监督学习来学习场景表示,消除了对感知标注的依赖。特别是,LAW 提出了一种潜在世界模型,通过自监督学习预测单一未来场景潜在特征,实现了端到端规划的最先进性能。然而,从原始图像中构建单模态潜在特征往往难以捕捉空间 - 语义场景信息和多模态驾驶意图的不确定性,导致性能欠佳。
模型及方法
驾驶世界编码
作者设计的模型见图2所示,在驾驶世界编码模块中,作者引入了:
物理潜在编码器(Physical Latent Encoder):利用视觉语言模型和度量深度估计模型提取具有空间、语义和时间上下文感知的世界潜在表征。
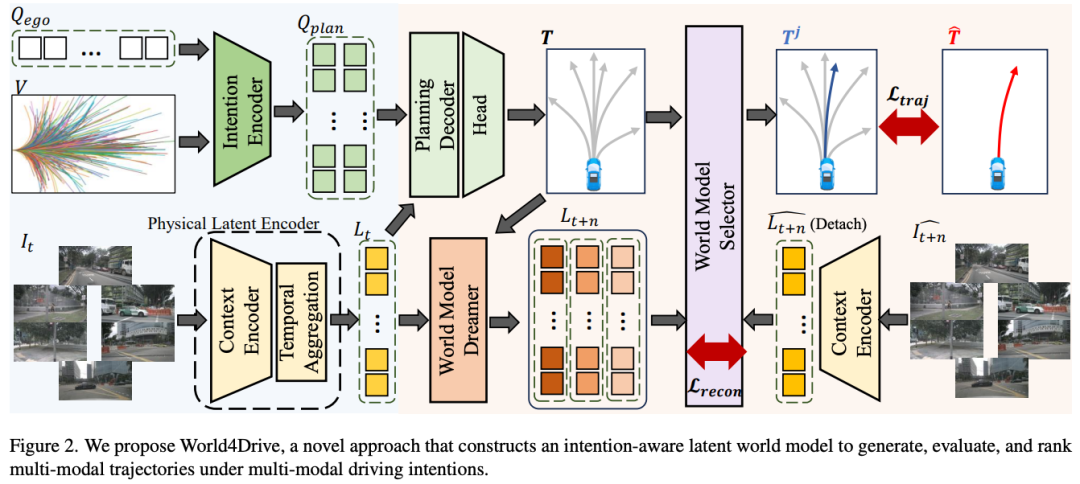
意图编码器
给定随机初始化的自我查询(ego query) 和轨迹词汇表 输入,作者首先在 的端点上采用 k-means 聚类算法获得意图点 。其中, 表示轨迹词汇表中的轨迹数量,3 表示三种指令类型(例如左转、右转、直行), 表示每种指令类型的意图数量, 表示每条轨迹中的路径点数量。然后,作者获得带有正弦位置编码的意图查询 。最后,作者利用一个自注意力层获得意图感知的多模态规划查询 。形式化表示为:
默认设置 ,。
物理世界潜在编码模块
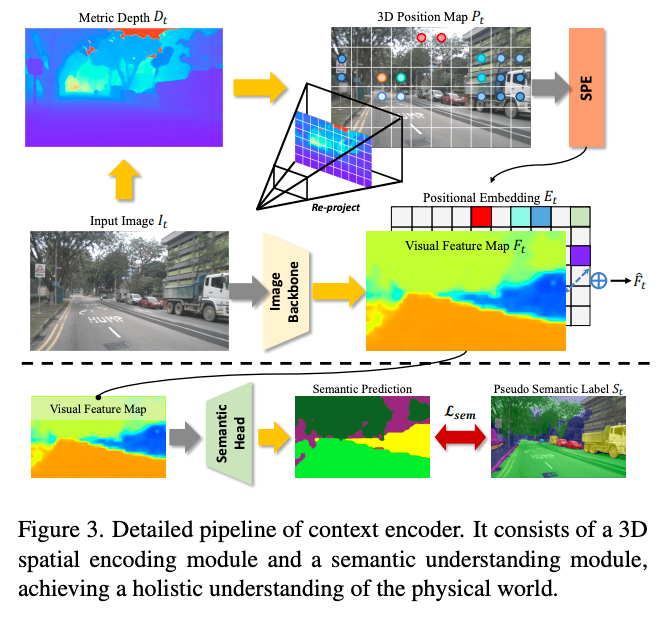
上下文编码器
给定时间步t的多视角图像输入 ,作者首先通过图像骨干网络提取对应图像特征 (D为特征维度,M代表相机视角数量)。先前工作LAW直接将相机特征作为世界潜在表征,缺乏对驾驶场景的空间和语义理解。为解决这个问题,作者通过开放词汇语义监督和3D几何感知位置编码引入空间-语义先验。
作者采用视觉语言模型Grouded-SAM生成伪语义标签。给定目标物体提示词,通过Grouded-SAM模型获得2D边界框及对应语义掩码 :
仅保留高置信度标签以减少错误标注。最终通过交叉熵损失 增强潜在表征的语义理解能力。
该组件旨在为模型提供物理世界中的精确位置信息。受PETR启发,作者通过生成3D网格为每个像素提供不同的3D位置编码。不同的是,作者为每个像素提供尺度感知深度来表示3D空间,为端到端规划提供精准空间理解。具体实现:
使用度量深度模型估计多视角深度图
通过深度图和相机内参矩阵,获得每个像素在自车坐标系中的3D位置
