
1. 前言
本文旨在提供 J6E/M 计算平台的部署指南,将会从硬件、软件两部分进行介绍,本文整理了我们推荐的使用流程,和大家可能会用到的一些工具特性,以便于您更好地理解工具链。某个工具具体详细的使用说明,还请参考用户手册。
2. J6EM硬件配置

| BPU | DSP
| |||||
|---|---|---|---|---|---|---|---|
| 算力 | TAE浮点输出 | VAE浮点 | VPU | SPU | APM |
|
J6E | 80T | N | N | Y | Y | Y | Q8*1 |
J6M | 128T | N | N | Y | Y | Y | Q8*1 |
J6P | 560T | Y | Y | Y | Y | Y | Q8*2 |
J6H | 420T | Y | Y | Y | Y | Y | Q8*2 |
J6B-Base | 18T | Y | Y | N | N | Y | V130*1 |
BPU内部器件:
- TAE:BPU 内部的张量加速引擎,主要用于 Conv、MatMul、Linear 等 Gemm 类算子加速,支持 int8/int16 输入,int8/int16/int32 输出(仅模型输出层支持 int32 输出)
- AAE:Pooling、Resizer、Warping 等偏专用单元的集合,其中 Warping 可用于加速 Gridsample 等算子
- DTE:BPU 内部的数据排布变换引擎,支持各种维度的高效变换
- VAE:BPU 内部的 SIMD 向量加速引擎,可用于加速 Add、Mul、查表等 Vector 计算
- VPU:BPU 内部的 SIMT 向量加速单元,J6EM 可用于实现 Quantize、Dequantize 等算子
- SPU:BPU 内部的 RISC-V 标量加速单元,J6EM 可用于实现 TopK 等算子
- APM:BPU 内部另一块 RISC-V 标量加速单元,主要用于 BPU 任务调度等功能
3. J6EM工具链简介
3.1 模块架构图
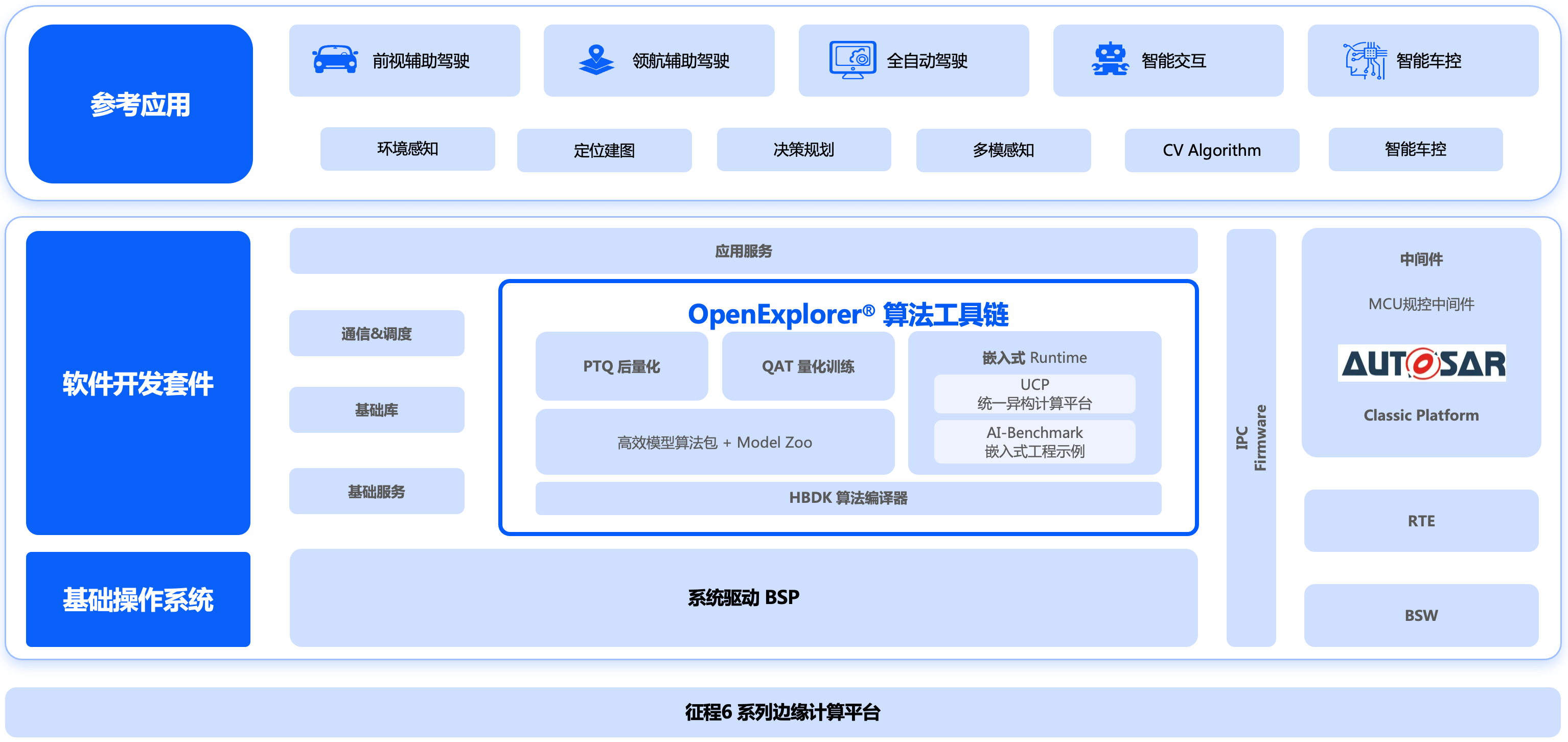
