
前言
大模型(参数规模通常数十亿至万亿级)在处理复杂任务时面临三大核心问题:
显式关联的局限性:传统 Multi-head Attention 依赖输入数据的显式特征(如文本中的词向量、图像中的像素特征)计算注意力,难以捕捉深层语义(如 “同义词替换”“上下文隐喻”)或抽象结构(如 “逻辑推理链”)。
数据效率与泛化瓶颈:大模型训练需海量数据,但在低资源语言、专业领域(如医学、法律)中,显式关联数据稀缺,导致模型泛化能力骤降。
多模态融合难点:跨模态任务(如图文生成、视频理解)中,不同模态的特征空间差异大(如文本的离散符号 vs 图像的连续像素),显式关联(如 “图像中的猫” 与文本 “猫”)之外的隐式关联(如 “图像风格” 与 “文本情感”)难以建模。
在前面的文章中,笔者已经讲解了LLM推理的关键技术-KV Cache(【手撕大模型】KVCache原理及代码解析),但是随着大模型功能的不断强化,其容量也在增加,当前的KVCache技术已经不能满足发展需要了,所以,各种针对于KVCache优化的技术应时而生。
优化KV cache的方法
参考https://zhuanlan.zhihu.com/p/16730036197
当前,业界针对KV Cache的优化方法可以总结为有四类:
共享KV:多个Head共享使用1组KV,将原来每个Head一个KV,变成1组Head一个KV,来压缩KV的存储。代表方法:GQA,MQA等。
窗口KV:针对长序列控制一个计算KV的窗口,KV cache只保存窗口内的结果(窗口长度远小于序列长度),超出窗口的KV会被丢弃,通过这种方法能减少KV的存储,当然也会损失一定的长文推理效果。代表方法:Longformer等。
量化压缩:基于量化的方法,通过更低的Bit位来保存KV,将单KV结果进一步压缩,代表方法:INT8/INT4等。
计算优化:通过优化计算过程,减少访存换入换出的次数,让更多计算在片上存储SRAM进行,以提升推理性能,代表方法:flashAttention等。
MQA &
MQA(多查询注意力)和 GQA(分组查询注意力)作为自注意力机制的优化版本,主要作用是加快推理进程、减少内存占用,同时努力维持模型原有的性能表现。
以 Llama 7B 模型为例,其隐藏层维度为 4096,这意味着每个 K、V 向量都包含 4096 个数据。若采用半精度浮点(float16)格式存储,单个 Transformer 模块中,单序列的 K、V 缓存空间就达到 4096×2×2=16KB。由于 Llama 2 包含 32 个 Transformer 模块,单个序列在整个模型中的缓存需求便为 16KB×32=512KB。
