
前言
新功能介绍
内存占用信息
新版 perf HTML 主页新增了模型运行时的内存占用详情,涵盖以下关键维度:
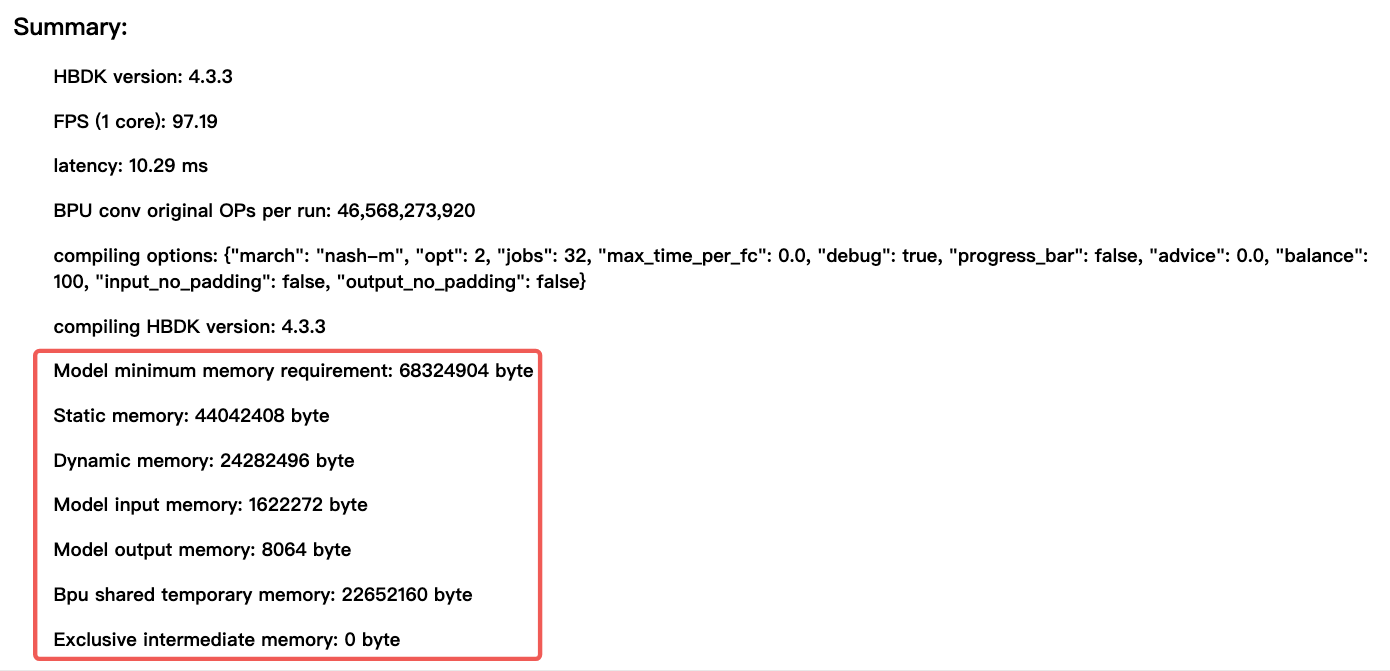
主要包括以下部分:
- input memory :模型输入数据的内存占用,反映接收输入所需的空间大小。
- output memory:模型输出结果的内存占用,直接影响结果生成效率。
- Bpu shared temporary memory & Exclusive intermediate memory:运行时内存
- dynamic memory:前四项内存之和,代表动态资源需求,即上图中1622272+8064+22652160+0=24282496
- static memory:hbm文件大小
- Model minimum memory requirement:dynamic memory+static memory
硬件占用Timeline
