
一、背景与问题提出
在 J6m 芯片平台,grid_sample 算子原生只支持 int8 输入。
然而,许多模型在训练时对特征输入精度要求较高,int8 精度不足以支撑推理效果,必须要 int16 输入 才能保证精度。
然而,许多模型在训练时对特征输入精度要求较高,int8 精度不足以支撑推理效果,必须要 int16 输入 才能保证精度。
如果不解决:
模型精度显著下降;
结果分布与训练预期不一致;
后续部署和优化步骤复杂化。
因此,需要找到一种方法在算子限制下支持 int16 输入。
二、算子限制与拆分方案
2.1 拆分思路
- 将 int16 数据拆分为 高位和低位 两份 int8 数据;
- 分别输入两个 int8 grid_sample;
- 通过 Add 合并高低位输出,得到最终 int16 精度结果。
2.2 拆分前后对比
方案 | Sub | GridSample | Add |
|---|---|---|---|
原版 | / | 1 | / |
拆分 | 1 | 2 | 1 |
表1 单个 grid_sample 算子在原版与拆分方案下的算子数量对比
问题总结:
算子数量显著增加;
- 芯片需加载两份数据 → 内存带宽压力翻倍;
- 当输入数据较大时,内存屏障成为性能瓶颈。
三、QAT 双 int16 支持方案
为了避免在推理阶段再做复杂适配,可以在 量化训练(QAT)阶段 开启双 int16 支持:
- 插件版本要求:horizon_plugin_pytorch ≥ 2.6.7
- 修改方法:在
horizon_plugin_pytorch/quantization/fx/graph_optimizers.py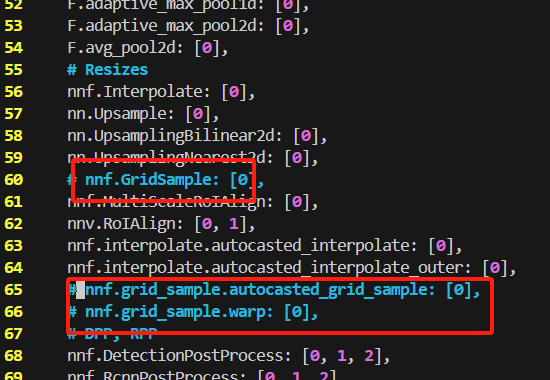
