一、前言
随着深度学习模型的不断发展,量化(Quantization)作为一种优化手段,已经在嵌入式设备和资源受限平台上得到了广泛应用。特别是在边缘计算和智能硬件领域,量化能够有效减小模型的存储占用并加速推理过程。PTQ(Post-Training Quantization)作为一种无需重新训练模型的量化方式,因其简便性和高效性而成为常用的部署手段。
然而,PTQ过程中常常会遇到模型精度下降的问题,尤其是在部署到特定硬件平台时,精度损失可能会更加显著。地平线J6平台作为一个强大的AI处理平台,支持多种深度学习框架的推理,然而如何确保量化后的模型在J6平台上依然保持较高的精度,是很多开发者面临的挑战。
本博客旨在分享一些在地平线J6平台上进行PTQ模型部署时遇到的精度问题排查经验。通过总结实际操作中的常见问题和排查步骤,希望能为开发者提供一些参考,帮助更顺利地部署量化模型。尽管每个项目的情况可能有所不同,但通过合理的排查和优化,通常能够找到合适的方案来减小精度损失,提升模型在实际应用中的性能
二、 精度下降的常见原因
三、排查方法
校准数据的来源应该是浮点模型的训练集、验证集或测试集中的20~100份数据。以图像数据为例,校准集的图像应具有代表性,避免使用非常少见的异常样本,如纯色图片或不含任何检测或分类目标的图片等,这些样本可能导致量化后的精度偏差。此外,校准数据需要经过与原始浮点模型一致的预处理,包括图像的归一化、尺寸调整等,并以.npy文件格式保存,以确保与模型输入格式一致。
例如YOLOv8的前处理:颜色空间转换(BGR->RGB)RGB)--> 数据排布转换(HWC->CHW)CHW)--> numpy2tensor numpy2tensor --> add batch dim add batch dim --> 归一化(/255)
#YOLOv8前处理
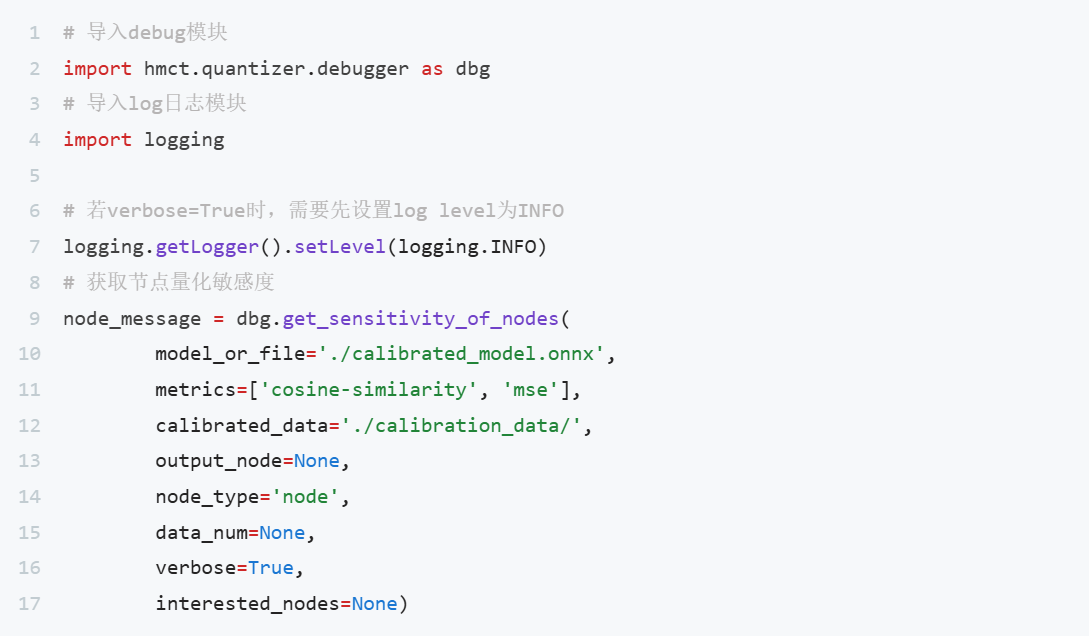
def preprocess(self, im: Union[np.ndarray]) -> torch.Tensor:
"""
Accepts one image in HWC format (np.ndarray), returns tensor (1, 3, H, W)
"""
im = self.pre_transform([im])[0]
if im.shape[-1] == 3:
im = im[..., ::-1] # BGR to RGB
im = im.transpose((2, 0, 1)) # HWC to CHW
im = np.ascontiguousarray(im)
im = torch.from_numpy(im).unsqueeze(0) # Add batch dim: (1, 3, H, W)
im = im.to(self.device)
im = im.half() if self.model.fp16 else im.float()
im /= 255.0
return im # (1, 3, H, W)
例如mean_value, scale_value 等值的配置是否与浮点模型预处理方式一致。
model_parameters:
onnx_model: 'yolov8s.onnx'
march: nash-e
layer_out_dump: False
working_dir: './model_output'
output_model_file_prefix: 'yolov8s_640x640_nv12'
remove_node_type: "Dequantize"
input_parameters:
input_name: ''
input_type_rt: 'nv12'
