
强化学习+多目标优化
传统多目标优化里,怎么平衡目标权重一直是个老大难的问题。现在的前沿玩法是用深度强化学习框架,让智能体动态学习目标间的权衡策略,自适应调整各目标的优化权重。
参考论文:
Constrained Multi-objective Optimization with Deep Reinforcement Learning Assisted Operator Selection(一区TOP)
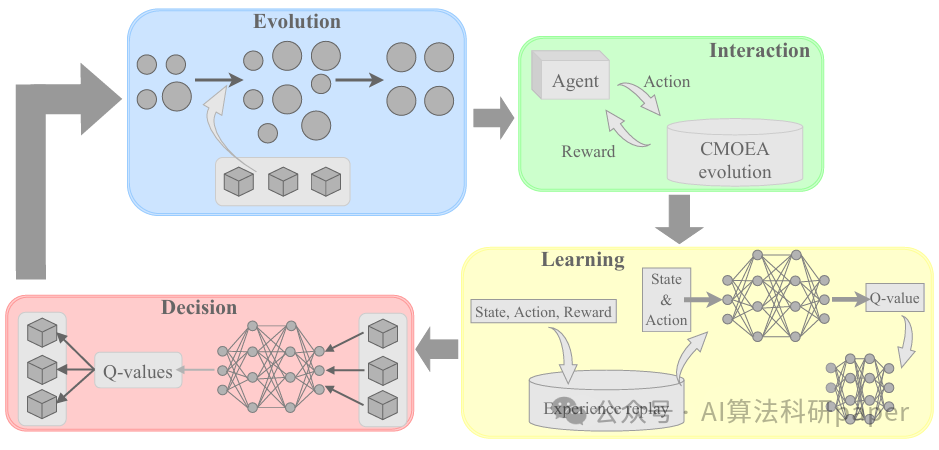
创新点:
以种群收敛性/多样性/可行性为状态,进化算子作为动作,改进效果定奖励,训练深度Q网络智能选算子。
框架兼容各类约束多目标进化算法,支持多候选算子自适应切换。
相比现有方法,能综合考虑约束满足和未来优化潜力,显著提升算法性能和跨问题通用性。
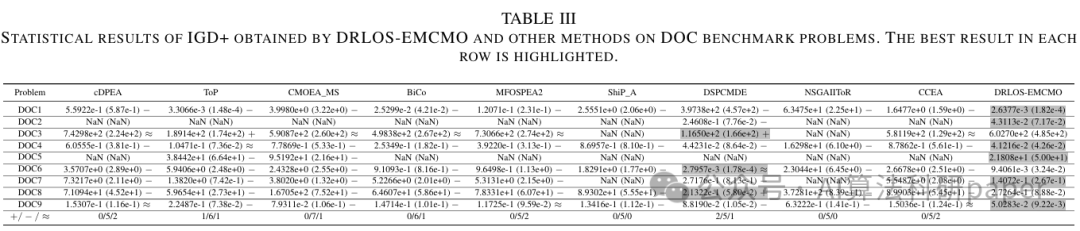
元学习+多目标优化
人工设定目标权重的局限性太明显了,所以自适应权重分配成了刚需。最新的梯度基多目标双层优化算法,靠元学习机制让模型从历史优化过程里学经验,掌握不同任务的目标重要性模式。
具体点讲就是搭个元学习器来预测任务特定的权重分布,根据任务特征自动调整目标优先级。
参考论文:
Predictive model-based multi-objective optimization with life-long meta-learning for designing unreliable production systems
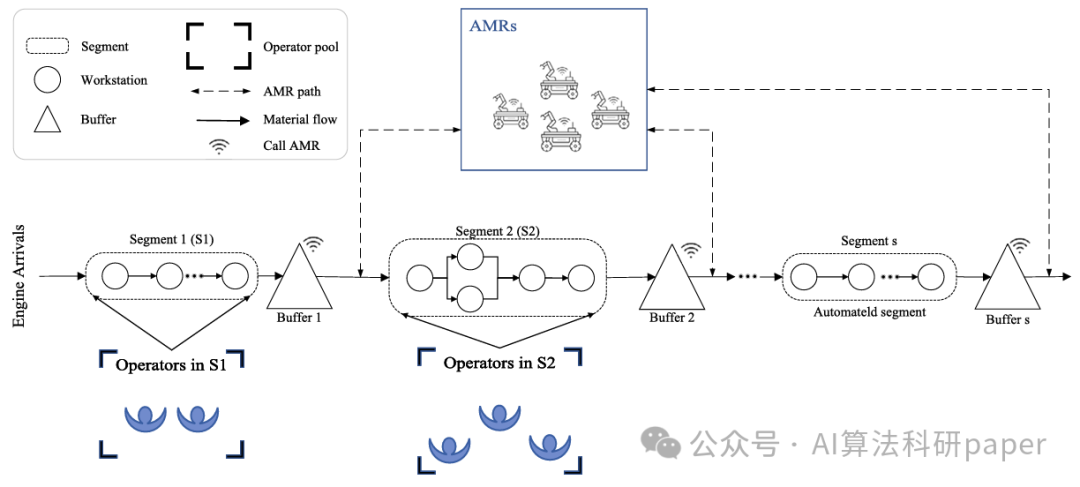
创新点:
将终身元学习融入增强型非支配排序遗传算法,动态调整参数以提升解空间探索能力。
用随机森林回归器替代离散事件仿真作为预测模型,构建多目标优化框架降低计算成本。
通过模式挖掘从优化结果中提取缓冲区和资源分配的实用规则,提供管理指导。
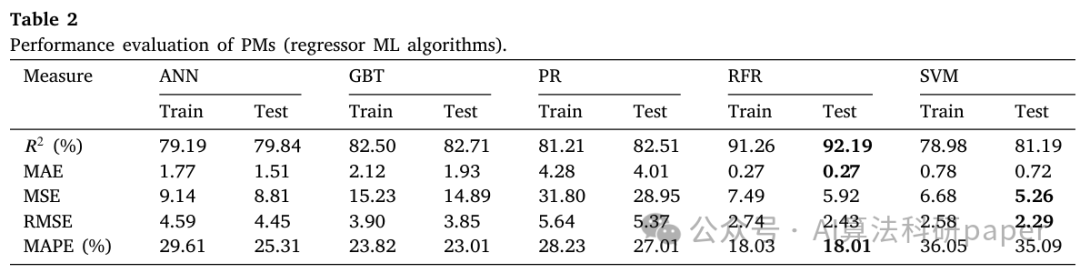
GNN+多目标优化
如何处理目标间的复杂关系?图神经网络yyds!把每个目标当成图节点,目标间的相关性和约束关系做成边,用 GNN 学目标间的深层次依赖关系。这种方法尤其适合有层次结构或网络拓扑的多目标问题。
参考论文:
Graph-Supported Dynamic Algorithm Configuration for Multi-Objective Combinatorial Optimization
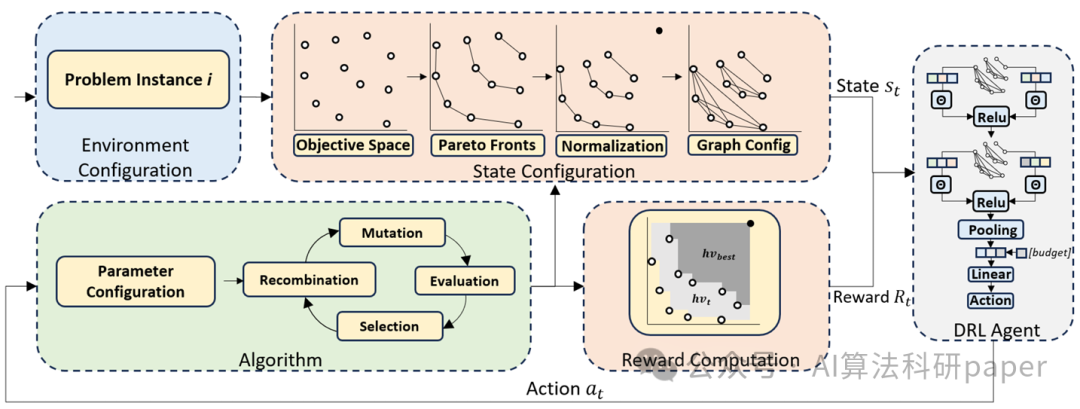
创新点:
用图神经网络将多目标优化的解转化为图结构,自动学习解的状态特征。
基于超体积改进设计奖励函数,通过强化学习动态调整多目标算法参数。
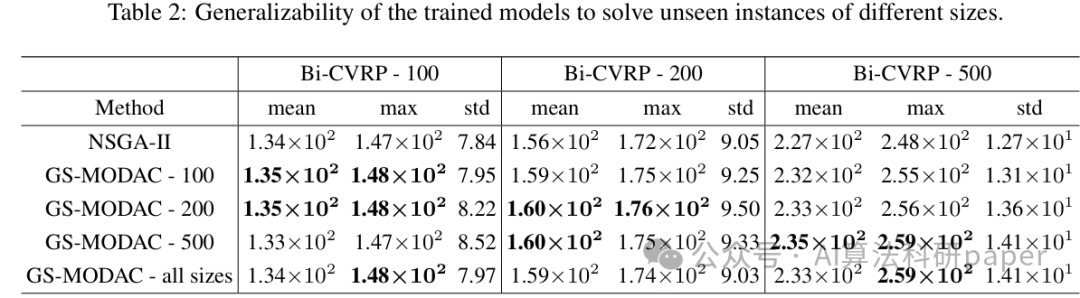
在调度和路径问题中对复杂、大规模问题表现出更好的适应性和泛化能力。

GAN+多目标优化
有没有遇到过优化问题里多个目标打架的情况?多目标组合生成对抗优化算是种新的解题思路。简单说就是生成器负责产生候选解,判别器评估解在不同目标下的质量,通过对抗训练实现目标间的动态平衡。
参考论文:
Accelerating multi-objective optimization of concrete thin shell structures using graph-constrained GANs and NSGA-II
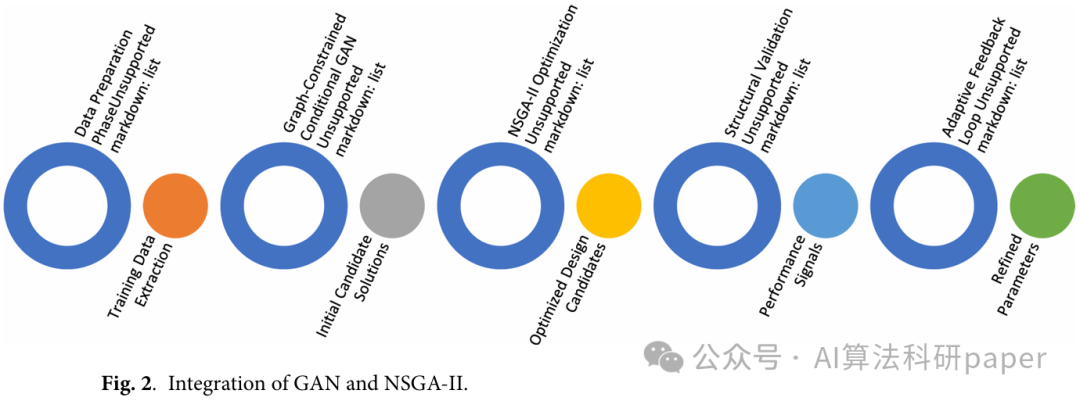
创新点:
结合图约束GAN与NSGA-II,用GAN生成符合拓扑约束的初始设计,提升优化起点质量。
以重量、挠度和应变能为优化目标,通过NSGA-II维护帕累托最优解的多样性与收敛性。
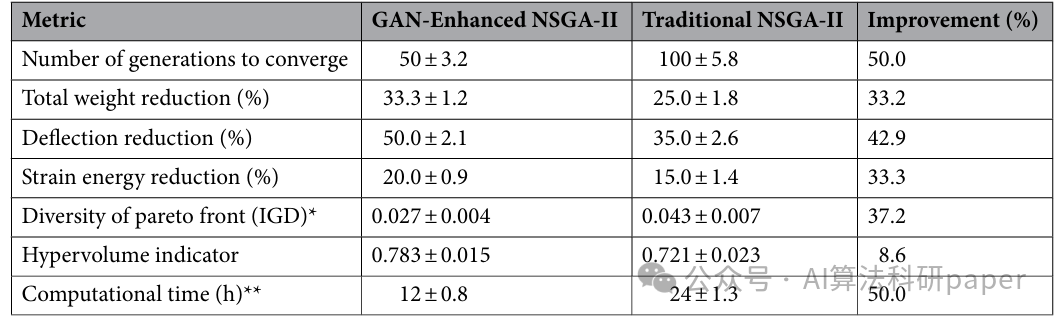
实际案例中性能显著提升,收敛速度比传统方法快50%,结构完整性经验证可靠。
