
简介
Qwen3-2507
泛化能力显著提升,涵盖 指令遵循、逻辑推理、文本理解、数学、科学、编码以及工具使用。
长尾知识覆盖在多种语言上大幅增强。
在主观和开放式任务中与用户偏好的契合度明显提高,能够生成更有用的回复和更高质量的文本。
在 25.6 万长上下文理解方面能力增强,可扩展至 100 万。
Qwen3-Thinking-2507具备以下特点:
推理任务性能显著提升,涵盖逻辑推理、数学、科学、编码以及通常需要人类专业知识的学术基准测试——在开源thinking模型中取得了领先的成果。
泛化能力显著增强,如指令遵循、工具使用、文本生成以及与人类偏好的一致性。
256K长上下文理解能力得到强化,可扩展至1M。
Qwen3-2504(Qwen3)
全尺寸稠密与混合专家模型:0.6B, 1.7B, 4B, 8B, 14B, 32B and 30B-A3B, 235B-A22B
支持在**思考模式**(用于复杂逻辑推理、数学和编码)和 非思考模式 (用于高效通用对话)之间**无缝切换**,确保在各种场景下的最佳性能。
显著增强的推理能力,在数学、代码生成和常识逻辑推理方面超越了之前的 QwQ(在思考模式下)和 Qwen2.5 指令模型(在非思考模式下)。
卓越的人类偏好对齐,在创意写作、角色扮演、多轮对话和指令跟随方面表现出色,提供更自然、更吸引人和更具沉浸感的对话体验。
擅长智能体能力,可以在思考和非思考模式下精确集成外部工具,在复杂的基于代理的任务中在开源模型中表现领先。