生成3D位置图
使用正弦位置编码处理3D坐标,通过可学习MLP获得位置嵌入 :
其中SPE(·)表示正弦位置编码。最终将位置嵌入 与图像特征 相加,得到语义-空间感知的视觉特征 。
时序聚合模块
不同于前人工作使用随机初始化查询获取潜在表征,作者通过时序聚合模块获得富含时序上下文的潜在表征。具体保留前一时刻 的视觉特征 ,通过交叉注意力机制将历史信息聚合到当前视觉特征中,得到世界潜在表征 :
该模块通过融合空间、语义和时序信息,使世界潜在表征能够全面理解动态驾驶环境——这对"想象未来世界"至关重要。
基于意图感知世界模型的规划
根据多模态驾驶意图预测未来世界的潜在表征
通过世界模型选择器对多模态规划轨迹进行评分。
意图感知世界模型预测器
给定意图感知的多模态规划查询 ,首先通过交叉注意力层将场景上下文聚合到 中,再通过MLP层生成多模态轨迹 :
最后通过动作编码器(MLP层)获取意图感知的动作令牌 (K为意图数量)。
作者的目标是预测遵循不同驾驶意图动作对应的未来世界潜在状态 (n为时间间隔)。与先前工作不同,作者:
沿通道维度拼接动作令牌A与世界潜在表征L
随机初始化可学习查询
采用多层交叉注意力作为预测器:
默认设置 。
世界模型选择器
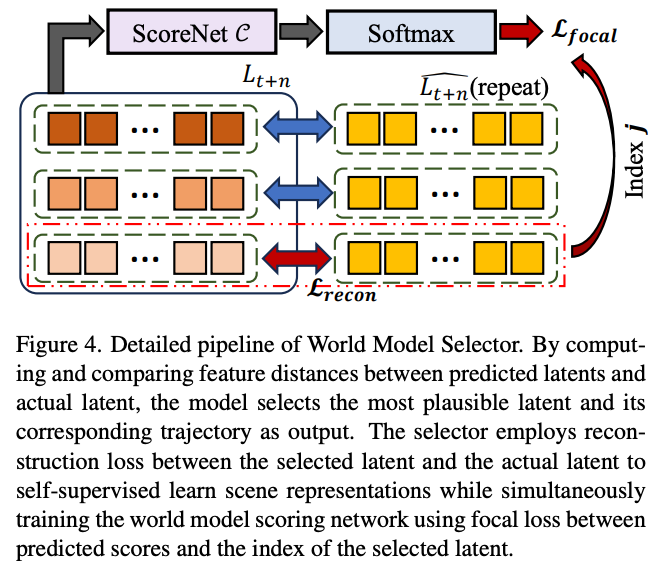
具体流程:
给定预测的意图感知未来潜在表征 和真实未来潜在表征
计算每个模态的预测潜在表征与真实潜在表征间的特征距离
选择距离最小的模态作为最终选定模态(假设其索引为j)
对应潜在距离作为重构损失 用于优化
对应轨迹 作为最终规划轨迹
同时,作者采用分类网络作为ScoreNet ,预测K个模态对应的分数 :
使用分数S与选定模态索引j之间的焦点损失优化世界模型评分网络。
关键说明:
- 推理阶段直接选择世界模型最高分对应的轨迹作为最终输出
采用MSE损失计算潜在距离
训练损失
遵循先前工作,作者应用 损失 ,用专家轨迹 指导最终规划轨迹 。World4Drive 是端到端可训练的。因此,端到端训练的最终损失为:
默认设置 。
实验及结论
基准测试
开环 nuScenes 基准测试
作者采用位移误差(L2)和碰撞率(CR)作为评估指标来评估预测轨迹。
