
1.前言
随着 J6 芯片家族的阵容不断壮大,算法工具链在量化精度方向的优化也在持续深入,具体体现在两个方面:
J6P 与 J6H 工具链已陆续进入发布和试用阶段,在此背景下,QAT(量化感知训练)需要以更高效的方式适配算子的浮点计算能力,以确保量化精度和用户的使用体验;
MatMul、Conv、Linear 等 Gemm 类算子目前已正式支持双 int16 输入,这一改进有助于提升相关算子在量化计算时的精度和调优时的效率。
为了更全面、稳妥地支持上述新功能,同时对当前的 qconfig 量化配置以及回退逻辑进行优化升级,工具链从OE3.5.0开始支持新版qconfig量化模板。新版本针对 qconfig 模板开展了大量的重构工作,重构后的 qconfig 模板不仅能更好地适配新的芯片特性和算子功能,还同时保持对旧版本 qconfig的维护,保障了用户在升级过程中的平滑过渡,减少了因版本迭代带来的适配成本。
2.新版qconfig模板配置流程
本章将系统且全面地为大家呈现新版 qconfig 模板的核心内容,涵盖其关键更新点、规范的基本使用流程以及对相关产出物的详细介绍。
2.1 主要更新点
在更新点方面,新版 qconfig模板的迭代升级紧密贴合 J6 平台家族的持续发展以及工具链不断优化的实际需求,通过针对性的设计与调整,进一步提升了量化配置的效率、灵活性与适配性。其与旧版流程的区别主要体现在以下四个方面:
- 模板与回退机制的统一管理:将模板和回退进行了统一,在同一个流程下管理;
- 强化对特定量化配置的友好性:对浮点计算的量化配置、Conv/Matmul等Gemm算子单/双 int16输入配置更加友好;
- fuse 默认行为的调整与优化:旧模板默认 conv-bn-add-relu 全部 fuse,然后再根据硬件限制回退至int8。为了实现更高的计算精度,新模板首先配置dtype,若不符合要求则不做 fuse,最终 dtype 结果更加符合预期,而且针对不同芯片架构的硬件特性设计了不同的fuse行为;
- 新增量化配置文件保存功能:支持保存量化配置文件qconfig_dtypes.pt、qconfig_dtypes.pt.py以及qconfig_changelogs.txt。其中,qconfig_dtypes.pt 为可供用户加载的算子级别的量化配置文件,实现了配置的便捷迁移与共享;qconfig_dtypes.pt.py 则以 Python 脚本形式保存配置信息,便于用户查看;qconfig_changelogs.txt 则记录了配置过程中的算子变更日志,包括量化参数调整记录、模板使用信息等,为配置的追溯、调试提供了清晰的依据,进一步提升了量化配置的可解释性与可复用性。
2.2 基本使用流程
新版 qconfig 模板在使用流程上围绕基础 qconfig 配置reference_qconfig、templates量化模板配置展开,各环节紧密关联,共同助力用户实现高效、精准的量化配置。新版qconfig 模板的基本使用流程如下所示:
以上就是新版qconfig模板的基本使用流程,下面将对其核心部分QconfigSetter接口和工具链提供的多个templates进行介绍。
2.2.1 QconfigSetter接口介绍
QconfigSetter接口的定义如下所示:
代码路径:horizon_plugin_pytorch/quantization/qconfig_setter/qconfig_setter.py
- reference_qconfig【必要配置】:配置observer,可选项包括MSEObserver 、MinMaxObserver等。
- templates【必要配置】:配置使用到的qconfig模板,仅关注dtype,按照顺序依次生效。
- enable_optimize【必要配置-用户可不关注】: 是否采用默认的优化pass,默认配置为True,相关优化如下:
- CanonicalizeTemplate: 按算子类型对 dtype 配置进行合法化,当前默认规则有:
Gemm 类算子输入不支持 float
插值类算子:在不同 march 下有不同的限制
DPP、RPP 等特殊算子仅支持 int8
其他算子的通用规则:算子的 input dtype 和 output dtype 不能同时存在 qint 和 float
