
1. 注意力的本质:Q/K/V 的角色与数据流
1.1 三个角色
- Q(Query,查询):我要找什么(我的检索意图)。
- K(Key,键):我是谁(供别人匹配我的“身份标签”)。
- V(Value,值):我能提供的内容(被加权汇总的语义)。
1.2 公式
\mathrm{Attention}(Q,K,V) = \mathrm{softmax}\left( \frac{QK^{\top}}{\sqrt{d_k}} \right) V
$$
输入序列 $X\in\mathbb{R}^{B\times S\times H}$ 乘以可学习的 $W_Q,W_K,W_V$ 得到 $Q,K,V$。
点积得到相似度,softmax 转成概率分布。
- 对所有位置的 $V$ 加权求和(不是“命中一个取一个”),得到输出。
1.3 多头注意力(Multi-Head Attention)
将 $H$ 划分为多个头(head),每头维度 $D=H/\mathrm{heads}$:$[B,S,H]\to[B,\mathrm{heads},S,D]$。
- 不同头学习不同的相关性样式(短/长依赖、语法/语义偏好等),分工+汇合,总体表达不减反增。
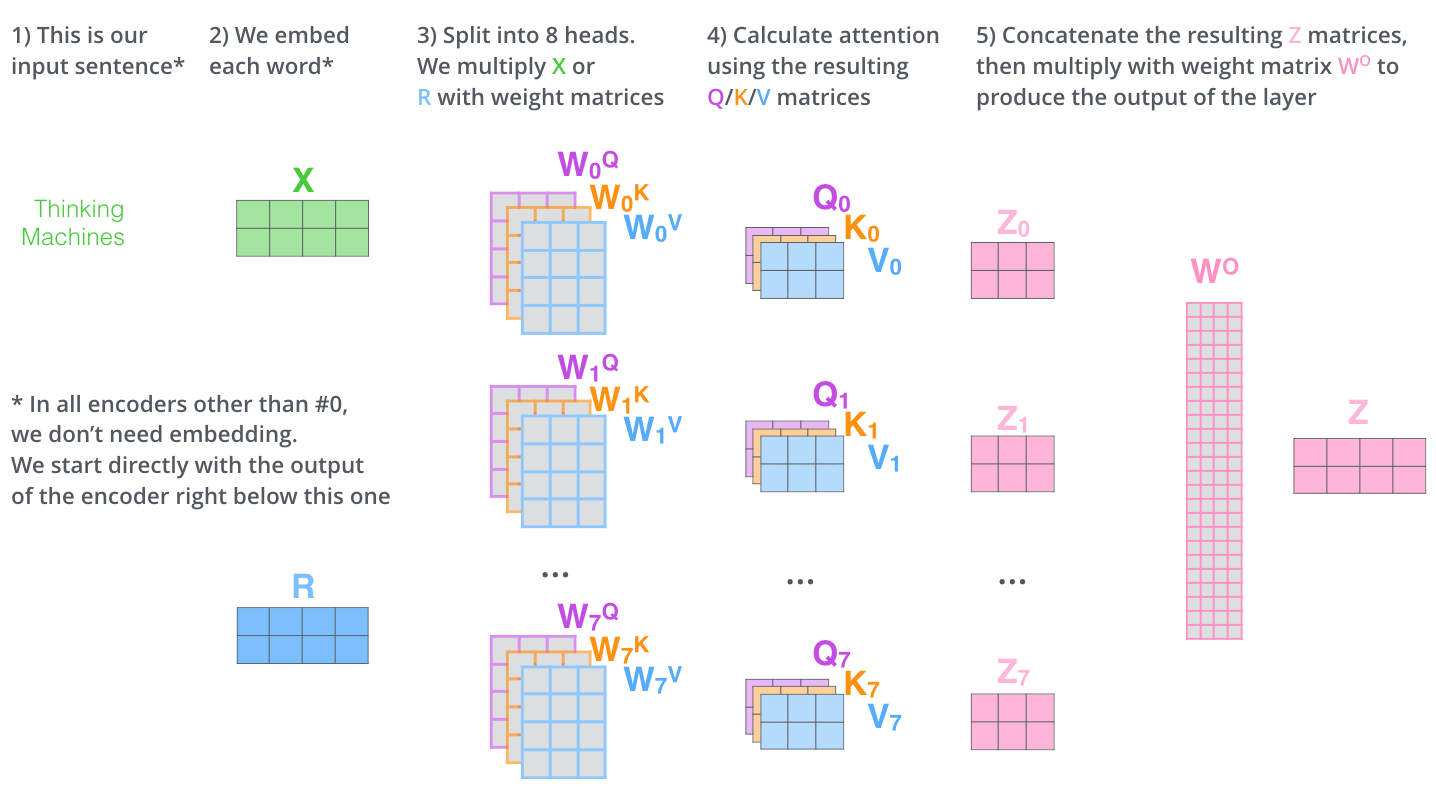
图:Multi‑Head Attention 数据流