闭环 NavSim 基准测试
模型性能通过闭环 PDM 得分(PDMS)进行评估,这些得分基于五个关键因素计算得出:无责任碰撞(NC)、可行驶区域合规性(DAC)、碰撞前时间(TTC)、舒适性(Comf.)和自身进度(EP)。
主要结果
如表 1 所示,作者将作者提出的框架与几种最先进(SOTA)的方法进行了比较。表格中蓝底方法需要手动感知标注,而红底方法在训练和推理过程中不需要手动感知标注。World4Drive 在无需感知标注的方法中实现了最先进的性能,与基线相比,L2 误差降低了 18.0%,碰撞率降低了 46.7%。此外,World4Drive 在所有方法中实现了最低的碰撞率。与基于感知的最先进的方法 LAW 相比,作者的方法在 L2 误差上仅适度增加了不到 2%,同时显著提高了安全指标。
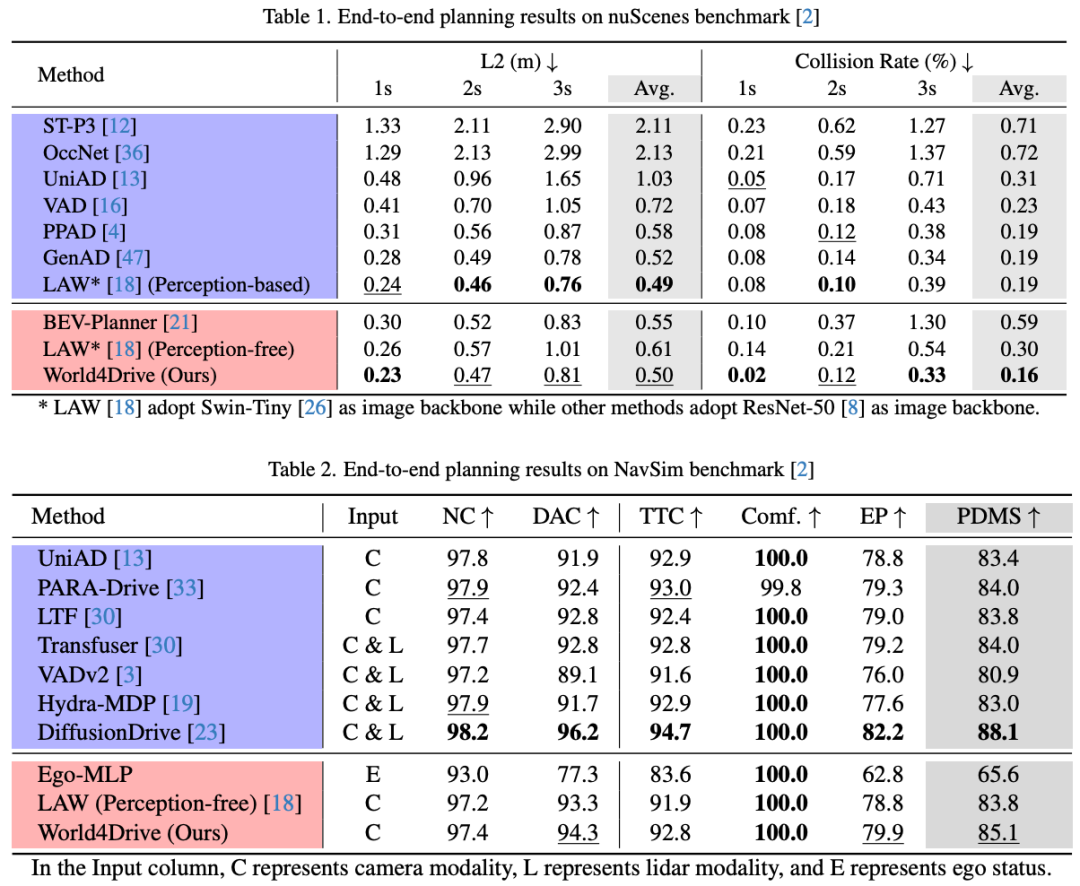
如表 2 所示,World4Drive 在闭环指标 PDMS 上也实现了具有竞争力的性能。与基线相比,作者的方法在碰撞前时间(TTC)和可行驶区域合规性(DAC)指标上显示出显著改进。这些指标专门评估自动驾驶车辆的空间感知和对可行驶区域的理解。结果表明,整合视觉基础模型先验显著增强了模型对物理世界的综合理解。此外,作者的闭环指标超越了其他需要感知标注的方法,除了 DiffusionDrive。
消融研究
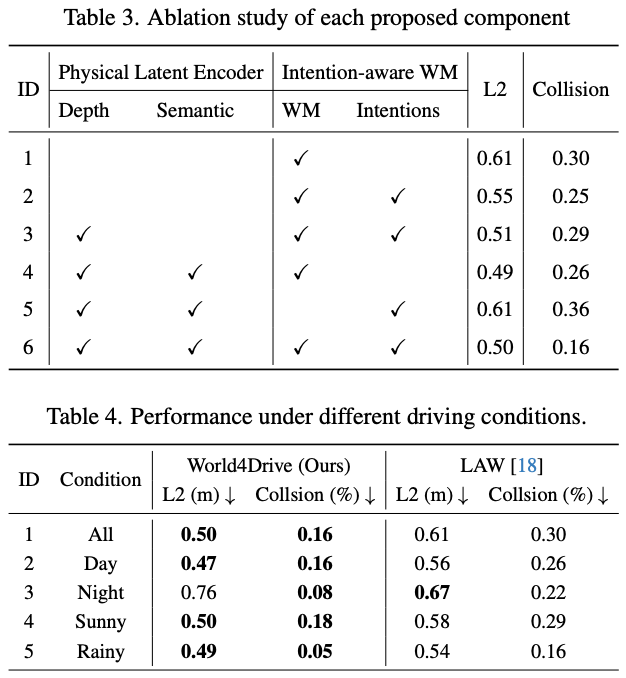
各个组件的有效性
不同驾驶条件下的性能
作者分析了在不同驾驶条件下的规划性能,包括不同的天气条件、照明设置和驾驶操作。按照官方的 nuScenes 场景描述,作者将天气分为晴天或雨天,照明分为白天或夜晚,驾驶操作分为左转、直行或右转。表 4 对作者的方法与基线 LAW 在不同天气和照明条件下的性能进行了比较分析。作者的方法在几乎所有环境场景中都始终优于 LAW。值得注意的是,与 LAW 相比,在具有挑战性的夜间和雨天条件下,作者的方法分别将碰撞率降低了 63.7% 和 68.8%。这一显著改进归因于整合了来自视觉基础模型的先验,使作者的系统能够理解更高维度的物理环境空间和语义信息。因此,作者的方法对夜间和雨天天气条件中固有的光度不一致性表现出更强的鲁棒性,而这些条件通常会阻碍基线方法中潜在世界模型的时间自监督训练。