- EqualizeInOutScaleTemplate:对于 relu,concat,stack 算子,应该在算子输出统计 scale,否则精度或性能存在损失。为此:
将前面算子的 output dtype 配置为 float32
Relu,concat,stack 算子在 export hbir 时,在 input 处插入伪量化,scale 复用 output scale
- FuseConvAddTemplate:硬件支持 conv + add 的 fuse,不同的芯片架构的融合条件不一致,满足融合条件会有以下行为:
将 conv 的 output dtype 配置为 float32
将 add 对应的 input dtype 配置为 float32
- GridHighPrecisionTemplate:根据经验,grid sample 的 grid 计算过程用 qint8 精度不够,因此自动将相关算子配置为qint16计算。
- InternalQuantsTemplate:模型分段部署场景下,会在分段点处插入 QuantStub,用于记录此处的 dtype 和 scale,此类 QuantStub 的 dtype 配置必须和输入保持一致。
- OutputHighPrecisionTemplate:当 Gemm 类算子作为模型输出时,将其配置为高精度输出。
- PropagateTemplate:对于拆分为子图实现的算子,存在经验性配置,如 LayerNorm 和 Softmax 内部小算子应该使用高精度。
- SimpleIntPassTemplate:性能优化,对于 op0->op1->op2 此类计算图,若以下条件同时成立,则将 op1 输出类型修改为 int:
op2 需要 int 输入
op0 可以输出 int
op1 当前输出为 float16,且属于以下类型
cat,stack
mul_scalar
无精度风险的查表算子(即在 fp16 上默认使用查表实现的算子)
- SimplifyTemplate:删除多余的量化节点配置(将对应的 dtype 修改为 None)
进一步的说明可以参考用户手册【Qconfig详解】。 - save_dir【必要配置】:量化配置文件保存的路径。
2.2.2 templates介绍
- ModuleNameTemplate(必要配置):通过 module name 指定 dtype 配置或量化阈值,包括激活/weight量化配置,固定scale配置;配置粒度支持全局、模型片段和算子等;配置dtype包括qint8、qint16、torch.float16、torch.float32等,相关配置项可以参考用户手册【Qconfig详解】;
- MatmulDtypeTemplate(必要配置):通过名称或前缀配置Matmul算子单int16/双int16输入,支持批量配置,相关配置项可以参考用户手册【Qconfig详解】;
- ConvDtypeTemplate(必要配置):通过名称或前缀配置Conv/Linear算子单int16/双int16输入,支持批量配置,相关配置项可以参考用户手册【Qconfig详解】;
- SensitivityTemplate(可选配置):通过量化敏感度列表提升数据类型精度,默认将敏感算子配置为int16,支持激活敏感和weight敏感算子分别配置高精度,相关配置项可以参考用户手册【Qconfig详解】。
- LoadFromFileTemplate:从qconfig_dtypes.pt文件中加载量化配置,仅可加载全局及每个算子的量化类型,暂时无法加载 fix_scale 配置,且不支持对 qconfig 进行修改。而且需要注意,此时 enable_optimize 必须配置为 False,否则无法保证配置结果的正确性,部署时可能存在 CPU 算子。
用户配置的模板按顺序生效,前面模板的配置会被后面的模板覆盖。
一般来说,用户会使用到ModuleNameTemplate、ConvDtypeTemplate、MatmulDtypeTemplate和SensitivityTemplate这4个模板,其中前3个模板为必要配置。以下是templates的常用配置,如下所示:
2.3 产出物介绍
- model_check_result.txt、fx_graph.txt:二者均由prepare接口自动生成,model_check_result.txt中包括未 fuse 的 pattern、每个 op 输出/weight的 qconfig 配置、异常qconfig配置提示等,fx_graph.txt保存的是模型的fx trace图;
