
1. 一分钟速览
- 问题:R1-style LRM(如 DeepSeek-R1、Kimi 1.5)在复杂任务上表现惊艳,却普遍存在 overthinking——推理链过长、冗余、重复,导致延迟 & 成本飙升。
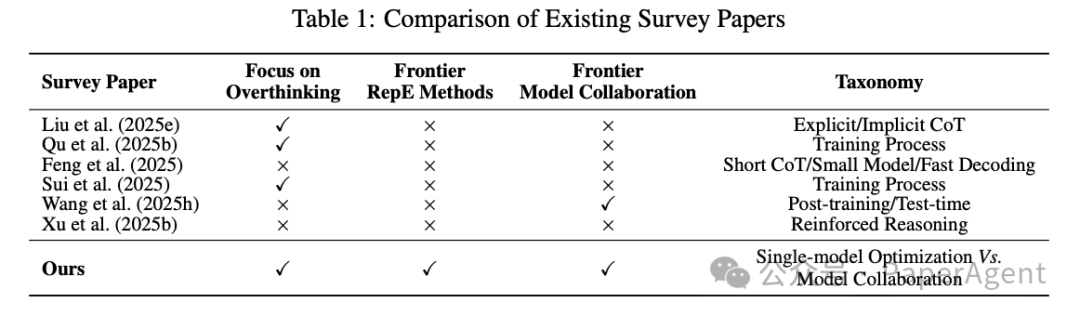
- 贡献:首篇系统综述高效推理的 survey,提出 「单模型优化 vs 多模型协作」 双层分类框架,覆盖 100+ 最新方法,并给出 4 大前沿应用展望。
2. 背景:当“想太多”成为瓶颈
现象 | 案例 | 后果 |
|---|---|---|
对简单问题仍生成超长 CoT | “2+3=?”→ 20+ 步推理 | 延迟↑、成本↑、准确率↓ |
不自信循环 | 反复自我验证、否定 | 输出方差↑ |
安全隐患 | 长推理链暴露更多攻击面 | 越狱、提示注入↑ |
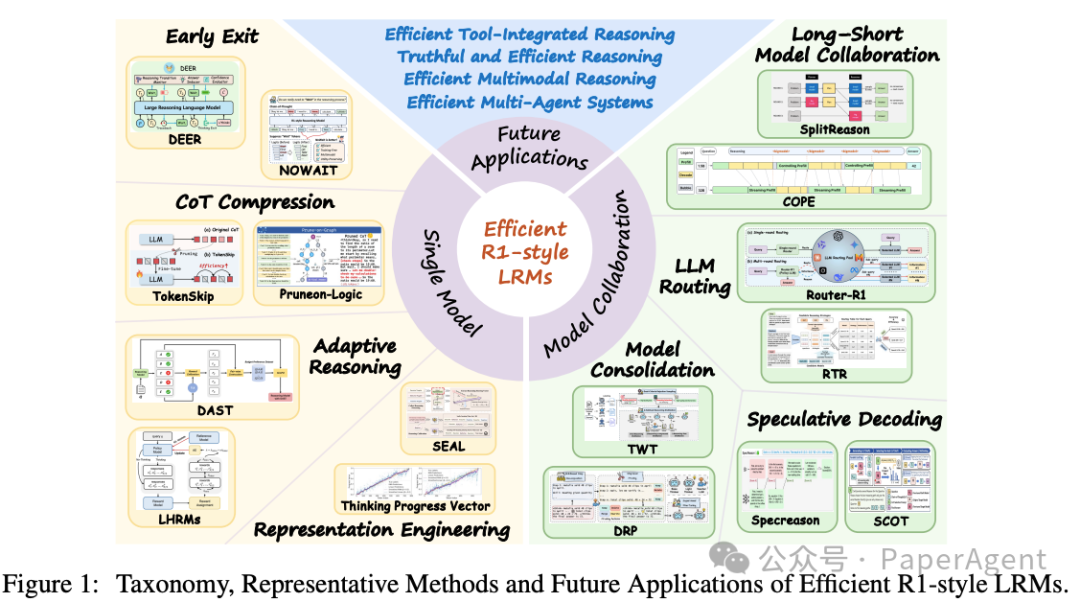
图 1:高效 R1-style LRM 方法分类与未来应用蓝图。
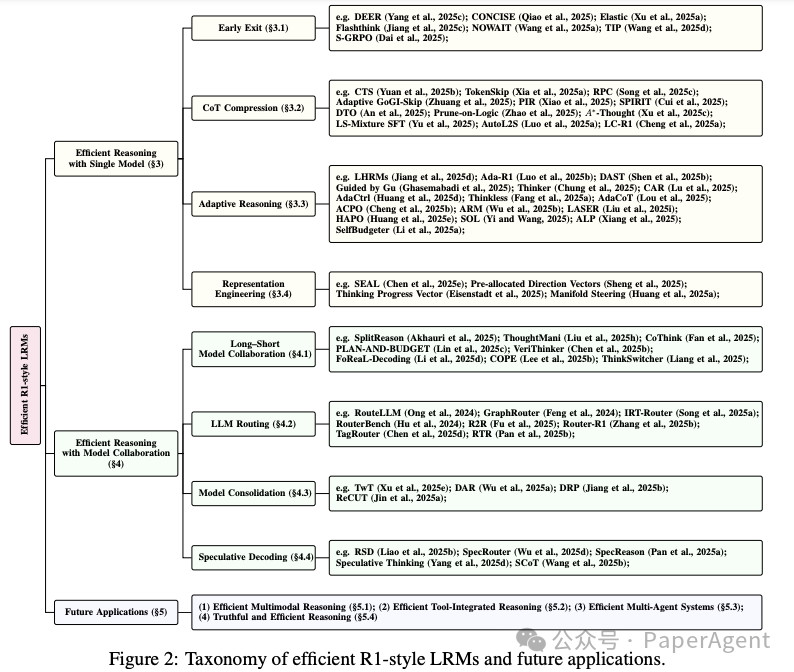
3. 方法全景:两条主线
范式 | 目标 | 代表策略 | 关键思路 |
|---|---|---|---|
单模型优化 | 在 一个 模型内部“减支增效” | Early Exit / CoT 压缩 / 自适应推理 / RepE | 提前停、剪枝、动态深度、潜空间操控 |
多模型协作 | 多个 模型“分工协作” | Long–Short 协作 / LLM Routing / 模型融合 / 投机解码 | 轻量模型打草稿,大模型把关 |
3.1 单模型优化:让模型“自省”
技术 | 子类 | 关键论文 | 一句话亮点 |
|---|---|---|---|
Early Exit | 监控/生成控制/自适应 | DEER | 发现“aha”token 立即刹车 |
CoT 压缩 | Token/Step/Chain 级 | CTS | 用参考模型给 token 打重要性分数 |