- PTQ:J6 工具链基于horizon_tc_ui 包封装的 hb_compile 命令行工具,提供 ONNX 模型 PTQ 全流程转换能力,其内部会先调用 hmct 包实现模型解析、图优化、校准功能,再调用 hbdk4_compiler 包实现模型的定点化和编译功能;
- QAT:J6 工具链基于 horizon_plugin_pytorch 包提供量化感知训练能力;
- HBDK:J6 工具链编译器,基于hbdk4_compiler 包提供模型定点化、图修改、模型编译、静态 perf 等功能;
- 高效模型算法包:J6 工具链基于 horizon-torch-samples 包,以源码开放形式提供了多场景参考算法,这些模型基于开源数据集训练,模型结构贴合地平线芯片进行了高效且用户友好的设计,并基于 QAT 链路实现了模型的量化转换;
- UCP:J6 工具链统一计算平台,通过一套统一的异构编程接口实现了对 J6 计算平台相关计算资源的调用,提供视觉处理、模型推理、高性能计算库、自定义算子插件开发等功能;
- AI-Benchmark:J6 工具链基于预编译好模型提供的嵌入式工程示例,可实现模型的性能评测和精度评测。
3.2 两套模型转换链路
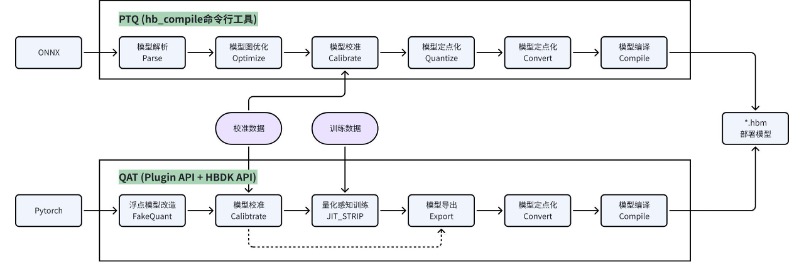
J6EM 工具链支持 PTQ(训练后量化)、QAT(量化感知训练)两套模型转换链路,其特性和优缺点如下:
- PTQ:基于 hb_compile 命令行工具转换模型,配置好 yaml、校准数据集后,可一步实现模型的图优化、校准、量化、编译全流程。该量化方式快捷易用,但仅基于数学统计的方式量化不利于模型迭代,且可能会触发难以解决的 corner case,因此在量产项目中通常用于早期评测和简单模型的量化。
- QAT:在 PyTorch 开源框架上,基于 plugin 插件的形式提供模型量化能力,并调用 hbdk 编译器的 API 实现模型的定点化和编译。该链路支持模型校准后进一步的 finetune 训练,虽然上手难度和训练成本都较高,但精度上限也更高,更利于模型迭代优化,是量产项目中的更优选择。