原Int8版 与 双 Int16 图结构对比
Int8原版 | 双int16 |
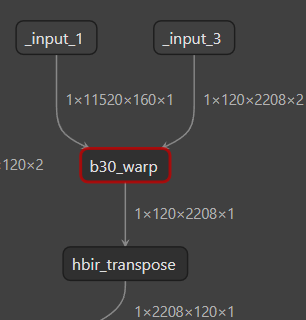 | 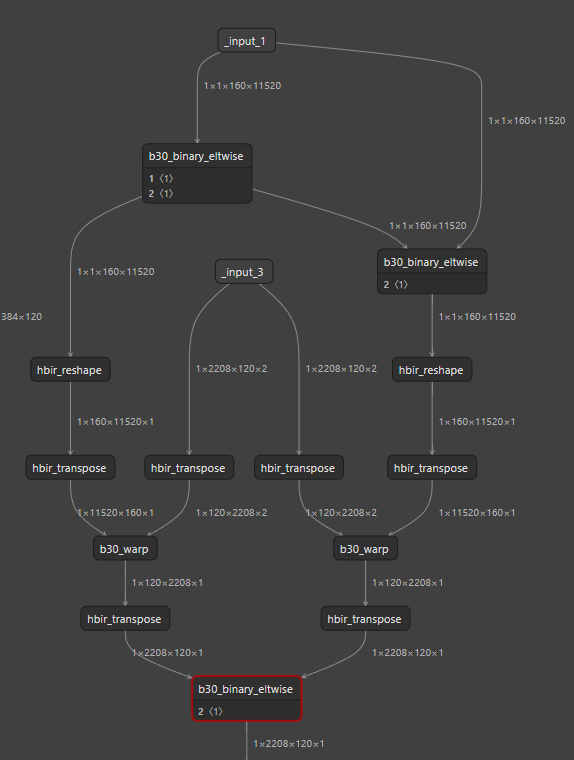 |
这样一来,从训练到部署全链路都能保持一致的 int16 输入支持,避免了精度损失。
四、性能优化实践
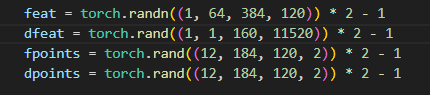
4.1 实验数据维度信息
4.2 初始实现
在最初实现中,采用 for 循环多次处理输入数据:
每次循环都会构建新的计算图;
数据被重复加载多次,算子冗余严重;
性能明显下降。
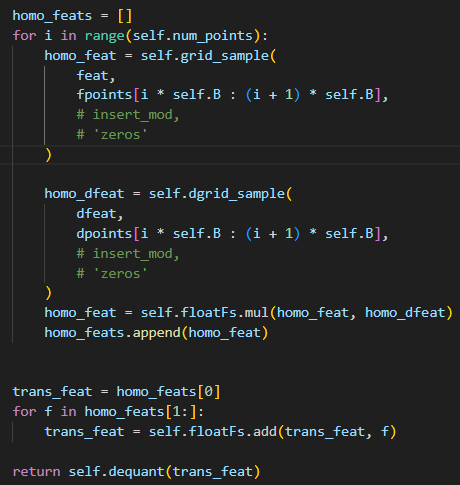