2. Transformer 架构全貌(注意力只是其中一环)
组件 | 作用 | 特点 | 类比 |
|---|---|---|---|
Multi‑Head Attention | 全局依赖建模 | 高并行,核心 O(S²) | 开会交流 |
前馈网络 FFN | 每 token 独立特征提炼 | 两层线性+激活,常 4H 扩展 | 会后总结 |
残差连接 | 保信息/稳训练 | 防梯度退化 | 保留原始记录 |
LayerNorm | 数值稳定 | 控制均值/方差 | 心理医生 |
Positional Encoding | 注入顺序感 | 绝对/相对/旋转位置 | 页码/座位号 |
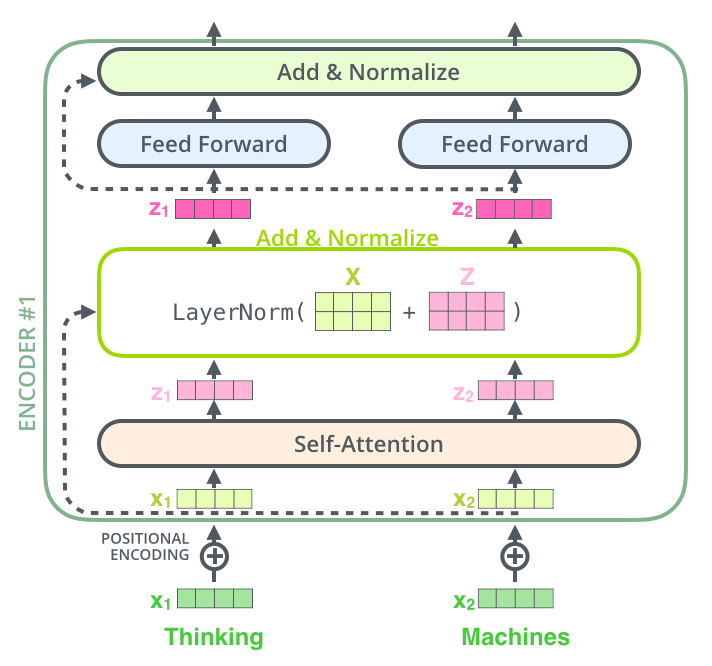
图:Transformer Encoder Block(来源:Lilian Weng 博客)
常见实现要点:
- FFN:FFN(x)=ϕ(xW_1+b_1)W_2+b_2,$\phi$ 常用 GELU/SiLU/RELU,维度 H→4H→H。
- 残差+Norm:x = x + SubLayer(LN(x))(Pre‑LN 更易深层训练)。
- 位置:绝对(正余弦/可学习)、相对(T5/Transformer‑XL)、旋转位置(RoPE)。
3. 为什么有那么多 reshape / transpose?