新增的 Timeline 功能通过时间序列图展示硬件操作耗时,横轴为时间(微秒),纵轴为操作类型(如 AAE、VAE、STORE 等)。关键应用包括:
TAE:张量加速单元,主要做conv、matmu计算;
VAE:向量加速单元,主要做逐点相加/乘计算;
AAE:偏专用单元的集合,包括 Pooling、Resizer、Warping 等;
Trans:数据搬运操作,包括transpose、reshape等;
LOAD/STORE:加载/存储数据;
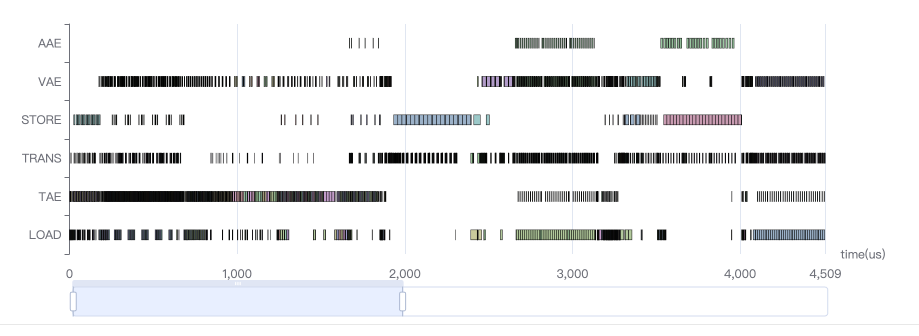
性能分析实例
首先确定是否存在带宽瓶颈
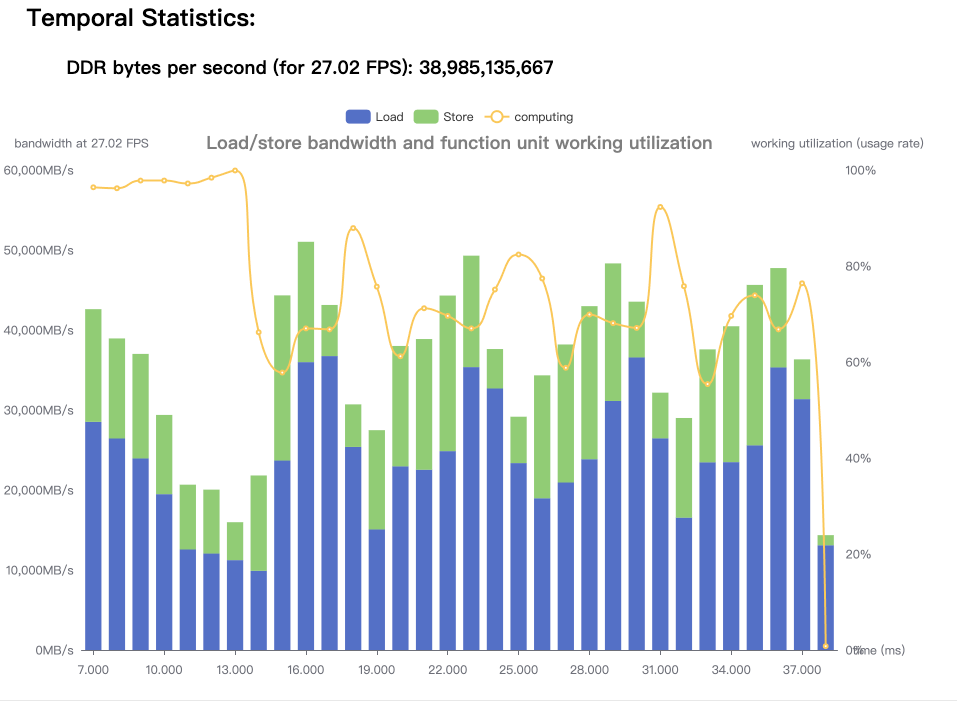
从上图看到,存在黄色的计算时间曲线低于Load+Store曲线的情况,所以模型中说存在带宽占用较高的算子的。
那么,如何查看这些算子呢?
查看占用时间较高的算子
hbm_perf的产出物中包括了json文件,我们可以使用这个json文件对性能做进一步的分析,比如每类算子的耗时,Top耗时的算子,预计统计模型中每一部分耗时的算子。