图3 初始实现下的计算图结构
4.3 优化思路与方法
- 去除 for 循环,一次性处理所有输入数据;
避免冗余计算图与重复 IO;
充分利用芯片算力,减少数据搬运开销;
提升算子融合效果,降低整体延迟。
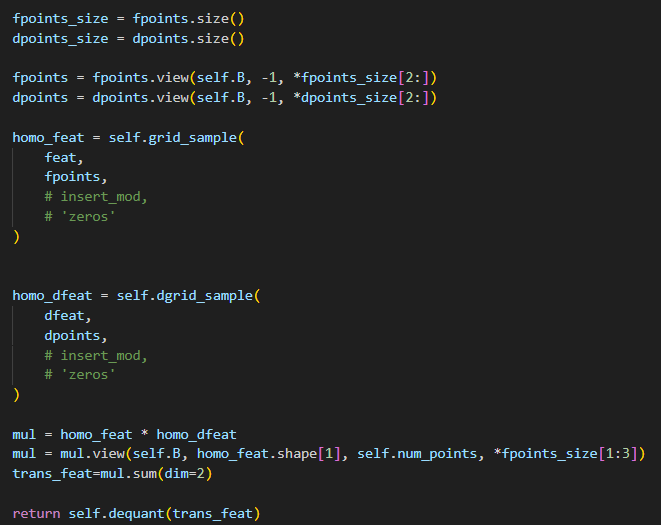
图4 优化后的计算图结构
五、性能对比实验(OE 3.2.0 + HBDK 4.4.5)
我们在 bilinear 与 nearest 两种插值模式下进行了测试:
模式 | 初始性能 | 优化性能 | 带宽消耗 |
|---|---|---|---|
bilinear | 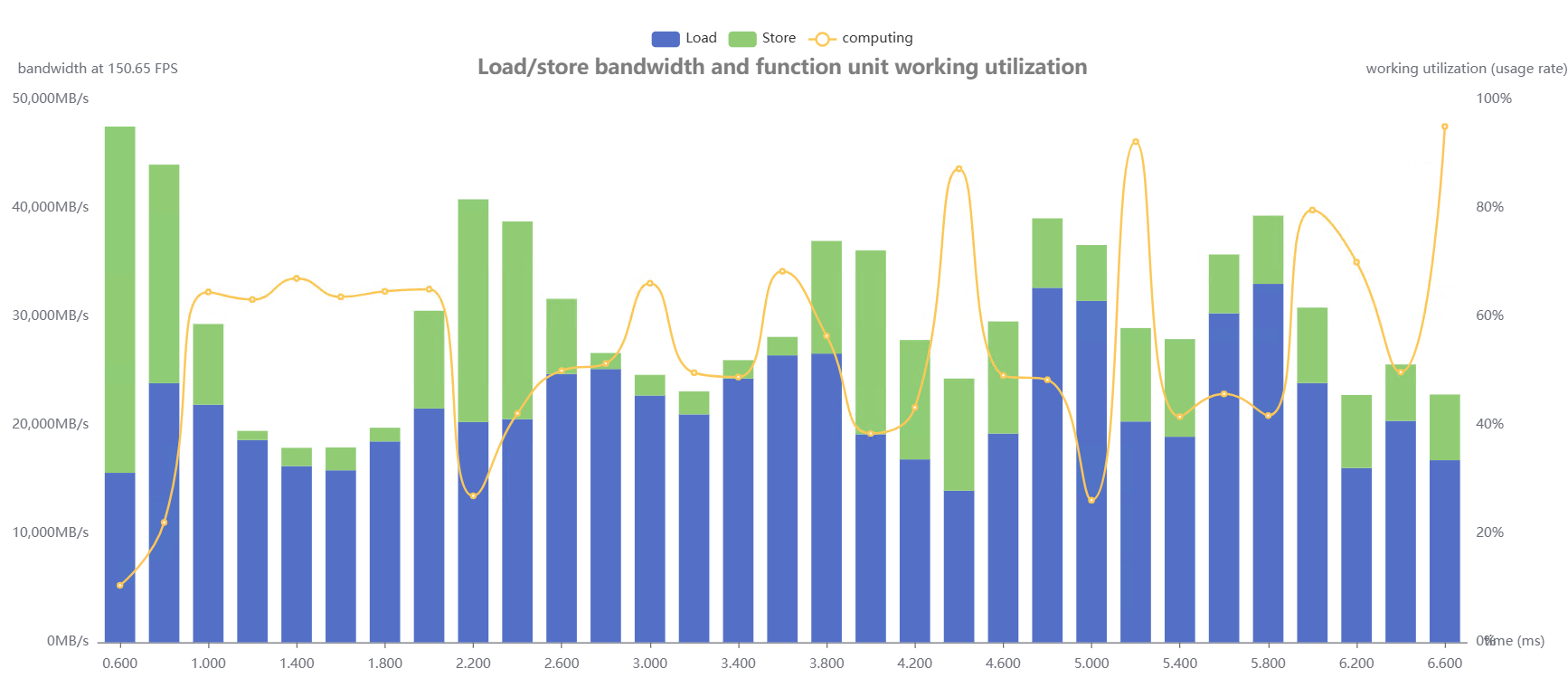 | 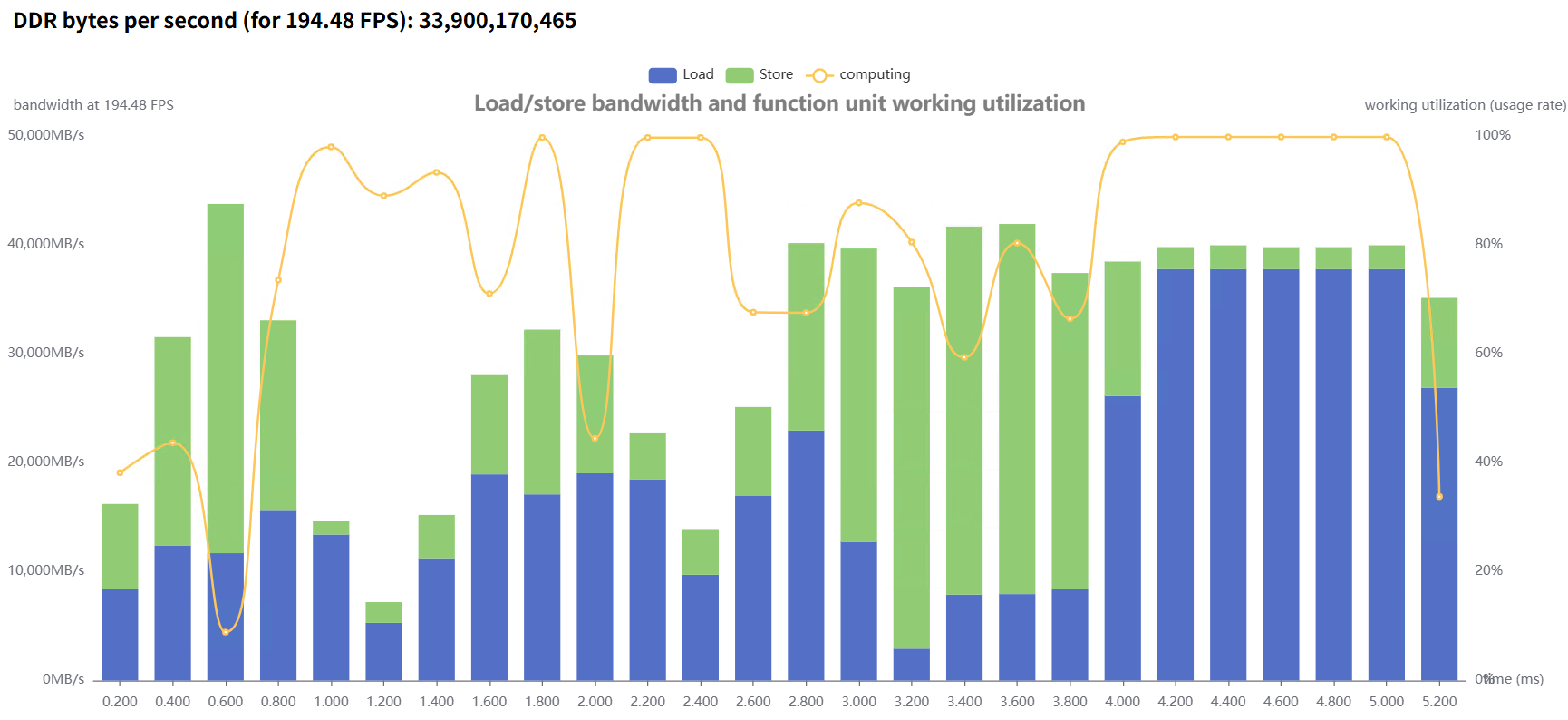 |  优化后--> 优化后-->  |