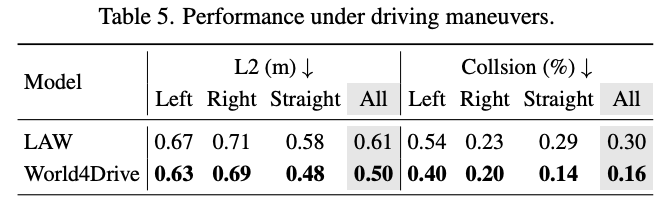
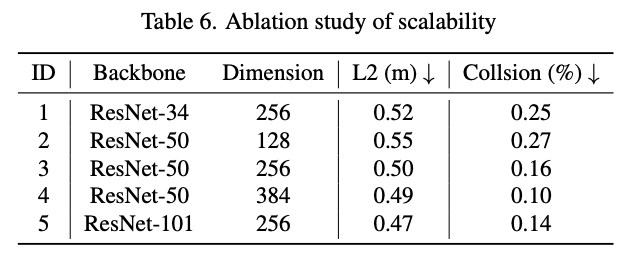
表 5 展示了作者的方法与 LAW 在不同驾驶操作下的规划性能比较。与 LAW 相比,作者的方法在各种驾驶操作中生成了显著更安全的规划轨迹。在不同驾驶条件下的卓越规划性能证明了作者的方法的有效性和鲁棒性。
World4Drive 的可扩展性
为了探索作者的方法的可扩展性,作者通过改变隐藏维度 D 的大小和图像主干网来进行实验。如表 6 所示,比较第 1、4 和 5 行,作者将图像主干网从 ResNet34 扩展到 ResNet50 和 ResNet101,而比较第 3、4 和 5 行,作者将隐藏维度的大小从 125 扩展到 256 和 384。消融结果表明,World4Drive 在图像主干网和隐藏维度方面都具有出色的可扩展性。
定性结果
在本节中,作者展示 World4Drive 在 nuScenes 基准测试中的可视化结果。定性结果如图 5 所示。可视化结果的上半部分表明,与 LAW 相比,World4Drive 在转向操作中规划的轨迹更安全。下半部分显示,世界模型选择器能够从多种驾驶意图中有效地选择最合理的轨迹。

结论
本文提出了 World4Drive,一个具有意图感知的物理潜在世界模型。World4Drive 提出了一个创新的框架,将驾驶意图与潜在世界模型相结合,创新性地利用潜在世界模型在不同的意图下生成、评估和选择多模态轨迹。具体来说,World4Drive 提出了一个物理世界潜在编码模块,整合了来自视觉基础模型的空间和语义先验,并聚合了时间信息。在 nuScenes 和 NavSim 基准测试上的广泛实验表明,World4Drive 对物理世界有着深刻而全面的理解,以及将驾驶意图与潜在世界模型紧密结合的有效性。
文章转载自公众号:自动驾驶之心
原文链接:https://mp.weixin.qq.com/s/zgNoQfzdU31Dd4RhfaDHjg

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)