
前言
在开始正文前,我先带着大家回顾两篇文章:【手撕大模型】KVCache原理及代码解析和【手撕大模型】MQA和GQA原理解析。我们都知道,KV cache是为了在推理时避免重复计算前面的序列,从而提升性能。不难想象,当前面序列的长度变长,也就是KV cache的数据量越来越大时,数据加载和存储的成本也会增加,这时内存占用就会成为Attention计算的限制因素,严重制约了模型的运行效率和可扩展性。。在这种情况下,多查询注意力(MQA)和分组查询注意力(GQA)就出现了。
MQA和GQA工作原理
我们这里先回顾一下 MQA和GQA的工作原理,如下图所示:
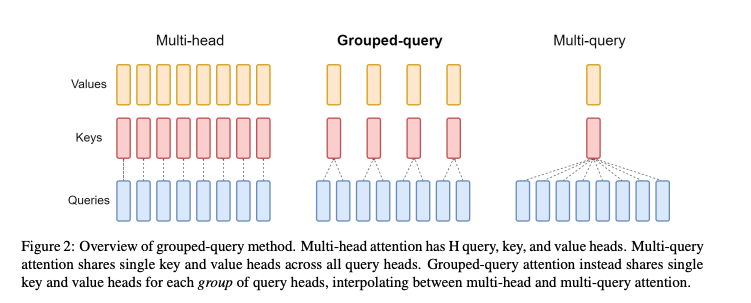
在MQA里,一个token的所有注意力头(heads)都共用相同的键(k)和值(v)。这样做既能减少参数权重的大小,还能把原本要保存的多份键值缓存(kv cache)减少到只需保存1份。不过,这是在牺牲精度来换取性能的,MQA可能会让模型的效果变差。因为原本一个token的每个注意力头都有自己的键和值信息,现在却被压缩成了一份。
所以,GQA作为一种折中的办法出现了。它把一个token的注意力头分成若干组,每组内的注意力头共用相同的键和值信息,这样信息压缩的程度就没有MQA那么大。
很明显,MQA和GQA都是通过压缩K、V信息来提高推理效率的,但这样做肯定会造成信息损失。那么,如果想在不大量压缩K、V信息的同时,还能提高推理速度,应该如何做呢?
下面我们来介绍一下多头潜在注意力,Multi - Head Latent Attention,MLA)。
MLA核心设计思想
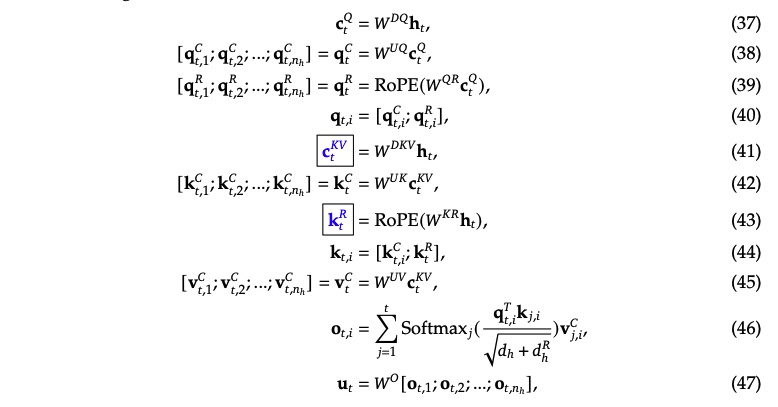
公式中蓝色的部分是缓存的向量。我们首先来介绍一下公式中关键参数的意义:
$$d_h $$:单个head的向量维度,论文中配置为128
$$d_c $$:MLA低秩压缩的维度,论文中取值为$$d_c=4\times d_h $$
$$d_q $$:MLA中Q低秩压缩的维度,论文中取值为$$d_q=1536 $$
$$n_h $$:每层head的数量
$$d $$:隐含层的维度,$$d=d_h \times n_h $$
$$W^{DKV} \in \mathbb{R} ^{d_c \times d} $$:低秩变换矩阵
KV 低秩变换
KV的生成过程如下面的公式41所示,其作用是通过低秩变换矩阵$$W^{DKV} $$把输入$$h_t$$的维度由$$d$$压缩到$$d_c$$维度的$$c_t ^{KV}$$:

DeepSeek-V3中$$d=7168,d_c=512$$.
获得$$c_t ^{KV}$$后,进行公式42和45的计算,即使用变换矩阵$$W^{UK},W^{UV}\in \mathbb{R}^{d \times d_c}$$把压缩后的KV维度扩展回$$d=d_h \times n_h$$,即和原始MHA的状态相同:


上述操作借助低秩变换矩阵先进行压缩,然后再进行扩展,最终能够降低参数量。然而,MLA的本质在于减少KV-cache的存储。LoRA着重于参数量的减少,类似MLA的操作确实也实现了参数量的降低。按照DeepSeek-V3的参数配置,两个低秩矩阵的参数量为 $$2 d d_c =2*7168*512 $$,而正常MHA的参数矩阵参数量为 $$2 d d =2*7168*7168 $$,可以看出确实是减少了参数量。
Q低秩变换
Q的低秩变换可以参考公式37,38,与KV类似,分别使用变换矩阵$$W^{DQ},W^{UQ}\in \mathbb{R}^{d \times d_q}$$做压缩和扩展中,这里就不赘述了。
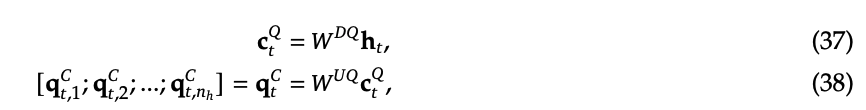
RoPE
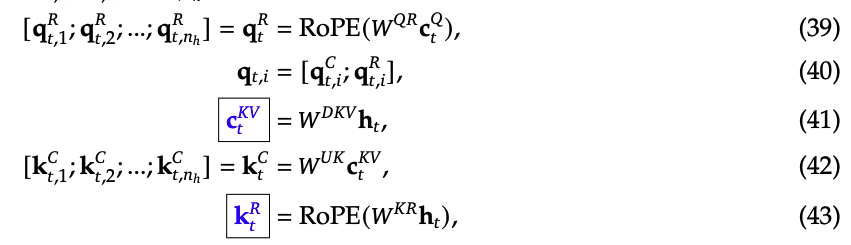
RoPE 操作可以参考公式39,43,稍微细心点可以发现,RoPE并不少针对扩展后的$$q_t ^C,k_t ^C$$来做的,而是单独计算了带有位置编码的$$q_t ^R,k_t ^R$$,论文中配置$$q_t ^R,k_t ^R$$维度$$d_h^R=d_h/2=64$$,DeepSeekv2中每层head的数量$$n_h$$也是64,所以这部分事实上是MQA的实现,即同一层中所有的Head共享一个key。
然后按照公式40、44跟已经计算好的$$q_t ^C,k_t ^C$$做concat,构成完整的$$q_t ,k_t $$向量。


DeepSeekV2为什么不直接对$$q_t ^C,k_t ^C$$做RoPE呢?
我们首先来看一下论文中的描述:

论文中提到的矩阵吸收计算指的是$$(Px)^T \cdot Qy=x^T(P^TQ)y$$,这里相当于说把$$P^T$$吸收到是$$Q$$里。

DeepSeekV2如何实现RoPE的?
公式40,44显示DeepSeek在一个小维度向量下实现了RoPE,然后在于低秩变换后的向量做concat(concat后是广义的三角阵),这里的小维度向量是MQA计算得出的。所以在计算注意力权重时,根据三角阵的计算规则:
$$[q_{t,i}^C;q_{t,i}^R]^T \times[k_{j,i}^C;k_{t}^R]=q_{t,i}^C k_{j,i}^C+q_{t,i}^Rk_{t}^R$$
这里$$q_{t,i}^C k_{j,i}^C$$由于没有因为相对位置编码出现的变化,所以将变换矩阵$$(W^{UQ})^T W^{UK}$$进行吸收处理,所以每个head只需要缓存一个$$c_t ^{KV}$$;$$q_{t,i}^Rk_{t}^R$$由于是经过了RoPE的MQA,每个head只需要缓存一个key即可。
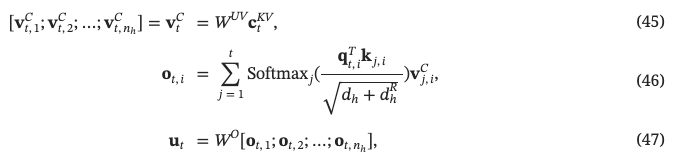
至此,笔者就以DeepSeekv2为例完成了MLA优化KV Cache原理的介绍。
MLA与MHA、MQA、GQA复杂度分析
MHA (Multi-Head Attention)

MQA (Multi-Query Attention)

GQA (Grouped-Query Attention)

MLA (Multi-Head Latent Attention)

复杂度对比

参考链接
deepseek技术解读(1)-彻底理解MLA(Multi-Head Latent Attention)
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)