每类算子耗时
如下图是使用脚本统计的算子耗时,可以看到以下信息:
耗时比较高的是Matmul和conv算子;
matmul算子引起了带宽瓶颈,即ddr耗时(load+store)大大超过了计算耗时;
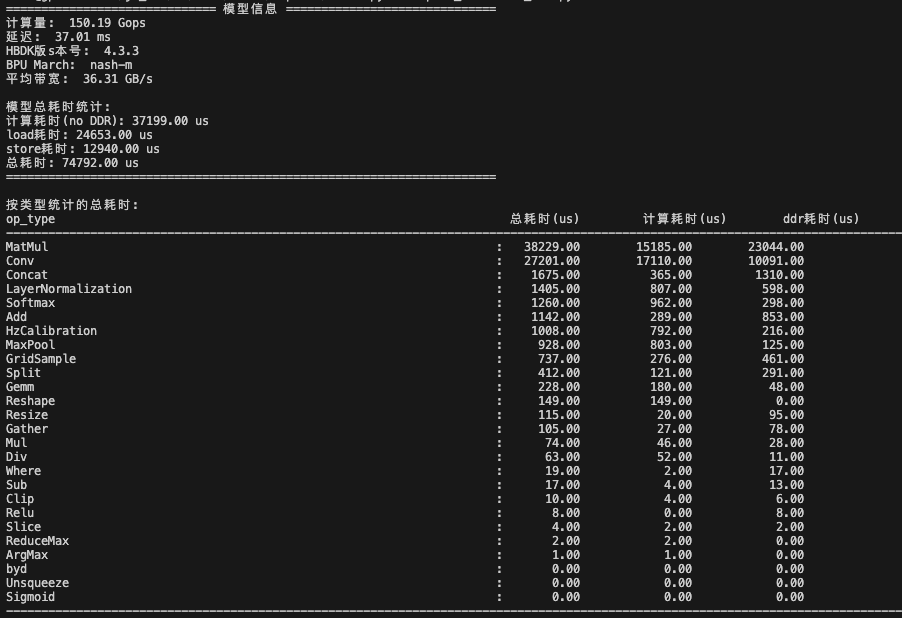
下面我们就着重看模型中的matmul算子。
Top 20算子耗时
在perf.jso的统计脚本中,增加了打印Top 20算子的耗时,即打印耗时最大的前20个算子,如下所示:

上图中,我们可以看到耗时最高的四个算子都是Matmul算子,此时我们需要结合layername到原始浮点onnx/quantized.bc中去查看这几个算子的属性。
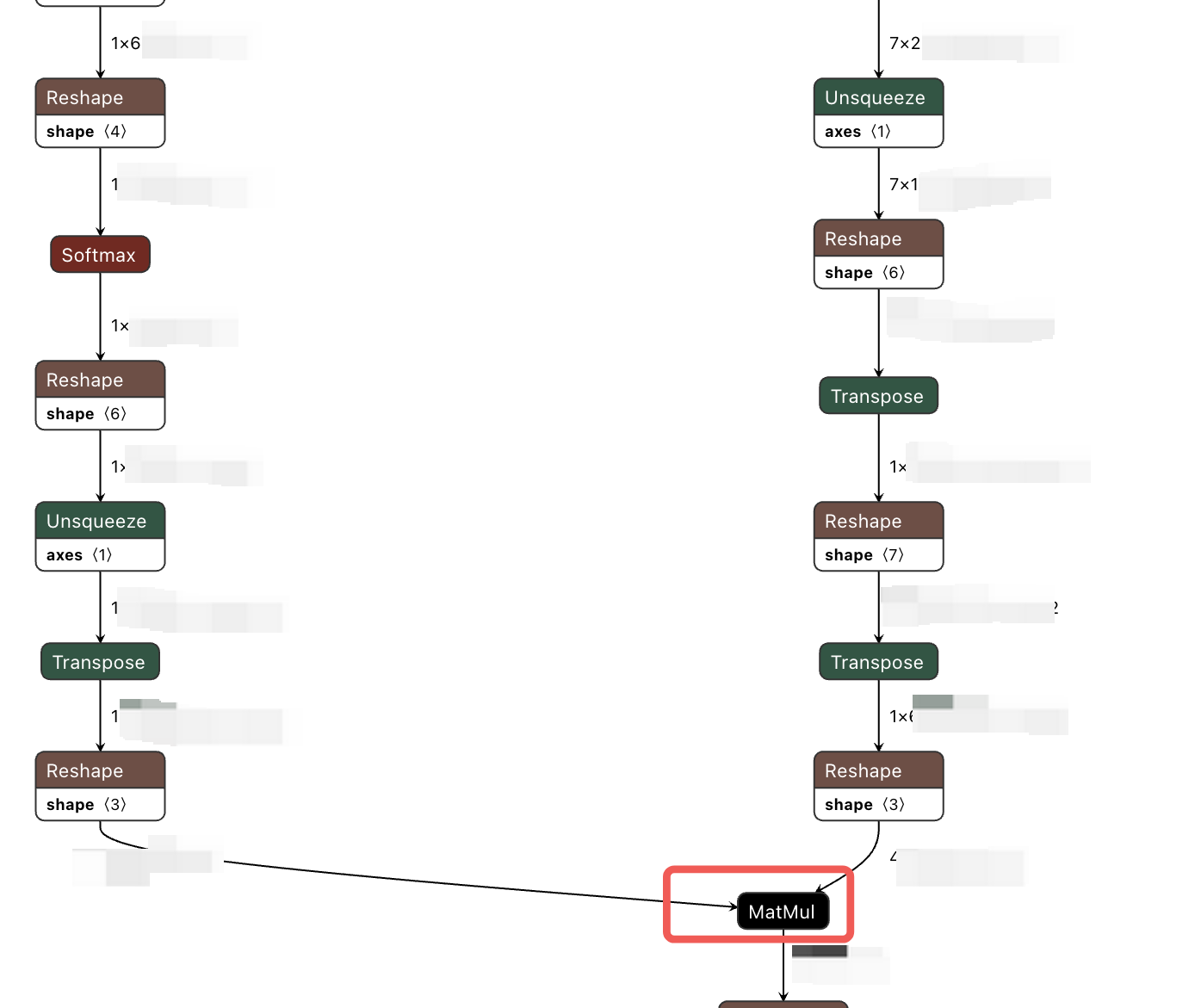
可以看到,这里matmul计算的前面有很多的数据搬运操作,这也是一个优化点,减少数据搬运操作可以显著降低带宽占用。