3.3 工具链推荐使用流程
鉴于两条量化链路的特性,我们建议的工具链使用流程如下:
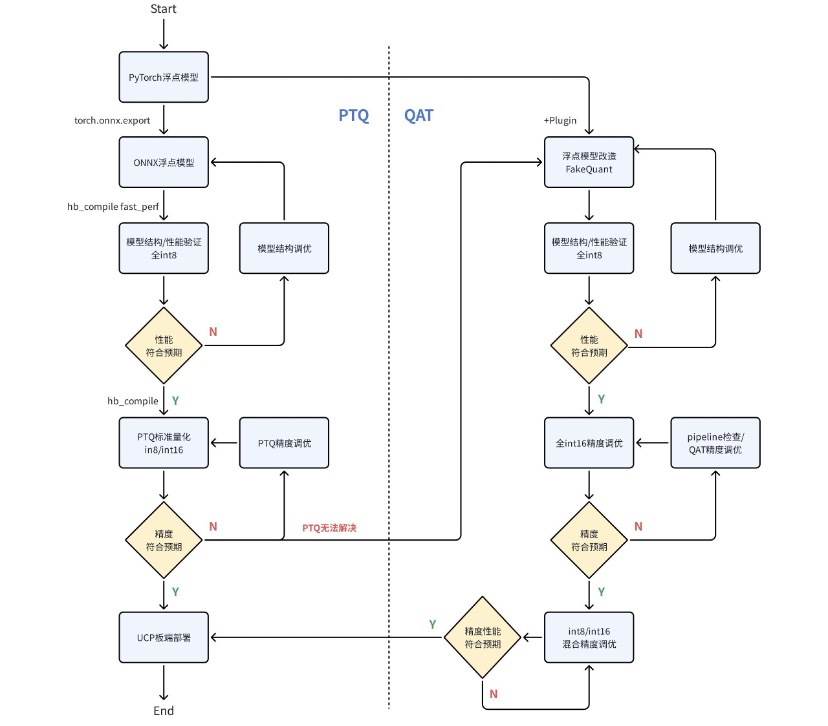
- Step1:先导出浮点 ONNX 模型(opset10~19),并基于 PTQ 链路进行快速的模型结构验证,全 int8 性能上限验证;若该性能符合预期,则可以精调 PTQ,若最终精度/精度都可同时满足预期,则可进行板端部署。
- Step2:如果遇到 PTQ 无法解决的精度 corner case,则需要转到 QAT 链路进行量化。依然建议先进行模型结构验证和全 int8 性能上限验证;若该性能符合预期,则优先在全 int16 配置下将精度训练至符合预期,然后再降低 int16 比例,实现 int8/int16 混合精度下的性能/精度调优,最终进行板端部署。
在以上推荐链路中:
- PTQ 链路的模型结构验证和标准量化,可在 X86 端参考本文 4.2 节使用 hb_compile 命令行工具;
- 模型性能分析和验证,可在 X86 端参考本文 6.4 节《静态perf》使用 hbm_perf 接口生成 html 分析文件,可在板端参考本文 8.2.1 节使用 hrt_model_exec 工具;
- 模型推理,可在 X86 端参考用户手册《训练后量化-PTQ转换工具-HBRuntime推理库》,可在板端参考本文第 8 章《模型板端部署》使用 UCP 推理接口;
模型性能/精度调优,请见后续文章的详细介绍。
4. PTQ链路
4.1 模型转换流程
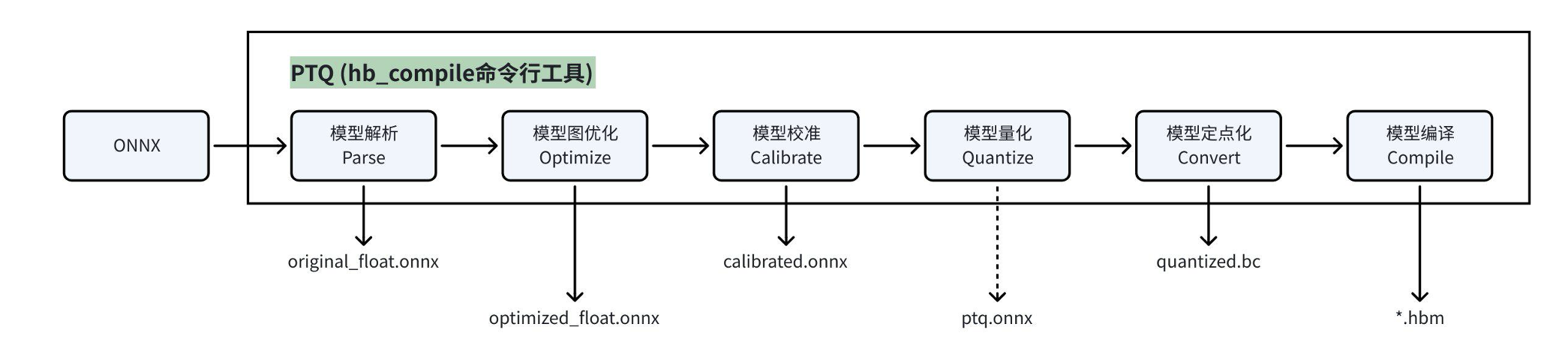
4.2 hb_compile工具
hb_compile --march nash-m -m xxx.onnx | 模型检查,用于早期确认是否有 J6E/M 不支持的结构或算子 |
hb_compile --march nash-m -m xxx.onnx --fast-perf
| 快速性能评测,用于验证性能上限,工具会生成在板端运行性能最高的模型,工具内部主要会执行:
该功能执行后会在 .fast_perf 隐藏文件夹下生成一个 yaml 文件,您可以在其基础上做二次修改复用。 |
hb_compile -c config.yaml | 标准模型转换流程,精调模型性能/精度 |
4.3 PTQ模型产出物
original_float.onnx | 浮点 | 对 Caffe1.0 模型进行解析,转成 ONNX |
optimized_float.onnx | 浮点 | 图优化,例如 BN 融合到 Conv |
calibrated.onnx | 伪量化 | 插入校准节点,并基于校准数据计算统计到每个节点的量化参数 |
ptq.onnx | 查表算子定点+其他算子伪量化 | 将查表算子定点化 |
quantized.bc | 定点 | 整个模型定点化,并转换为地平线 hbir 中间表达 |
hbm | 指令集 | 经过编译后的最终部署模型 |
4.4 PTQ精度配置方法
4.5 PTQ精度调优流程
5. QAT链路
5.1 模型转换流程
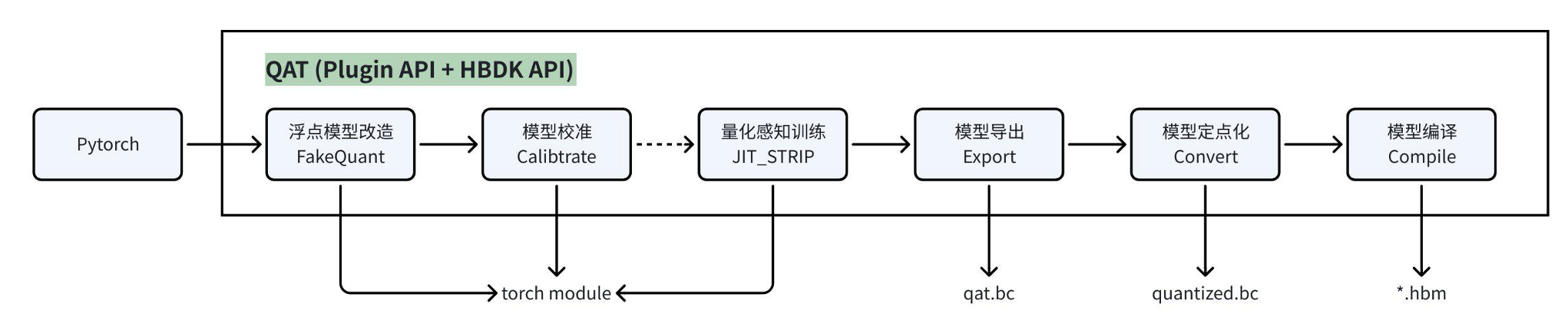
- 浮点模型改造:在模型前插入 QuantStub、在模型后插入 DequantStub,用于识别模型首尾部,剥离前后处理
- 模型校准:通过在模型中插入 Observer 的方式,在 forward 过程中统计各处的数据分布,以计算出量化参数
部分模型仅通过 Calibration 便可满足精度要求,则无需进行 QAT,可直接编译模型用于部署
即使 Calibration 无法满足精度要求,也可降低后续 QAT 难度,缩短训练时间,提升最终训练精度
- 量化感知训练:进一步通过训练的方式微调模型参数,如果 Calibration 精度较好,则推荐固定激活 scale
JIT-STRIP:使用 hook 和 subclass tensor 的方式感知图结构,在原有 forward 上做算子替换/算子融合等操作,并且会根据模型中 QuantStub 和 DequantStub 的位置识别并跳过前后处理
优点:全自动,代码修改少,屏蔽了很多细节问题,便于 debug
缺点:动态代码块仍需要特殊处理
5.2 QAT精度配置方法