nearest | 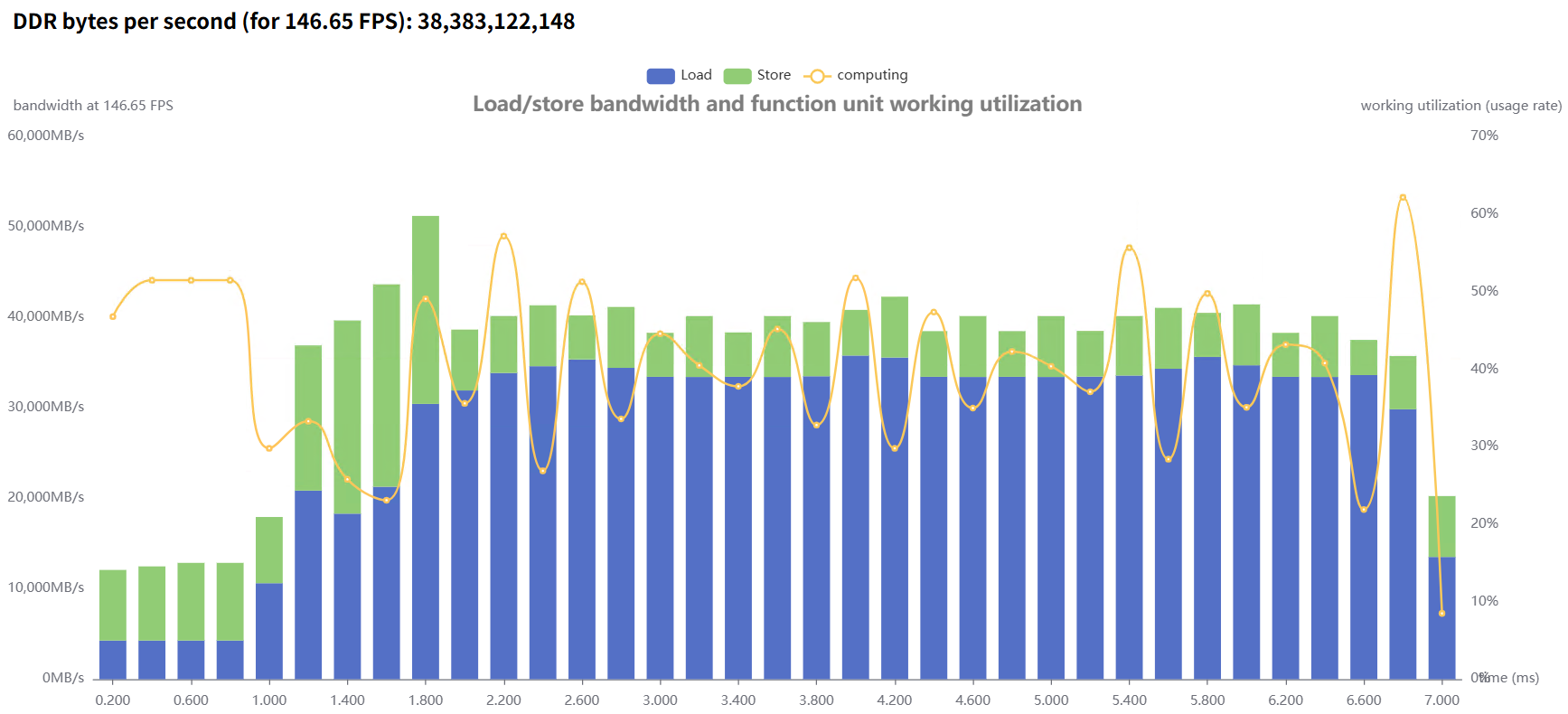 | 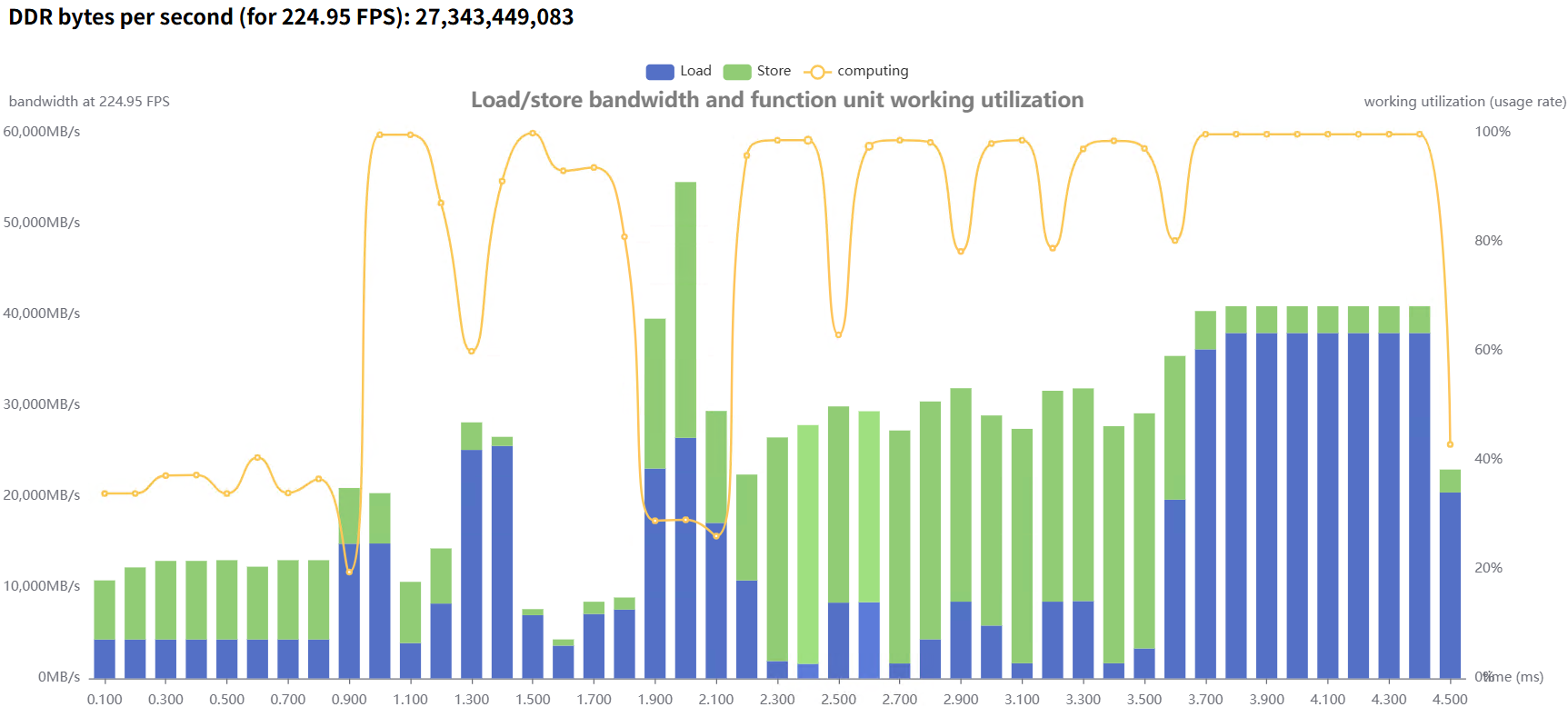 |  优化后--> 优化后-->  |
表2 在不同插值模式下的性能与带宽对比
实验表明:
优化后整体性能有明显提升;
内存带宽占用下降,系统稳定性更强;
在大规模输入场景下,优势更加显著。
六、更多思考与经验
- 算子拆分是无奈之举:虽然解决了精度问题,但不可避免地增加了算力和带宽开销。
- 图优化与数据优化必不可少:通过消除冗余循环、减少数据搬运,可以在一定程度上抵消性能损失。
- 编译器优化差异:不同 HBDK 版本对计算图优化策略不同,建议多版本尝试,寻找最佳解。
- 全链路一致性:在 QAT 阶段开启双 int16,可以从训练到部署保持一致性,减少调试时间和适配风险。
- 工程经验总结:算子拆分 + 编译器优化 + 带宽控制,三者结合才能实现真正的可落地方案。
七、总结
- 在 J6m 平台上,grid_sample 原生只支持 int8;
通过算子拆分,可以实现双 int16 输入支持;
在 QAT 阶段开启双 int16,能有效避免精度损失;
通过优化计算图结构,性能损失得到弥补;
实践表明,性能优化与带宽控制相结合,才能真正发挥 J6m 芯片的潜力。
希望本文的分享能为正在适配和优化 J6m 平台的开发者提供一些启发。
欢迎大家在社区留言交流更多经验!
欢迎大家在社区留言交流更多经验!

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)