input_type_train: 'rgb'
input_layout_train: 'NCHW'
input_shape: '1x3x640x640'
norm_type: 'data_scale'
mean_value: ''
scale_value: 0.003921568627451
calibration_parameters:
cal_data_dir: './calibration_data'
calibration_type: 'kl'
compiler_parameters:
optimize_level: 'O3'
1.定位精度下降的阶段
使用 HB_ONNXRuntime工具推理产出的模型(original_float_model.onnx、optimized_float_model.onnx、calibrated_model.onnx、quantized_model.bc等),定位精度下降的阶段。若在original 或 optimized 阶段出现了问题,则检查原始onnx模型是否转换错误。若是在 calibrated_model.onnx 出现问题,则需通过精度debug工具比较余弦相似度,找出敏感算子。
HB_ONNXRuntime示例代码
import numpy as np
# 加载地平线依赖库
from horizon_tc_ui.hb_runtime import HBRuntime
# 准备模型运行的输入,此处`input.npy`为处理好的数据
data = np.load("input.npy")
# 加载模型文件,根据实际模型进行设置
# ONNX模型
sess = HBRuntime("model.onnx")
# HBIR模型
sess = HBRuntime("model.bc")
# HBM模型
sess = HBRuntime("model.hbm")
# 获取输入&输出节点名称
input_names = sess.input_names
output_names = sess.output_names
# 准备输入数据,根据实际输入类型和layout进行准备,配置格式要求为字典形式,输入名称和输入数据组成键值对
# 如模型仅有一个输入
input_feed = {input_names[0]: data}
# 如模型有多个输入
input_feed = {input_names[0]: data1, input_names[1]: data2}
# 进行模型推理,推理的返回值是一个list,依次与output_names指定名称一一对应
output = sess.run(output_names, input_feed)
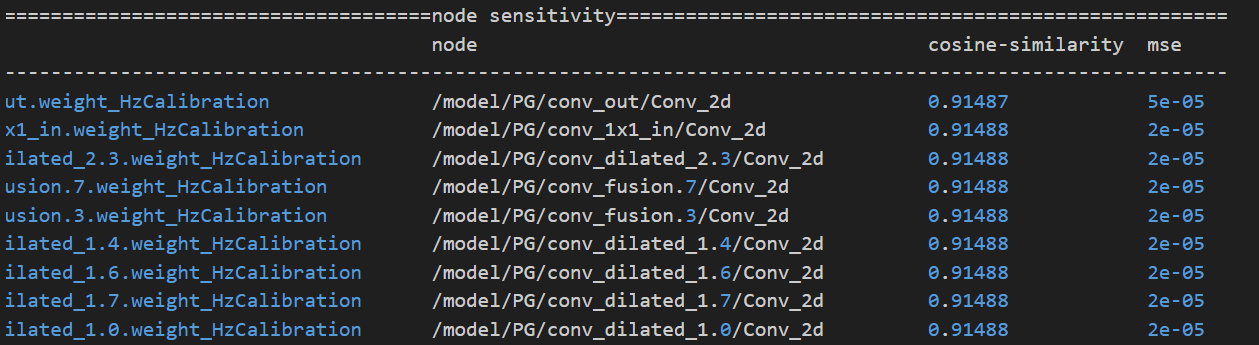
2.精度debug工具
在上述代码中可以将node_type分别设置为"node"、"weight"和"activation",得到的敏感度分析列表如下。(排序越靠前,说明量化误差越大。)
有以下解决方案:
1.在性能允许的情况下可以将 activation 设置为全int16。仅需在 quant_config 中设置 "all_node_type": "int16" 。若设置为全int16还无法满足精度需求,则需要进行算子拆分(算子拆分可以参考https://developer.horizon.auto/blog/13099)模拟双int16输入。
2.若性能不允许全int16,可以在debug后的敏感度分析列表下,选取误差较大的节点单独设置为int16。


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)