- qconfig_dtypes.pt.py和qconfig_dtypes.pt:为QconfigSetter接口输出的量化配置载体,完整记录全局及算子级别的量化精度参数,包括每个算子的input、weight和output的量化精度,如qint8、qint16和torch.float16等,其中.py文件供用户阅读,.pt文件可以使用LoadFromFileTemplate接口加载,qconfig_dtypes.pt.py中信息如下所示;
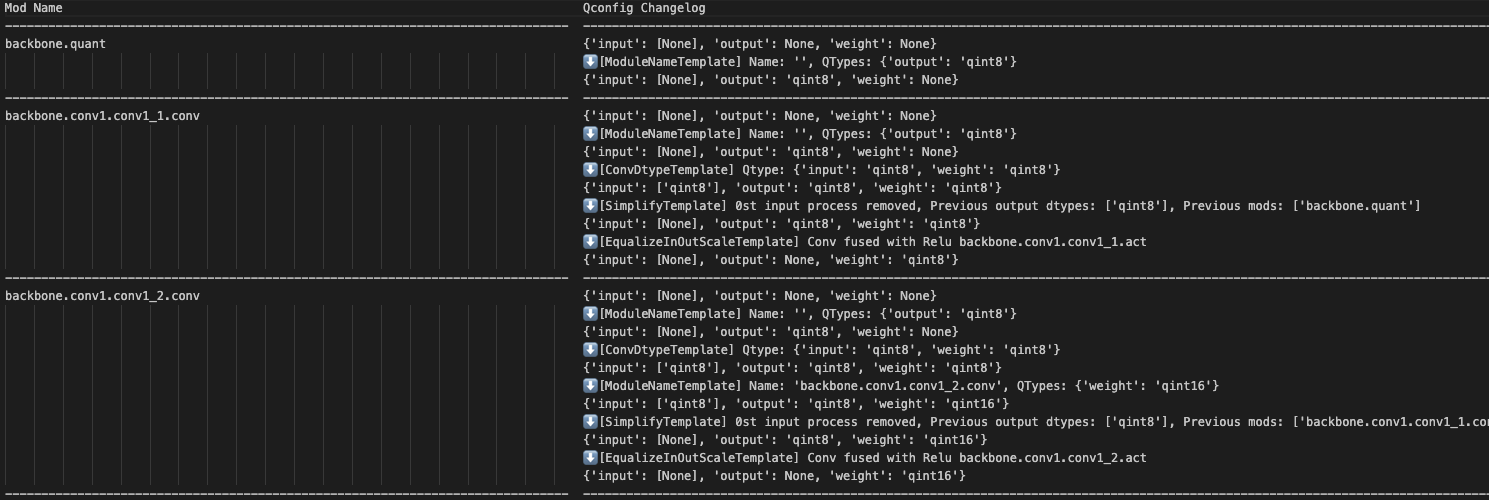
- qconfig_changelogs.txt:每个算子qconfig根据Templates的变化逻辑,页面如下所示:
3. 使用示例
本章节将会提供上述模板的使用方法以及在典型场景下的配置示例。
3.1 配置全局fp16/int16/int8
3.1.1 配置全局int8
配置全局qconfig时必须要配置 ModuleNameTemplate、ConvDtypeTemplate、MatmulDtypeTemplate这3个模板,以下为使用示例:
配置全局int16的方式与全局int8类似,将上述示例中的qint8修改为qint16即可。
注意:
配置全局feat为int8/int16/fp16的时候必须要对Conv类算子的weight进行配置,否则weight会自动做int16计算,并可能出现不符合预期的CPU算子;
配置全局int8后,model_check_result.txt可能会显示模型中仍然存在int16计算的算子,这是工具为了提升量化精度做的自动化行为,比如norm这种进行拆分实现的算子,内部采用int16较高精度的计算,然后输出为int8。
3.1.2 配置全局feature int16+weight int8+prefix批量配置
3.2 fixscale配置
模型中的某些地方很难依靠统计的方式获得最佳的量化 scale,比如物理量,此时当算子的输出值域确定时就可以设置 fixed scale。新版qconfig模板配置fixed scale的方式为配置输入/输出的量化类型“dtype”和阈值“threshold”,其中scale的计算为:

其中threshold一般为算子输入/输出的绝对值的最大值;n则为量化位宽,比如int8量化位宽n=8。
如下为配置quantstub算子输出scale和conv算子输入scale的示例:
量化配置 | model_check_result.txt中对应信息 |
"backbone.quant"的输出scale固定为0.0078 |  |
"backbone.conv1.conv1_2.conv"的weight输入的scale=3.0518e-05的int16量化 |  |
3.3 批量配置conv/matmul 单/双int16输入
ConvDtypeTemplate和 MatmulDtypeTemplate支持单/双int16输入的批量配置,相关示例如下:
3.4 LoadFromFileTemplate使用示例
当从旧模板迁移到新的qconfig量化模板时,推荐的做法是先把旧版本的量化配置qconfig_dtypes.pt保存下来,然后使用LoadFromFileTemplate进行加载,这里仅介绍此接口的用法,后续章节有完整的迁移教程。
LoadFromFileTemplate接口使用时需要注意以下问题:
qconfig_dtypes.pt不保存算子的fix_scale信息,如果原qconfig里存在fix_scale的算子,需要在加载qconfig_dtypes.pt后再次进行配置。
- 使用LoadFromFileTemplate接口时 enable_optimize 必须配置为 False,因为保存下来的 dtype 一般是优化后的,优化过程不可重入,Load qconfig_dtypes.pt后不再支持对qconfig中dtype的修改。
LoadFromFileTemplate使用示例如下:
3.5 典型场景配置
由于J6系列平台的差异,qconfig的配置自然也会有所区别。本节将结合平台差异,提供新版qconfig模板在典型场景下的配置示例。
3.5.1 J6E/M平台一般配置