请见后续文章。
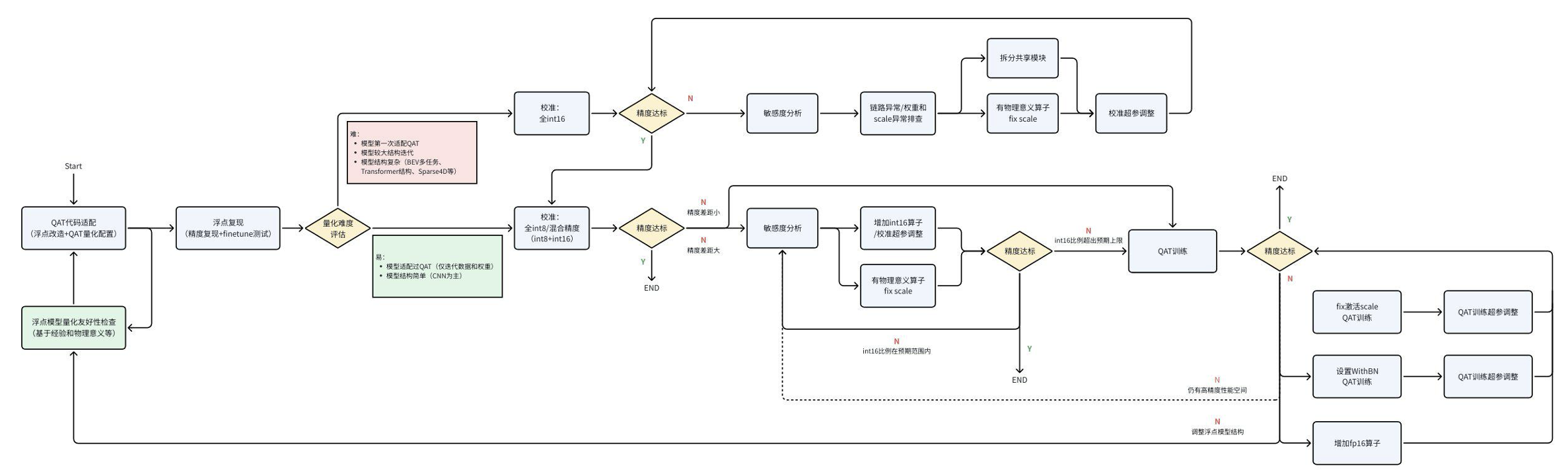
5.3 QAT精度调优流程
6. 模型导出/定点化/编译
6.1 PTQ链路
6.1.1 输入/输出去padding
模型在 BPU 上推理时,其输入和输出节点的内存大小和数据存放规则需满足硬件对齐要求。
6.2 QAT链路
QAT 链路的模型定点化和编译直接调用如上的编译器接口,模型导出额外封装了一层,参考代码如下:
6.3 模型修改
编译器支持在 hbir 上进行多 batch 拆分、插入数据前处理、算子删除、调整输入输出 layout 等修改操作,其主要应用场景如下:
以下参考代码对一个多输入模型实现了多 batch 输入拆分、图像输入的色彩空间转换、数据归一化、Resizer 功能:
6.4 静态perf
对于编译好的 hbm,编译器支持在 X86 端对其 BPU 部分进行静态性能预估,执行以下命令即可生成一个 html 文件,包含模型预估性能、带宽、内存占用、BPU内部单帧执行时序图等信息。
7. 浮点能力使用
7.1 硬件支持能力
在 OE-3.5.0 正式版本中,工具链已默认开启 BPU 已支持浮点算子的加速能力,用户仅需在 PTQ/QAT 链路中,将对应算子的量化精度配置为浮点即可使用。
7.2 量化/反量化处理
在 J6EM 平台,因为 VPU 浮点能力的加持,建议模型首尾部的量化/反量化算子可优先尝试将其保留在模型中。
编译器也同时支持使用以下接口将 quantized.bc 模型首尾部的量化/反量化节点移除,但移除后建议参考该篇文章(反量化节点的融合实现)将其融合进前后处理代码中,以减少一次数据遍历的冗余开销。
8. 模型板端部署
8.1 UCP简介
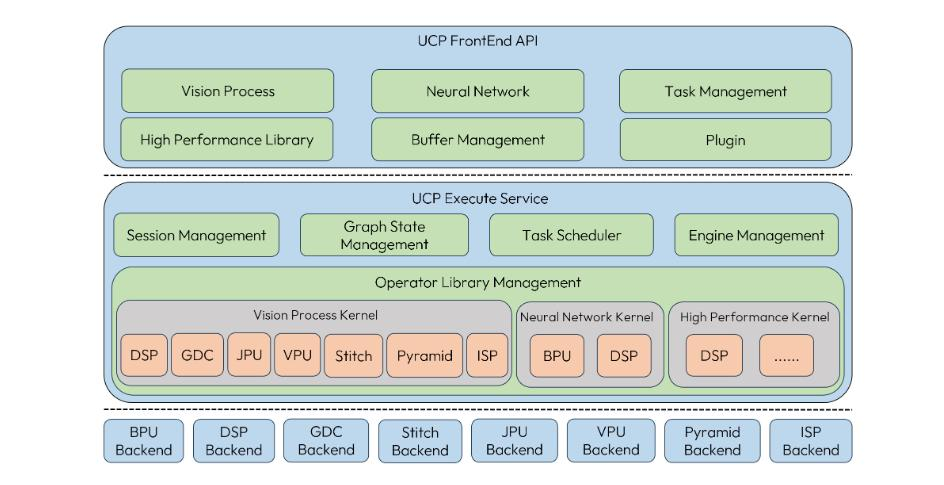
UCP 支持的 Backend 如下:

8.2 快速上手
8.2.1 hrt_model_exec工具
hrt_model_exec 的三种使用方法如下:
8.3 图像输入动态shape/stride