quantized.bc可视化的结构如下:
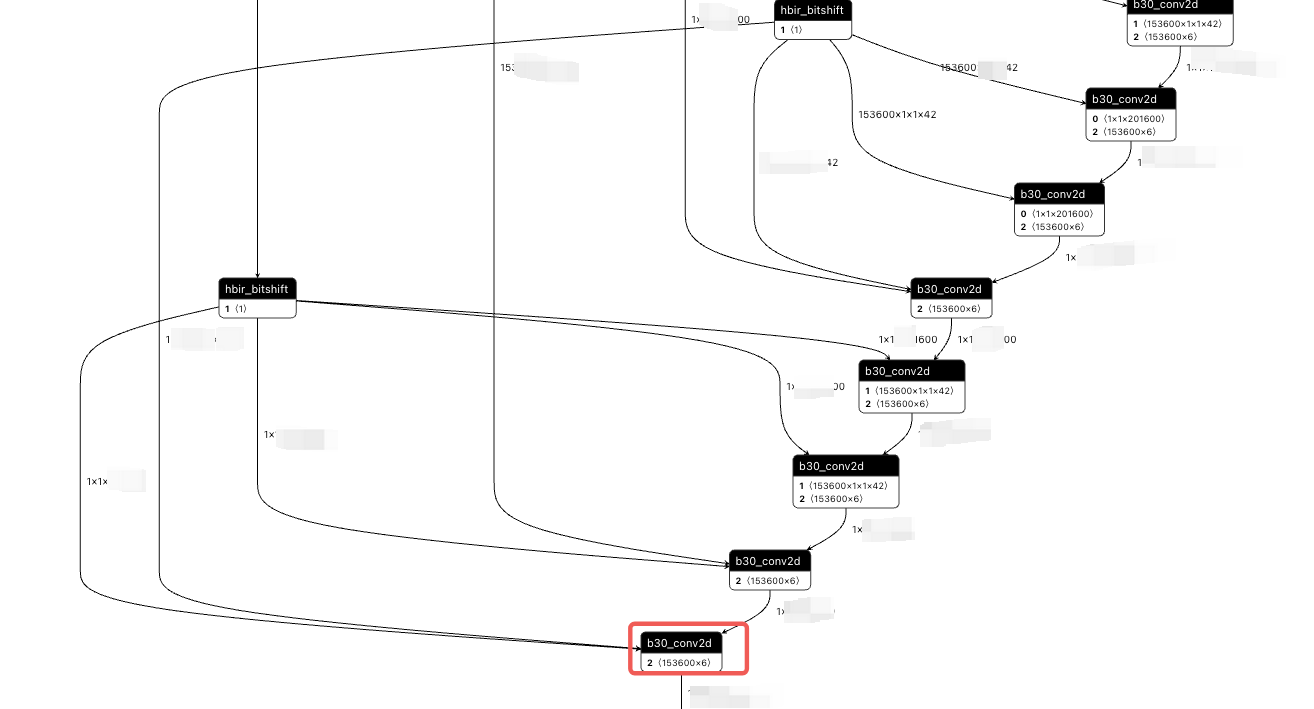
首先,可以看出这里的 matmul计算是int16的,由于数据超出的硬件的限制,所以工具进行了自动拆分,但是由于数据了实在是太大了,所以这里的matmul的耗时还是非常高。
所以,这里有两点建议:
在实际部署中,matmul并不一定需要int16精度,这里可以把matmul的输入/输出配置成int8量化;
如果matmul必须要保持int16量化精度,这里可以考虑将其等价替换为mul+ReduceSum计算;
附录
附录中提供了统计算子耗时的脚本,输入为perf.json文件,输出为:
每种算子的总耗时、计算耗时和ddr耗时,有利于了解模型中算子的耗时分布和带宽占用;
耗时排名前20的算子,这些算子是耗时的瓶颈,需要针对性分析。
'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