那么多序列的情况呢?倘若句子长度为 1024,缓存空间就会增至 512MB。目前英伟达性能顶尖的 H100 显卡,其 SRAM 缓存约为 50MB,A100 则为 40MB,显然难以满足需求。尽管可将数据存于 GPU 显存(DRAM),但会对性能产生影响。7B 规模的模型已是如此,175B 规模的模型面临的问题更严峻。
解决这一问题的思路可从硬件与软件两方面展开:
硬件层面,可借助 HBM(高带宽内存)提高数据读取速度;或摆脱冯・诺依曼架构的束缚,改变计算单元从内存读取数据的方式,转而以存储为核心,构建计算与存储一体化的 “存内计算” 模式,例如采用 “忆阻器” 技术。
软件层面则通过算法优化来解决,Llama 2 所采用的 GQA(分组查询注意力)便是其中一种方案。
下面将通过图示来展示 MQA、GQA 与传统 MHA(多头注意力)的差异:
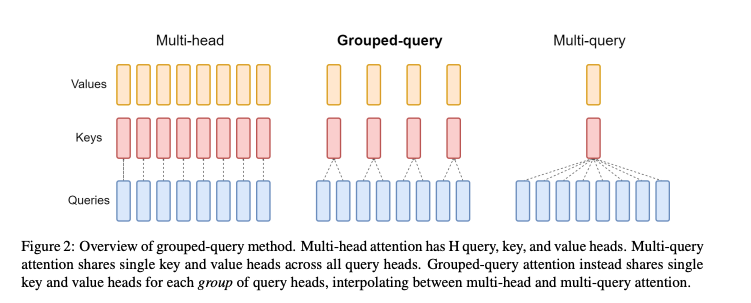
MQA
MQA的思路比较简单,详见上图,每一层的所有Head,共享同一个 KV 来计算Attention。相对于MHA的单个Token需要保存的KV数减少了n_h倍(head数量),即每一层共享使用一个 Q向量和一个 V向量。
效果方面,目前看来大部分任务的损失都比较有限,且MQA的支持者相信这部分损失可以通过进一步训练来弥补回。此外,注意到MQA由于共享了K、V,将会导致Attention的参数量减少了将近一半,而为了模型总参数量的不变,通常会相应地增大FFN/GLU的规模,这也能弥补一部分效果损失。
GQA
GQA是平衡了MQA和MHA的一种折中的方法,不是每个Head一个KV,也不是所有Head共享一个KV,而是对所有Head分组,比如分组数为 g ,那么每组: n_h/g个Head 共享一个KV。当 g=1 时,GQA就等价于MQA,当 g=n_h时, GQA就等价于MHA。
为了方便更清晰的理解GQA和MQA ,使用一个Token计算KV过程来进行演示:
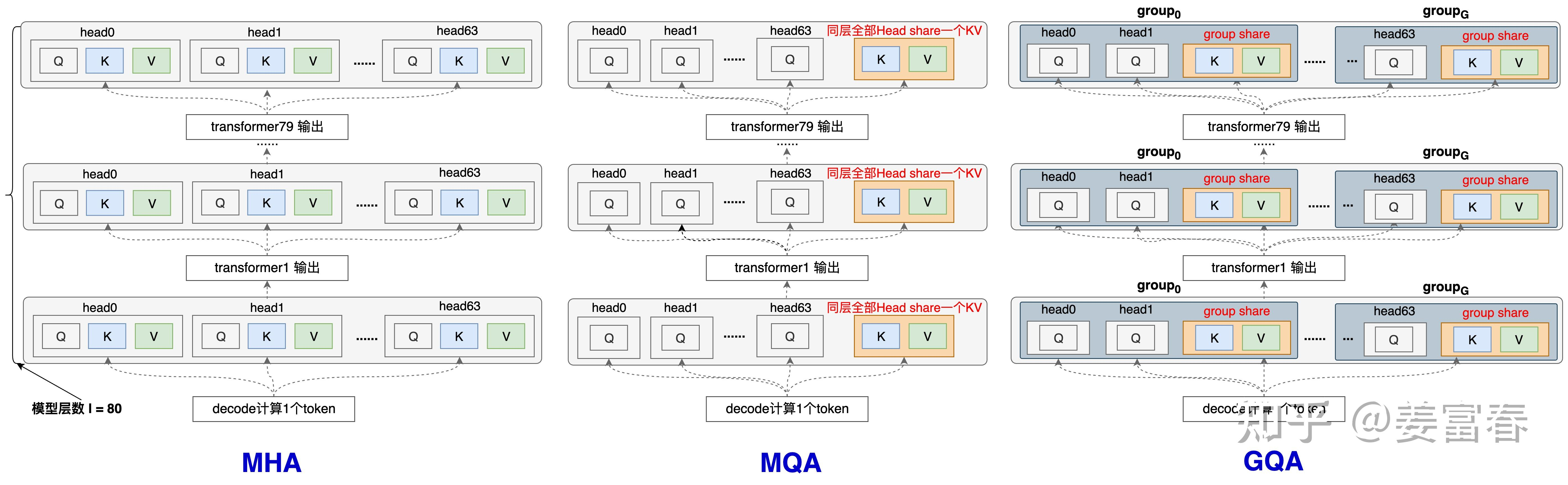
总结下单token计算下,几种方法KV Cache的存储量(模型层数:l,每层Head数量:n_h )

参考链接
https://zhuanlan.zhihu.com/p/16730036197
https://spaces.ac.cn/archives/10091

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)