自适应推理 | RL 奖励 / 模式切换 / 长度惩罚 | Ada-R1 | 难度高→长链,简单题→直接答 |
RepE | 潜向量操控 | SEAL | 注入“少想”向量,抑制冗余反射 |
3.2 多模型协作:打组合拳
协作模式 | 代表方法 | 工作流程 | 速记 |
|---|---|---|---|
Short-to-Long | SplitReason | 轻模型先答,难题丢给大模型 | “小模型主刀,大模型支援” |
模型路由 | RTR | 为每个输入动态挑选最合适的模型(或模型组合) | 路由 |
模型合并 | TwT | 把长、短模型的优势“蒸馏”或“融合”成一个新模型,兼顾性能与效率。 | 蒸馏、融合 |
投机解码 | SpecReason | 小模型一次写多步,大模型并行验证 | “草稿+批改” |
4. 未来 4 大应用方向
方向 | 痛点 | 高效化思路 | 推荐阅读 |
|---|---|---|---|
多模态推理 | 视觉-语言链更长 | 阶段式 Caption → Reason → Answer | Visionary-R1 |
工具集成推理 | 过度调用 API | RL 奖励惩罚冗余调用,先过滤文档再推理 | Search-R1 |
多智能体系统 | 群体 overthinking | Router 按任务复杂度动态分配模型 | MASrouter |
可信高效推理 | 压缩后幻觉↑ | 同时优化“可信-简洁”双目标 | SafeMLRM |
5. 实验洞察 & 落地建议
- Early Exit 可在 零训练 场景下把 token 消耗 ↓30-50%,准确率几乎不掉。
- 模型融合(如 ReCUT)平均缩短回复长度 55%,适合已有多模型的团队。
- 投机解码 对 GPU 并行友好,延迟↓2-3×,适合在线服务。
📌 实践 Tips:
“让模型学会‘想得快且准’,而不是‘想得久且乱’。”

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)