支持 100 多种语言和方言,具有强大的多语言理解、推理、指令跟随和生成能力。
Qwen模型结构解析
本节以qwen3_moe代码为例,解析一下结构。
代码路径:https://github.com/huggingface/transformers/blob/main/src/transformers/models/qwen3_moe/modeling_qwen3_moe.py
配置文件:https://github.com/huggingface/transformers/blob/main/src/transformers/models/qwen3_moe/configuration_qwen3_moe.py
总体网络结构
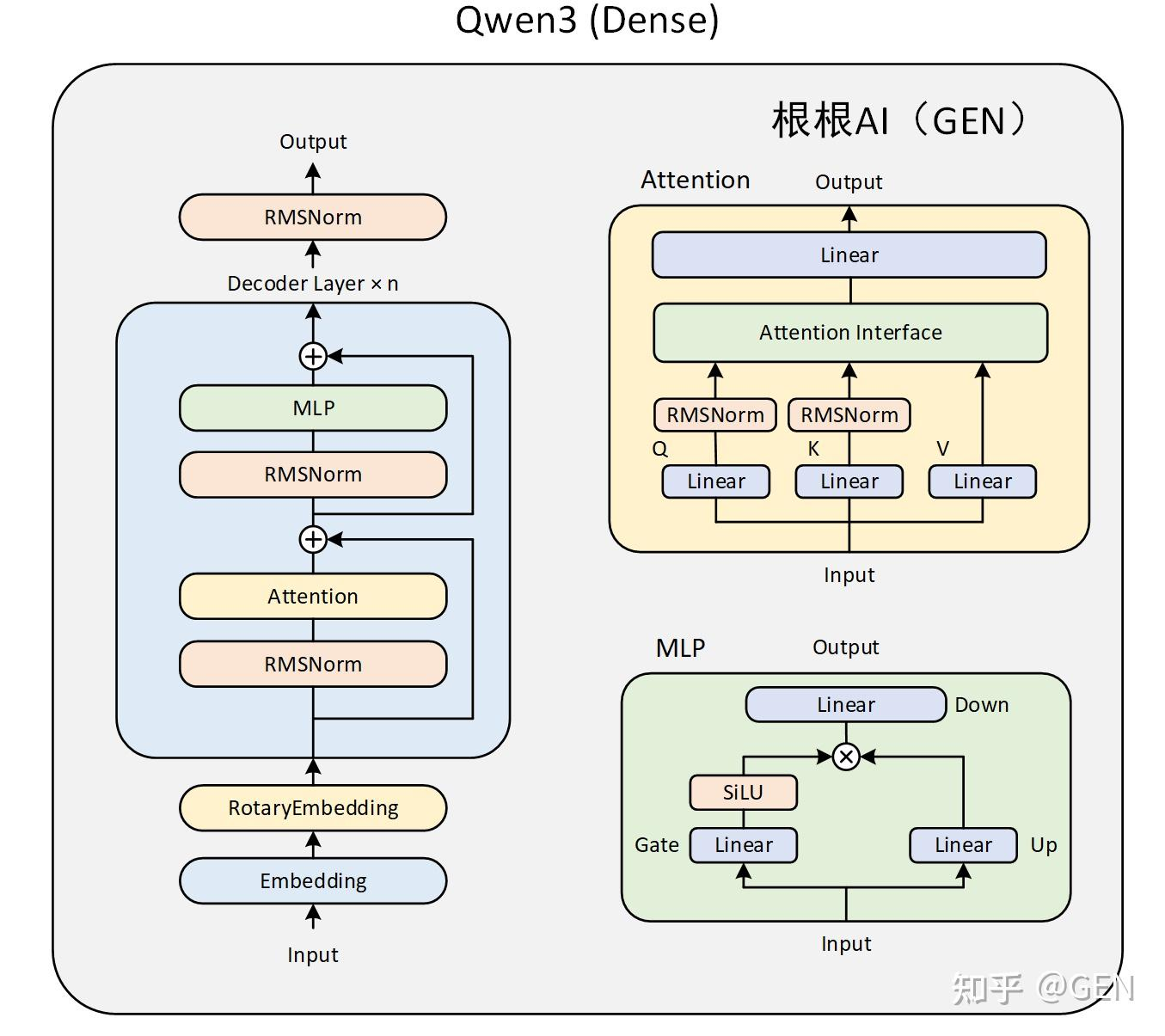
Qwen3主要由四个部分组成:
embed_tokens:嵌入层。这是模型处理输入的第一步。它的核心功能是将输入的离散文本符号(通常是经过 Tokenizer 处理后的 Token ID)转换为连续的、稠密的向量表示(称为嵌入向量或 Embeddings)。
Decoder layers:多个堆叠的解码器。这是模型的核心计算引擎,负责理解输入序列的上下文、提取特征并进行深度信息处理。模型的能力(如理解、推理、生成)主要源于这些层。
norm:归一化层。处理完毕后,对最终的隐藏状态 (Hidden States) 进行最后一次归一化。
