
在大型语言模型(LLM)的推理过程中,KV Cache 是一项关键技术,它通过缓存中间计算结果显著提升了模型的运行效率。本文将深入解析 KV Cache 的工作原理、实现方式,并通过代码示例展示其在实际应用中的效果。
一、为什么需要 KV Cache?
在标准 Transformer 解码时,每次生成新 token 时:
- 需要 重新计算所有之前 token 的 K 和 V,并与当前 token 进行注意力计算。
- 计算复杂度是 O(n²)(对于长度为 n 的序列)。
- 只需计算 新 token 的 K 和 V,然后将其与缓存的值结合使用。
- 计算复杂度下降到 O(n)(每个 token 只与之前缓存的 token 计算注意力)。
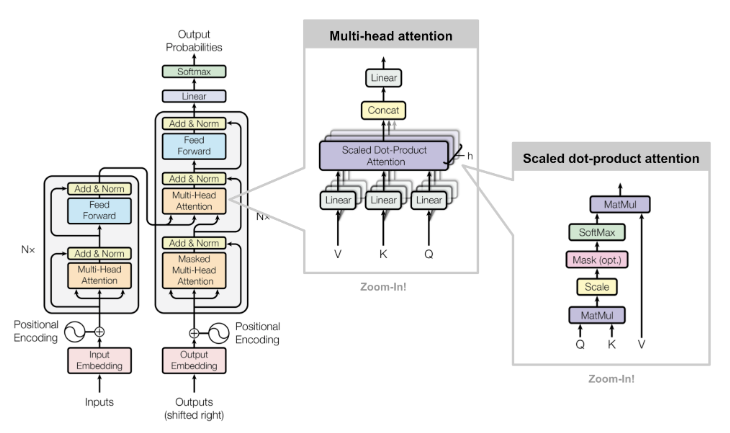
二、KV Cache 的工作原理
在生成第一个 token 时,模型计算并缓存所有输入 token 的 K 和 V 矩阵
生成后续 token 时,只需要计算新 token 的查询(Query)矩阵