3.1 数据形状切换
- 原始:[B, S, H]
- 拆头:→ [B, S, heads, D] → [B, heads, S, D]
- 计算 Q @ K^T:需要 K 形状 [B, heads, D, S](对后两维转置)
- 拼头:[B, heads, S, D] → concat → [B, S, H]
3.2 工程挑战
- 在 PyTorch 里多为视图变换;但端侧 BPU 上,layout 不匹配可能触发真实拷贝/重排,带来带宽与延迟成本。
3.3 工程优化
- QKV 融合(一次 GEMM 产出三者);
- layout‑aware:用 matmul(transpose_b=True) 避免显式 permute 新张量;
- 对齐:让 heads/seq_len/head_dim 成为内核友好的倍数;
- 块化注意力/FlashAttention:降低中间态与溢出风险。
4. Transformer vs CNN
维度 | Transformer | CNN |
|---|---|---|
依赖建模 | 全局(任意两位置直接交互) | 局部(需叠层/池化扩感受野) |
复杂度 | 注意力核 O(S²D),可用块化/稀疏/线性注意力优化 | 单层 O(S·k²·C),总体近线性 |
归纳偏置 | 弱(更依赖数据) | 强(平移不变、局部平滑) |
并行性 | 高度 GEMM 并行 | 高缓存命中率与数据局部性 |
位置/空间 | 需显式位置编码 | 天然位置感 |
数据效率 | 往往更吃数据与正则 | 通常更高效 |
擅长 | 长依赖、跨模态、预训练大模型 | 实时/边缘视觉 |
5. Transformer 量化难点与破法
下列每项按 作用 → 原理 → 难点 → 解法 → 示例 五段式给出,便于检索与落地。
5.1 Softmax 与 Attention Score(QK^T)
原理:scores=(QK^T)/√D + mask,weights=softmax(scores)。
难点:范围波动大;mask 注入极大负值;exp/归一化 对量化误差极敏感 → 分布塌缩/过平。
解法:logit clipping;减行最大值;块化 softmax(FlashAttention);混合精度;exp 近似(LUT/多项式)。
示例(PyTorch):
5.2 LayerNorm(或 RMSNorm)
原理:LN(x)=(x-μ)/√(σ²+ε)*γ+β;RMSNorm(x)=x/||x||_rms*γ。
难点:低比特下均值/方差路径不稳,误差被放大。
解法:RMSNorm 替代, 去掉减均值操作,只用均方根作为缩放。
示例(RMSNorm):
5.3 残差分支(Add)与尺度对齐
原理:逐元素相加,需同一标度。
难点:量化尺度不齐(Sx≠Sf)→ 饱和/分辨率丢失。
解法:requant 对齐;残差用更高比特(INT16/FP16);图融合 BiasAdd/ResidualAdd。
示例(定点相加):
5.4 FFN 与激活(GELU/SiLU)
原理:FFN(x)=φ(xW1+b1)W2+b2;常用 φ=GELU/SiLU,维度 H→4H→H。
难点:GELU 含高斯 CDF,整数域代价高;激活/权重分布长尾。
解法:函数近似(多项式/Tanh 近似);可替换 ReLU/Relu6(视任务);QAT。
示例(GELU 近似):
5.5 Q/K/V 与形状变换(重排带宽)
原理:三次线性层或一次 QKV 融合,输出 [B,S,3H] 再切片。
难点:显式 permute/transpose 在端侧触发拷贝;heads/D/S 不对齐致慢核与填充。
解法:QKV 融合;matmul(transpose_b=True) 避免显式转置;对齐到向量宽度(8/16/32)。
示例(融合 QKV):
5.6 KV Cache(长上下文推理)
原理:每步把新 token 的 K/V 追加到缓存,查询只与缓存做注意力。
难点:INT8 下 K/V 尺度漂移,长序列累计误差;层/头统计差异大。
解法:per‑head / per‑layer scale;块化缓存(128/256 token 一块);关键层回退 FP16。
示例:
5.7 RoPE / 相对位置编码的量化
原理:对偶奇维做二维旋转:$[e,o]\to[e\cos\theta-o\sin\theta,e\sin\theta+o\cos\theta]$。
难点:三角函数整数域实现复杂;长序列相位外推更敏感。
解法:预计算 cos/sin(FP16)并广播;LUT/分段近似;QAT 中模拟近似核。
示例(RoPE 片段):
环节 | 作用 | 难点 | 参考解法 |
|---|---|---|---|