在 J6 芯片的视频通路上,有一块叫 Pyramid 的金字塔硬件处理模块,可提供 Camera 输入图像的缩放及 ROI 抠图能力,其输出为 nv12 类型的图像数据,并可基于共享内存机制直接给到 BPU 进行模型推理。因此在 J6 工具链中:
Pyramid 模型指的是具有 nv12 图像输入的模型;
Resizer 模型指的是具有 nv12 图像输入和 ROI 输入的模型,编译器支持通过 JIT 动态指令的方式,从 nv12 图像上完成 ROI 抠图 + Resize 的功能。
在 J6 工具链中,Pyramid 的输入 stride 为动态,Resizer 模型的 stride 和 shape 都是动态。如下为 mobilenetv1 编译后的模型信息:
| Pyramid | Resizer |
hb_model_info X86端命令行工具 | 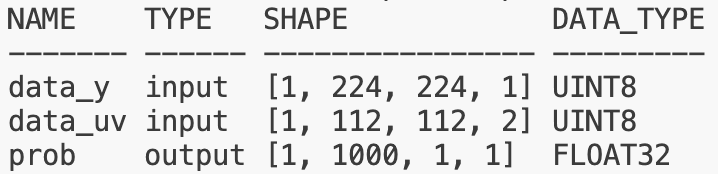 |  |
hrt_model_exec model_info 板端可执行程序工具 |  |  |
其中,-1 为占位符,表示为动态,Pyramid 输入的 stride 为动态;Resizer 输入的 H、W、stride 均为动态。
- Resizer 输入的 HW 动态,是因为原始输入的大小可以是任意的;
- Pyramid/Resizer 输入的 stride动态,可以理解为是支持 Crop 功能,详细内容可参考用户手册《统一计算平台-模型推理开发-基础示例包使用说明-advanced_samples-crop》
8.4 非图像tensor内存对齐
对于非图像 tensor,J6EM 要求内存 64 对齐,J6B 要求 128对齐,J6PH 要求 256 对齐。如上图所示,模型输出节点虽然 stride[0] 为 4000,但需要申请的 BPU 内存大小(aligned byte size)为 4032,即为 64 对齐的结果。
8.5 图像tensor跨距对齐
J6EMB 对于 Pyramid/Resizer 模型的图像输入,要求 W32 对齐,J6PH 要求 W64 对齐。若您有 J6 不同架构平台迁移的场景,请注意跨距对齐要求的差异。