自监督学习+多目标优化
现在好多场景都缺标注数据,人工标数据又贵又慢,如何做多目标优化?自监督学习来救场!具体说就是用自编码器这类无监督学习技术,从数据内在结构里发现潜在的优化目标,再进行联合优化。
参考论文:
BarlowWalk: Self-supervised Representation Learning for Legged Robot Terrain-adaptive Locomotion
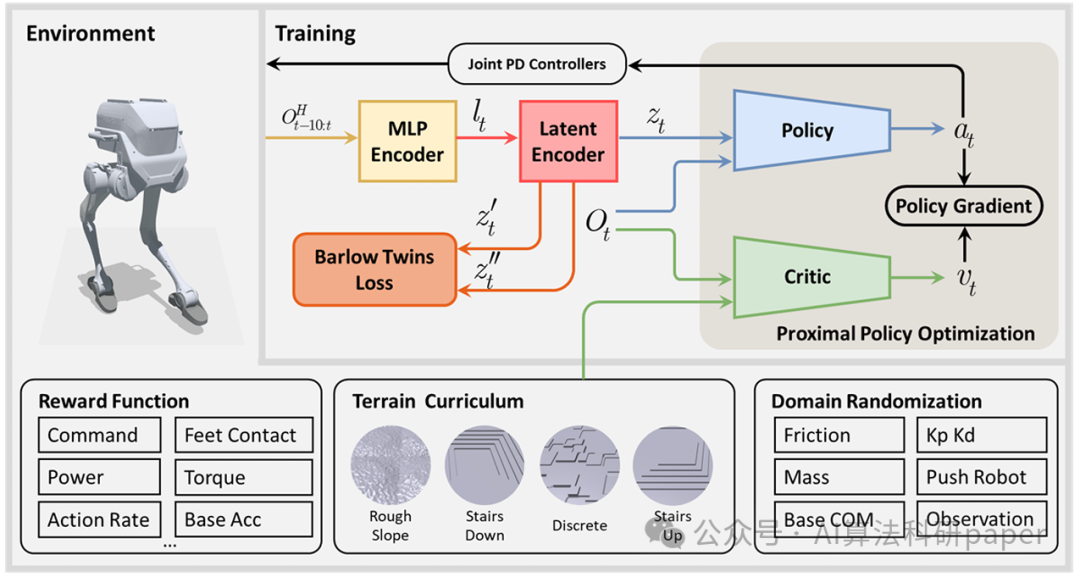
创新点:
用Barlow Twins自监督学习从历史本体感知数据中提取运动特征,减少对外部地形感知的依赖。
设计多目标奖励函数,结合不对称架构实现策略与评论网络的差异化训练。
无需知识蒸馏,仅靠本体感知就让机器人在复杂地形稳定行走,跟踪误差低且收敛稳定。

总的来说,这几个创新方向各有亮点,都是比较推荐多目标优化领域的论文er做的,如果想快点出成果,那就可以重点关注起来啦!
文章转载自公众号:AI算法Paper
原文链接:https://mp.weixin.qq.com/s/h_OFf_I0HyJQr_EYlXUi0w

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)