将新的 Q 矩阵与缓存的 K、V 矩阵进行注意力计算,同时将新 token 的 K、V 追加到缓存中
这个过程可以用伪代码直观展示:
通过这种方式,每次新生成 token 时,只需计算新的 Q 矩阵并与历史 KV 矩阵进行注意力计算,将时间复杂度从 O (n²) 降低到 O (n),极大提升了长序列生成的效率。
下面,我们结合示意图进一步剖析一下KV Cache 部分的逻辑。
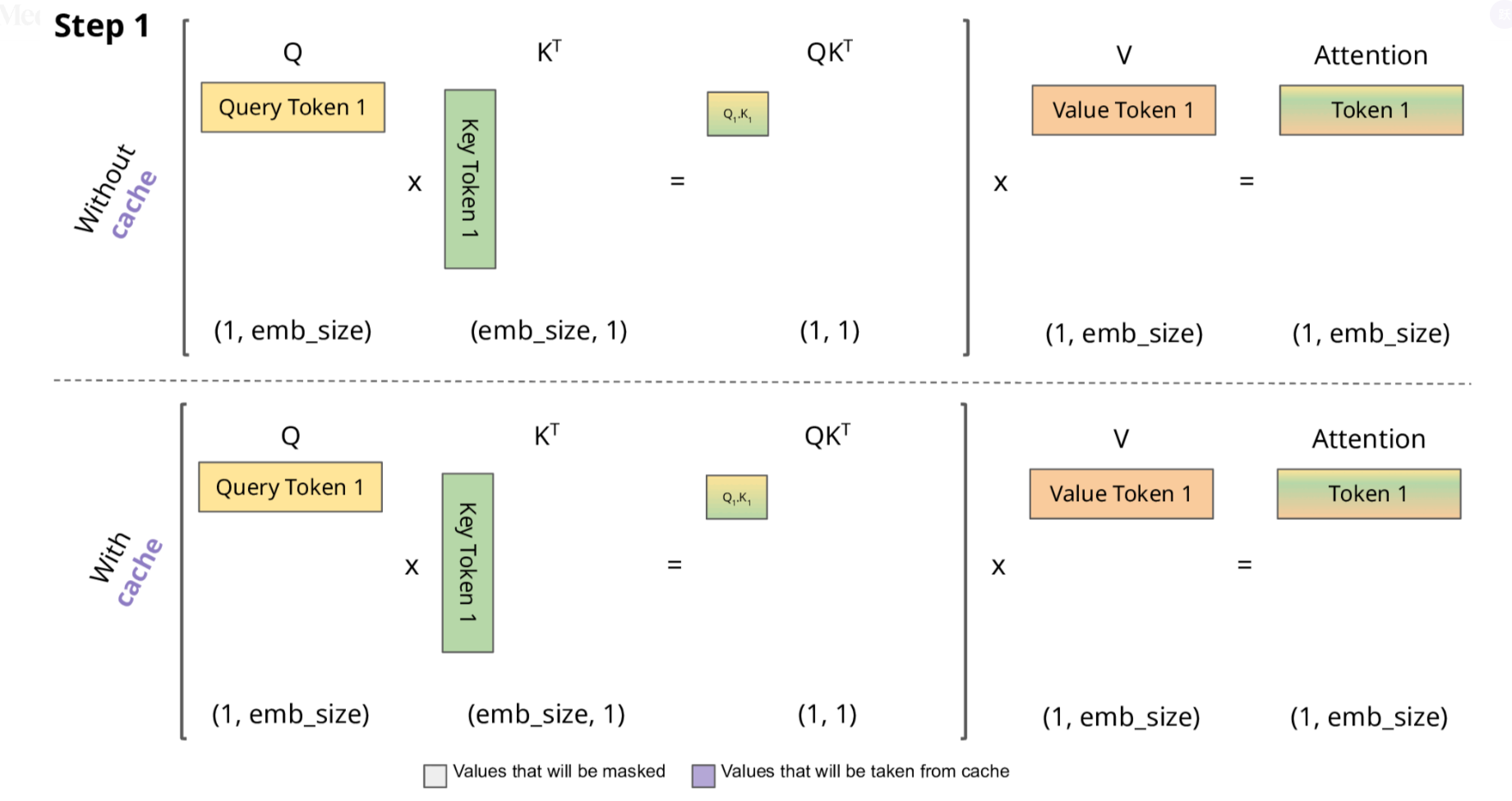
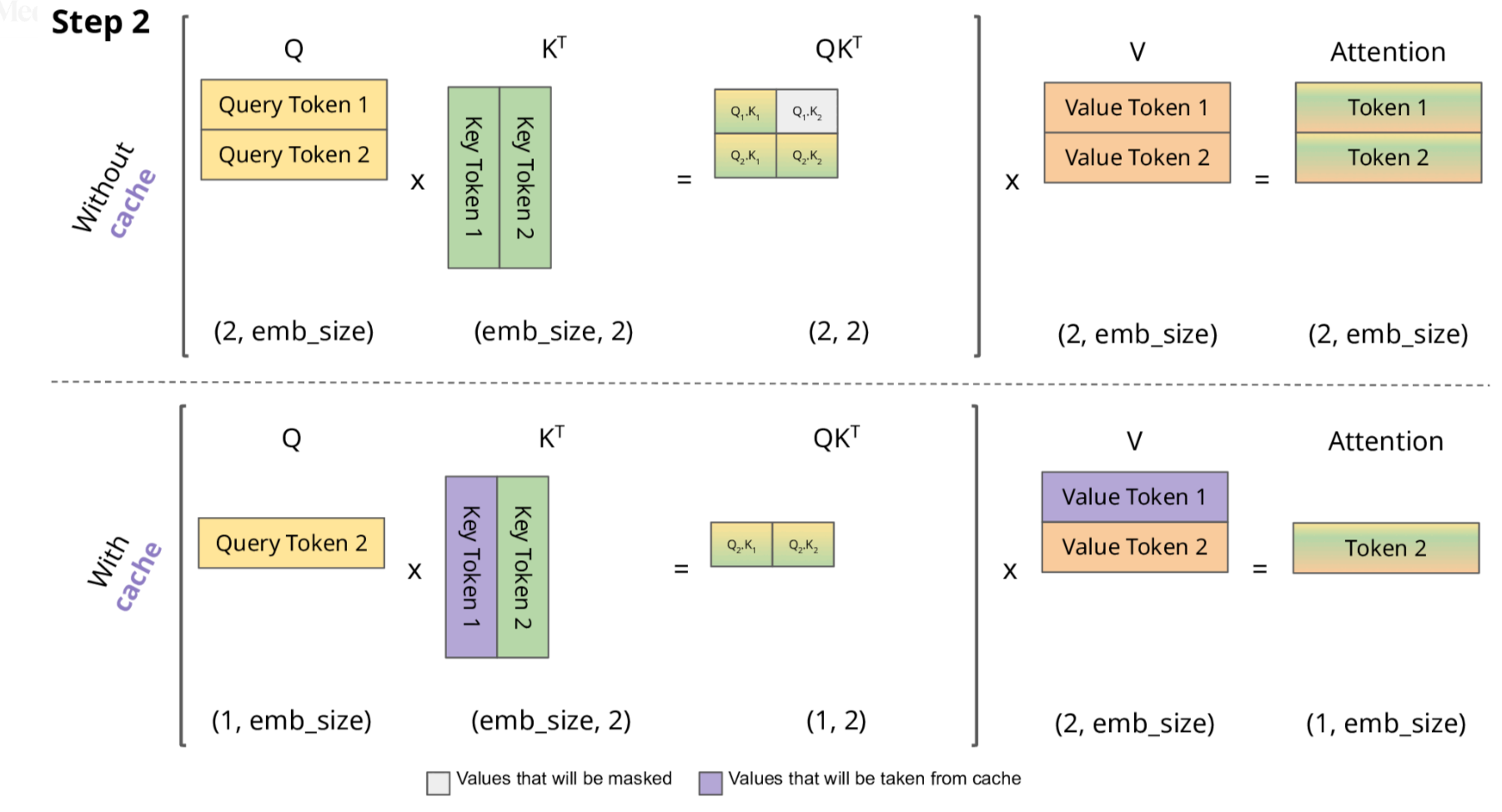
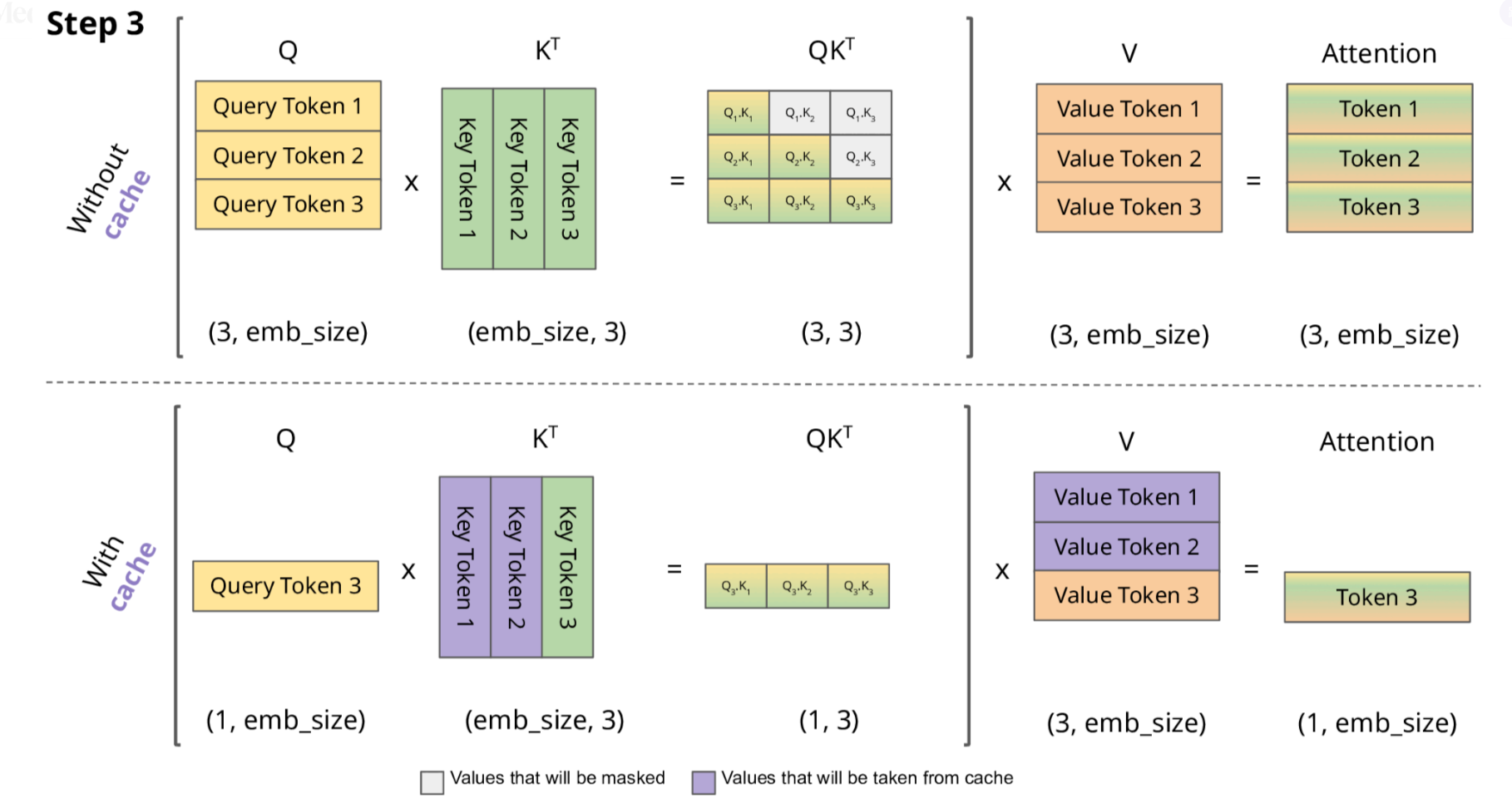
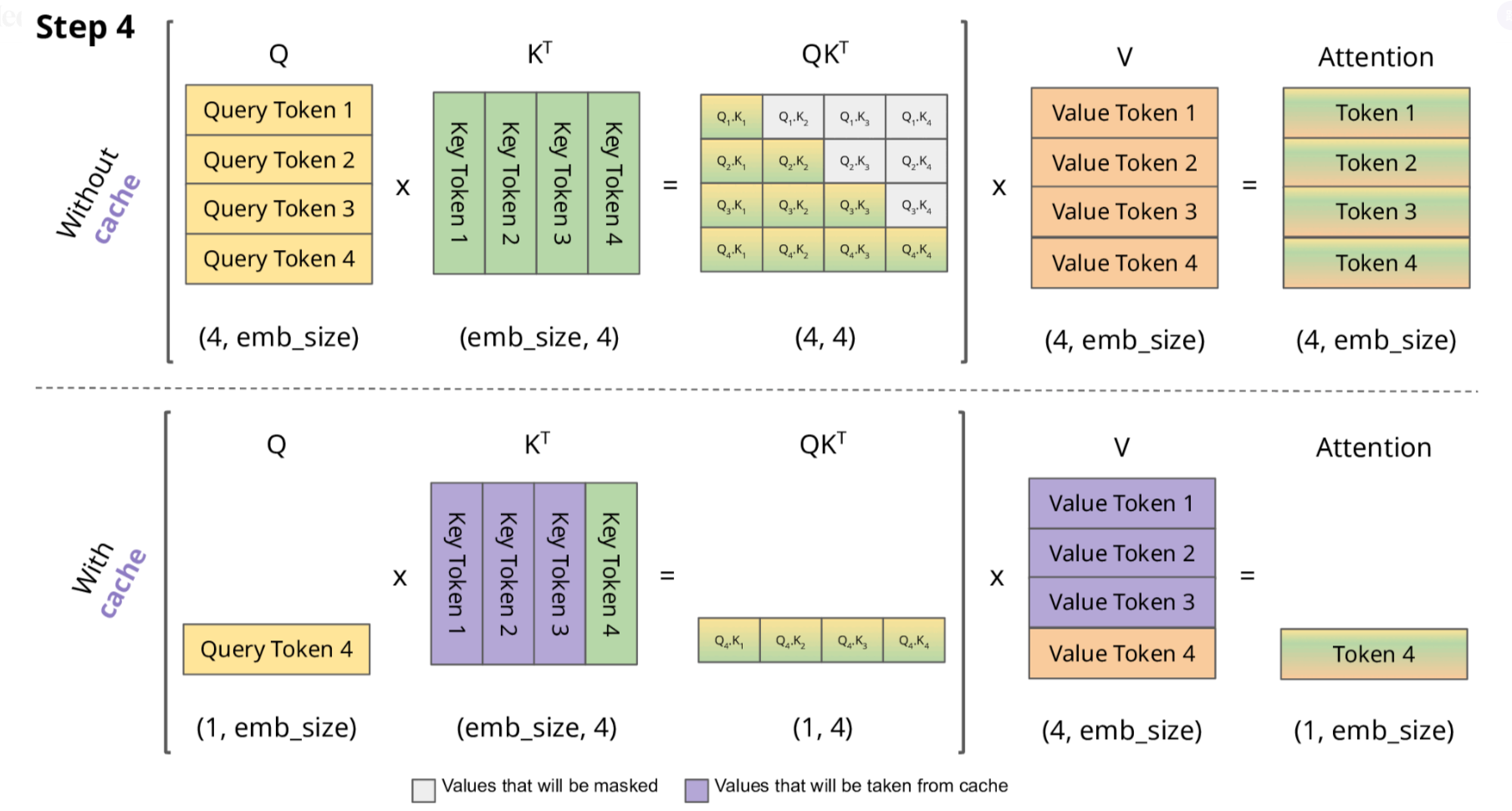
KV Cache 核心节约的时间有三大块:
前面 n-1 次的 Q 的计算,当然这块对于一次一个 token 的输出本来也没有用;
同理还有 Attention 计算时对角矩阵变为最后一行,和 b是同理的,这样 mask 矩阵也就没有什么用了;
前面 n-1 次的 K 和 V 的计算,也就是上图紫色部分,这部分是实打实被 Cache 过不需要再重新计算的部分。