部署代码建议您避免 hard code,推荐基于模型节点属性中的 validShape(张量有效内容尺寸)和 stride(张量各维度步长)进行解析和使用。
8.5.1 Pyramid输入
Pyramid 输入 tensor 准备的参考代码如下:
示例:
视频通路上的金字塔硬件,其输出层支持配置 y、uv 的 stride,但仅要求 W16 对齐,若数据需要喂给 BPU 推理模型,建议直接按 BPU 的跨距对齐要求来配置。金字塔硬件的更多信息请参考系统软件用户手册。
8.5.2 Resizer输入
Resizer 输入的 H、W 也是动态的,因此需要设置为原图尺寸,并计算好 W32 对齐的 Stride;ROI 作为模型输入节点,也需要对其进行赋值。以下为参考代码:
示例:
8.6 小模型批量处理功能
由于 BPU 是资源独占式硬件,所以对于 Latency 很小的模型而言,其框架调度开销占比会相对较大。在 J6 平台,UCP 支持通过复用 task_handle 的方式,将多个小模型任务一次性下发,全部执行完成后再一次性返回,从而可将 N 次框架调度开销合并为 1 次,以下为参考代码:
8.7 优先级调度/抢占
- priority > customId > submit_time(任务提交时间)
- priority 支持 [0, 255],对于模型任务而言:
[0, 253] 为普通优先级,不可抢占其他任务,但在未执行时支持按优先级进行排队
254 为 high 抢占任务,可支持抢占普通任务
255 为 urgent 抢占任务,可抢占普通任务和 high 抢占任务
- 可被中断抢占的低优任务,需要在模型编译阶段配置 max_time_per_fc 参数拆分模型指令
其他 backend 任务,priority 支持 [0, 255],但不支持抢占,可以认为都是普通优先级
8.8 直连/中继模式
UCP 框架还支持两种主要工作模式:直连模式、中继模式。系统默认运行在直连模式下,在中继模式下,UCP 将支持多进程任务的统一调度,即支持 priority 为 [0, 253] 的普通优先级任务的跨进程统一调度。
注意:
中继模式虽然可支持用户统一调度多进程间任务,但是也存在一些缺陷,包括:
需要做进程间通信和内存共享,整体的 CPU 负载更高;
模型任务底层资源的竞争都发送于 Service 进程内,相较于直连模式多个独立进程的竞争强度更高,任务的耗时可能受到影响。
8.9 X86仿真
J6 工具链在 X86 端支持 hbm 指令仿真,但效率非常低,所以更推荐使用 quantized.bc 模型进行推理,其定点部分和 hbm 数值二进制一致,浮点部分可能存在架构本身差异,但通常对精度影响可忽略不计。
推理quantized.bc
Python推理:
quantized.bc 也可以直接调用其 func 的 feed 接口进行推理,其输入格式也为 dict,value 支持 torch.tensor 和 np.array 两种类型,输出格式与输入格式保持一致。参考代码如下:
C++推理:
推理hbm
9. UCP视觉处理/高性能算子
除模型推理外,UCP 还提供了视觉处理和高性能算子两大方向的多种算子接口,可支持诸如 Remap、Jpeg、H264/265、FFT/IFF 等功能,这些算子底层是基于地平线 SOC 上不同硬件 IP 进行的封装,并提供统一的调用接口。
注意:
板端实际部署时,ISP 到 Pyramid 的视频通路不建议使用 UCP,无法实现数据 Online,建议直接调用底软接口进行功能实现。
10. UCP自定义算子(DSP)
为了简化用户开发,UCP 封装了一套基于 RPC 的开发框架,来实现 CPU 对 DSP 的功能调用,但具体 DSP 算子实现仍是调用 Cadence 接口去做开发。总体来说可分为三个步骤:
使用 Cadence 提供的工具及资料完成算子开发;
DSP 侧通过 UCP 提供的 API 注册算子,编译带自定义算子的镜像;
ARM 侧通过 UCP 提供的算子调用接口,完成开发板上的部署使用。
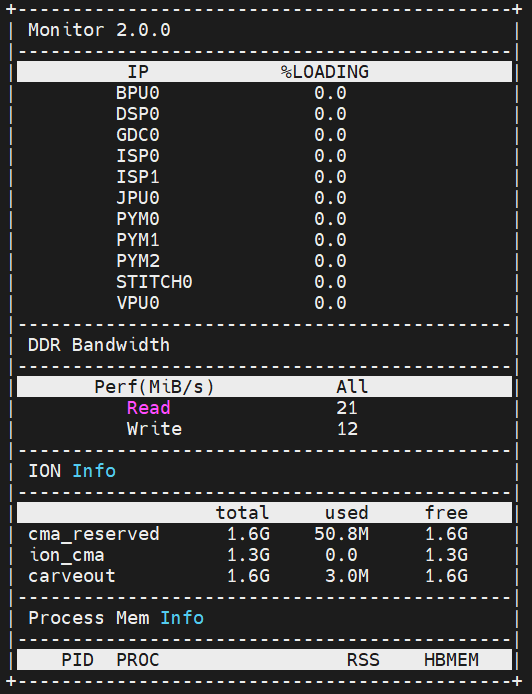
11. 性能监测工具



'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)