Softmax/scores | 概率归一 | 溢出/塌缩 | 剪裁+减行最大+块化+混合精度 |
LN/RMSNorm | 稳定数值 | 统计不稳 | RMSNorm/高精/折叠 |
残差 Add | 深层训练 | 尺度不齐 | requant 对齐/高比特残差 |
FFN/GELU | 非线性提炼 | 近似误差 | 函数近似/QAT/可替换激活 |
QKV/重排 | 带宽瓶颈 | 隐式拷贝 | QKV 融合/layout‑aware/对齐宽度 |
KV Cache | 长序列 | 尺度漂移 | per‑head scale/块化/混合精度 |
RoPE/相对位 | 位置建模 | 三角近似 | 预计算/LUT/QAT |
6. 实操要点
全章采用统一结构,便于检索与复用;在不改变你原先要点的前提下,补齐“原理与示例”。
6.1 架构选择:优先 Pre‑LN
原因(保留):Pre‑LN 梯度更稳、收敛更易;LN 可保高精,其余低精时更一致。
原理:子层输入前做归一化,反向梯度不穿过未归一化长链路;Post‑LN 需跨子层与残差,易消失/爆炸。
做法:每子层采用 x = x + SubLayer(LN(x))。
收益:更深层可训、震荡小;量化时 LN 保高精不破结构。
示例:
6.2 归一化算子保高精 / RMSNorm 替代
原因(保留):LN 对统计量敏感;RMSNorm 更简洁稳定。
原理:LN 需均值/方差(平方/开方),RMSNorm 只需均方根,路径更短。
做法:LN/RMSNorm 用 FP16/BF16;把缩放与后续线性层融合减算子。
收益:推理更稳、延迟更低。
示例:
6.3 QKV 融合与 layout‑aware 设计
原因(保留):三次投影与显式转置放大带宽/拷贝;融合更高效。
原理:内核支持 transpose_b/strided_batched_gemm;算子级转置优于张量级 permute+contiguous。
做法:一次线性层产出 [B,S,3H] 切 Q/K/V;用 matmul(transpose_b=True)。
收益:延迟下降、吞吐提升。
示例(C++):
6.4 SmoothQuant / Outlier 处理
原因(保留):outlier 迫使激活 scale 过大,主体分辨率下降。
原理:通道尺度重分配(A 缩小 / W 放大)保持线性等价。
做法:统计每通道激活峰值 a_max[c],设 α_c=a_max[c]^β 调整。
收益:激活 per‑tensor 量化更稳,精度回升。
示例:
6.5 残差尺度策略
原因(保留):不同尺度相加会溢出或丢分辨率。
原理:在公尺度 Sx 下做 X + round(F*Sf/Sx) 的整数加法。
做法:Add 前做 requant 对齐;必要时残差路径用 INT16/FP16。
收益:防溢出,保留残差信息。
示例:
6.6 校准与验证
原因(保留):仅短序列/无掩码校准会失配长序列/有掩码推理。
原理:量化标定相当于估计上界/分位数,需覆盖多模态分布。
做法:混合不同长度、掩码形态、采样温度的样本校准。
收益:部署精度与线上一致。
示例:
6.7 静态形状与对齐
原因(保留):动态 shape 触发慢核或重编译;对齐减少尾部填充。
原理:对齐到向量宽度(8/16/32)能减少分支与 padding。
做法:限制 S/Heads/D 到固定集合并对齐。
收益:吞吐提升、延迟更稳。
示例(配置):
6.8 混合精度映射表(推荐)
原因(保留):把敏感环节放高精,线性算子用 INT8 更经济。
原理:softmax/LN 误差放大效应高;线性层依赖 int32 累加与 per‑channel scale。
做法:按模块指定精度策略。
收益:兼顾精度/吞吐。
示例(YAML):
6.9 端到端流程(PTQ → QAT → 部署)
原因(保留):近似函数/布局/块化策略不一致会造成域外误差。
原理:以 QAT 模拟部署核,确保量化、近似、块化完全对齐。
做法:Pre‑LN + FusedQKV + RMSNorm → SmoothQuant → PTQ 校准 → 不达标则 QAT → 部署启用块化注意力与静态形状。
收益:达成精度目标并获得稳定吞吐。
示例(伪带啊吗):
7. 结语
- 注意力 ≠ Transformer:Attention 是心脏,但 Transformer 的身体还有 FFN/残差/Norm/位置等关键器官。
- 与 CNN 的差异:全局 vs 局部、弱偏置 vs 强偏置、GEMM 并行 vs 高数据局部性。
- 量化落地三要素:layout‑aware + 混合精度 + QKV 融合。再配合 块化注意力 与 静态形状对齐,才能把理论优势转成端侧吞吐。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)