J6E/M平台以定点算力为主,在进行混合量化精度调优过程中,建议以全局int8精度为例,针对部分对量化较为敏感的算子,可将其配置为更高的int16精度。以下为配置示例。
配置示例1:全局int8+手动配置量化敏感度高的算子为int16
配置示例2:全局int8+使用敏感度模板配置部分敏感算子为int16
除了手动将部分敏感算子配置为int16,新版qconfig模板提供了SensitivityTemplate,该模板用于将精度debug工具所产出的敏感度列表中,量化敏感度排序topk或者占一定比率ratio的敏感算子,配置为更高的量化精度。相关示例如下:
topk_or_ratio参数的选择:需要用户根据量化精度和部署性能进行权衡,一般来说,配置的高精度算子越多,量化精度越好,而部署性能影响则会越大。
3.5.2 J6P/H 平台一般配置
对于J6 P/H这种有浮点算力的平台,推荐将feature输出配置为fp16+conv和matmul类算子全部配置为int8作为基础配置,然后再将量化敏感的算子配置为int16。如下为配置示例。
配置示例1:基础配置+手动配置量化敏感度高的算子为int16
配置示例2:基础配置+使用敏感度模板配置部分敏感算子为int16
3.5.3 配置算子为float32计算
在做精度调优的时候,有时候想要快速定位引起量化误差的瓶颈,此时会将模型片段或者算子配置为float32计算,如下为将指定模型片段和算子配置为float32计算的示例:
3.5.4 QAT训练时固定激活scale
在QAT精度调优实践中发现(主要是图像分类任务实验),做完calibration后,把activation的scale固定住,不进行更新,即设置
4. 新版qconfig模板迁移
用户在迁移到新版qconfig模板时,建议根据以下情况进行不同的操作:
如果用户部署平台为J6B、J6H和J6P,为了更方便地利用浮点算力,建议使用新版qconfig模板。
如果用户模型从未适配过QAT链路,建议用户直接参考第3章使用新版qconfig模板进行配置。
如果用户模型已经适配过老版本qconfig模板,且在模型迭代中还需要修改qconfig配置,比如增加int16算子等,那么建议用户参考第3章重新进行新版qconfig模板的适配。
如果用户模型已经适配过老版本qconfig模板,且确认在模型迭代中不再需要修改qconfig配置,那么则建议用户按照下面的流程进行迁移工作。
若用户已经稳定使用老版本qconfig模板,而且模型迭代中不需要再修改量化配置,那么建议按照以下流程进行适配:
- 首先,使用SaveToFileTemplate接口保存旧模板下的量化配置文件qconfig_dtypes.pt,其中涵盖每个算子的dtype;
其次,需检查模型中是否存在采用fix_scale的算子。鉴于qconfig_dtypes.pt目前尚不支持保存fix_scale的算子信息,并且新旧模板在fix_scale的配置方面存在差异,若存在fix_scale的算子,那么就必须对新模板下fix_scale的配置进行适配;
- 最后,运用 LoadFromFileTemplate接口加载已保存的 qconfig_dtypes.pt 文件,将量化dtypes配置导入新模板中,从而实现量化配置的迁移衔接。
下面将详细介绍迁移的具体步骤和操作要点。
4.1 保存旧版本的qconfig_dtypes文件
在完成修改并运行后,于args.save_path目录下将会生成包含量化dtype的qconfig_dtypes.pt与qconfig_dtypes.pt.py文件。
4.2 适配fix_scale的配置
4.3 加载 qconfig_dtypes.pt文件
- 对于QconfigSetter(),应将“enable_optimize”参数配置为“False”,以此避免启用任何新版本中的默认优化。
- 针对LoadFromFileTemplate(),务必将“only_set_mod_in_graph”参数配置为“False”。原因在于,在老版本配置中,存在对非graph中的操作进行qconfig设置的情形。
- 在执行prepare操作时,需将“fuse_mode”参数配置为“FuseMode.BNAddReLU”,进而实现与老版本行为的对齐。
以下为完整的使用示例:



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