这里还有个 softmax 的问题,softmax 原本就是针对同一个 query 的所有 key 的计算,所以并不受影响。
KV Cache 的技术细节
缓存结构
KV Cache 通常为每个注意力头维护独立的缓存,结构如下:
Key 缓存:形状为 [batch_size, num_heads, seq_len, head_dim]
Value 缓存:形状为 [batch_size, num_heads, seq_len, head_dim]
其中,seq_len 会随着生成过程动态增长,直到达到模型最大序列长度限制。
内存与速度的权衡
KV Cache 虽然提升了速度,但需要额外的内存存储缓存数据。以 GPT-3 175B 模型为例,每个 token 的 KV 缓存约占用 20KB 内存,当生成 1000 个 token 时,单个样本就需要约 20MB 内存。在批量处理时,内存消耗会线性增加。
实际应用中需要根据硬件条件在以下方面进行权衡:
最大缓存长度(影响能处理的序列长度)
批量大小(影响并发处理能力)
精度选择(FP16 比 FP32 节省一半内存)
滑动窗口机制
当处理超长序列时,一些模型(如 Llama 2)采用滑动窗口机制,只保留最近的 N 个 token 的 KV 缓存,以控制内存占用。这种机制在牺牲少量上下文信息的情况下,保证了模型能处理更长的对话。
四、代码实现解析
下面以 PyTorch 为例,展示 KV Cache 在自注意力计算中的实现方式。
基础自注意力实现(无缓存)
首先看一下标准的自注意力计算,没有缓存机制:
带 KV Cache 的自注意力实现
下面修改代码,加入 KV Cache 机制:
生成过程中的缓存使用
在文本生成时,我们可以这样使用带缓存的注意力机制:
五、KV Cache 的优化策略
在实际部署中,为了进一步提升 KV Cache 的效率,还会采用以下优化策略:
- 分页 KV Cache(Paged KV Cache):借鉴内存分页机制,将连续的 KV 缓存分割成固定大小的块,提高内存利用率,代表实现有 vLLM。
- 动态缓存管理:根据输入序列长度动态调整缓存大小,在批量处理时优化内存分配。
- 量化缓存:使用 INT8 或 INT4 等低精度格式存储 KV 缓存,在牺牲少量精度的情况下大幅减少内存占用。
- 选择性缓存:对于一些不重要的层或注意力头,选择性地不进行缓存,平衡速度和内存。
六、总结
KV Cache 通过缓存中间计算结果,有效解决了 Transformer 模型在生成式任务中的效率问题,是大模型能够实现实时交互的关键技术之一。理解 KV Cache 的工作原理和实现方式,对于优化大模型推理性能、解决实际部署中的挑战具有重要意义。
参考链接
https://zhuanlan.zhihu.com/p/670515231
https://zhuanlan.zhihu.com/p/714288577
https://zhuanlan.zhihu.com/p/715921106https://zhuanlan.zhihu.com/p/19489285169
https://medium.com/@joaolages/kv-caching-explained-276520203249

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)