rotary_emb:旋转位置编码。为模型提供关于序列中 Token 位置的信息。标准 Transformer 的自注意力机制本身是排列不变的(即打乱输入顺序可能得到相同结果),因此需要显式地注入位置信息。
Qwen3MoeDecoderLayer解析
Qwen3MoeDecoderLayer的结构图如下所示:
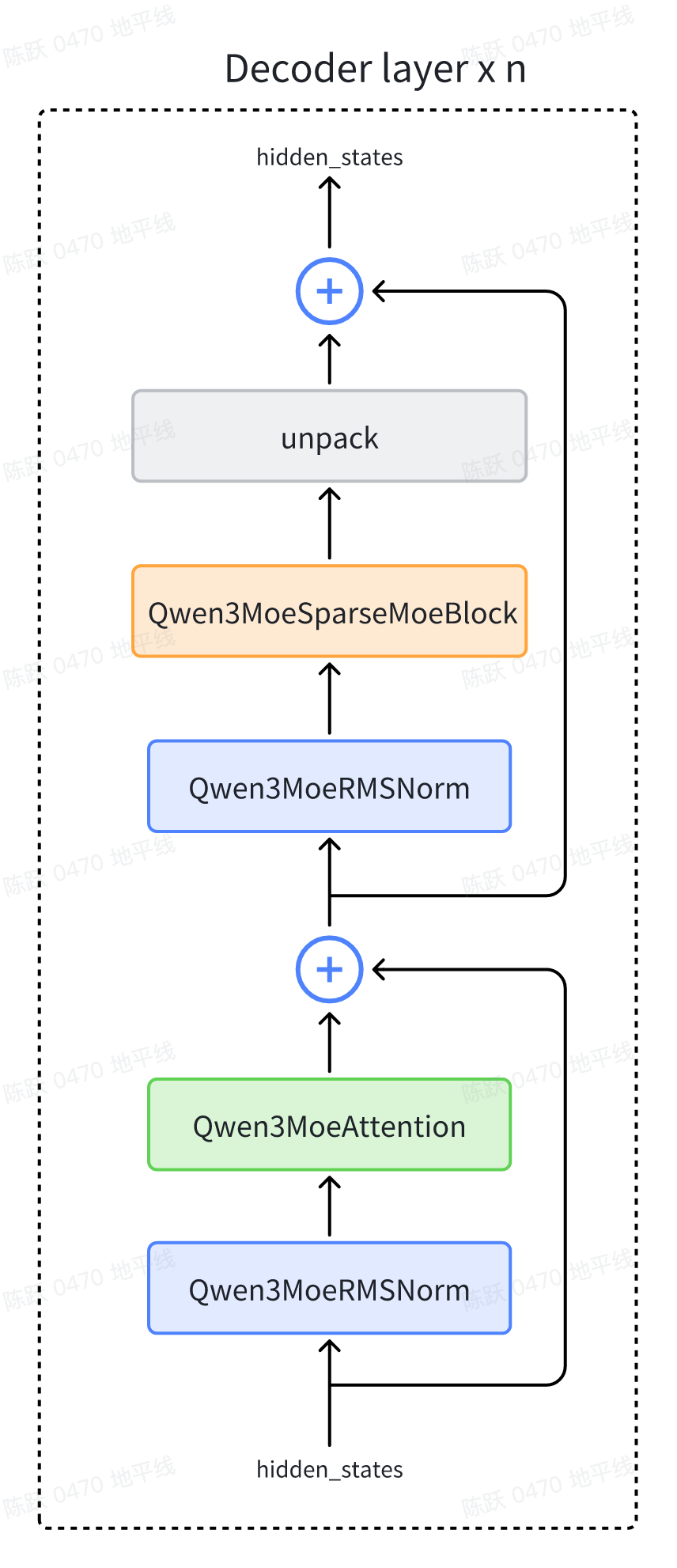
下面逐个对上图中的block进行解释。
Qwen3MoeRMSNorm
功能:实现 RMS 归一化,通过对输入特征的均方根进行缩放,稳定数值分布,类似 LayerNorm 但计算更轻量(不含均值中心化)。
- 初始化:定义可学习的缩放权重weight(维度与hidden_size一致)和数值稳定参数eps(避免除零)。
前向传播:

- 装饰器:@use_kernel_forward_from_hub("RMSNorm")表示从 hub 加载优化的 RMSNorm 内核实现(可能是高效的 C++/CUDA 算子),提升计算速度。
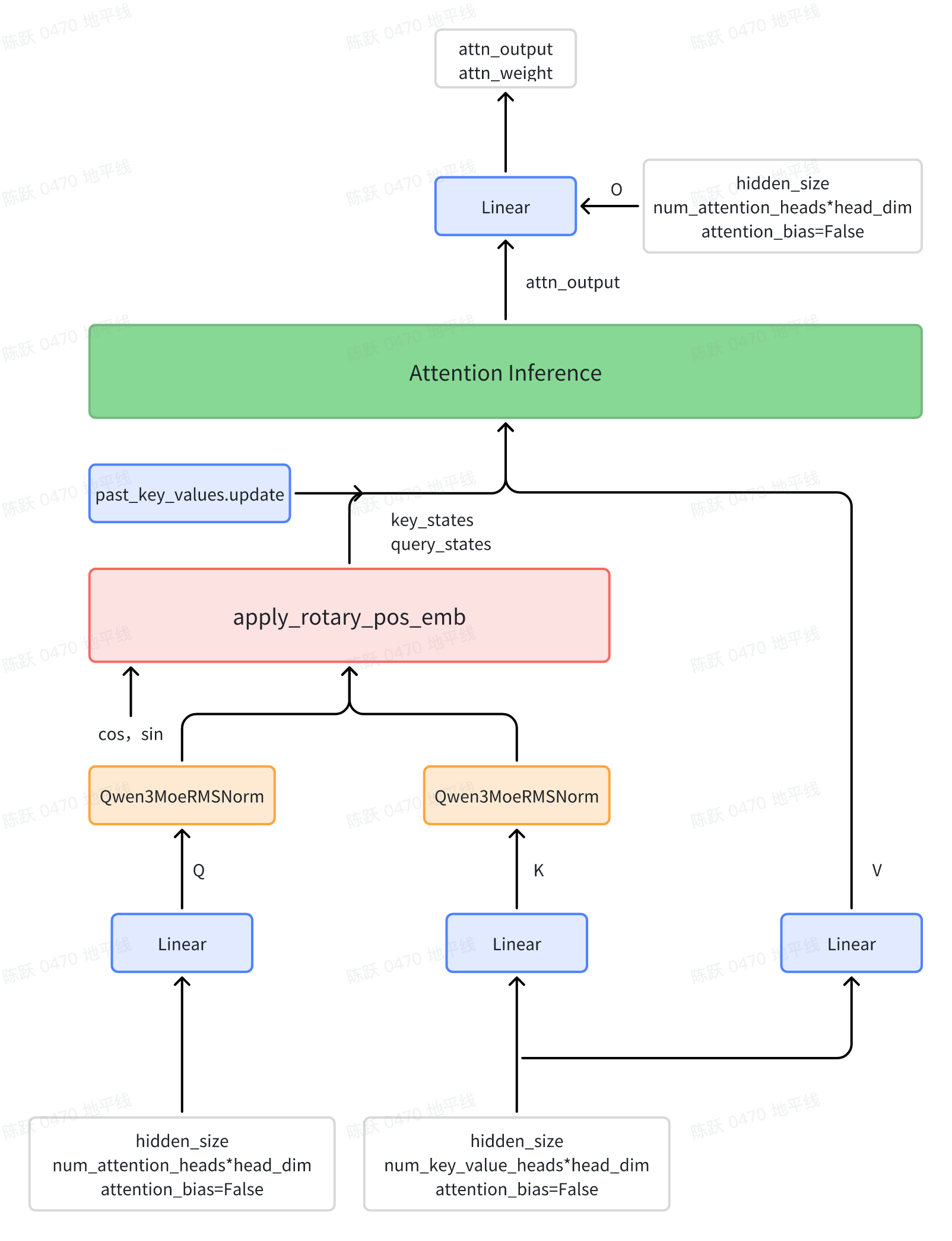
Qwen3MoeAttention
Qwen3的注意力机制在Qwen2的基础上进行了微调,在Q、K的线性投影后面分别加入了一个归一化层,有助于提高稳定性。
Qwen3MoeSparseMoeBlock
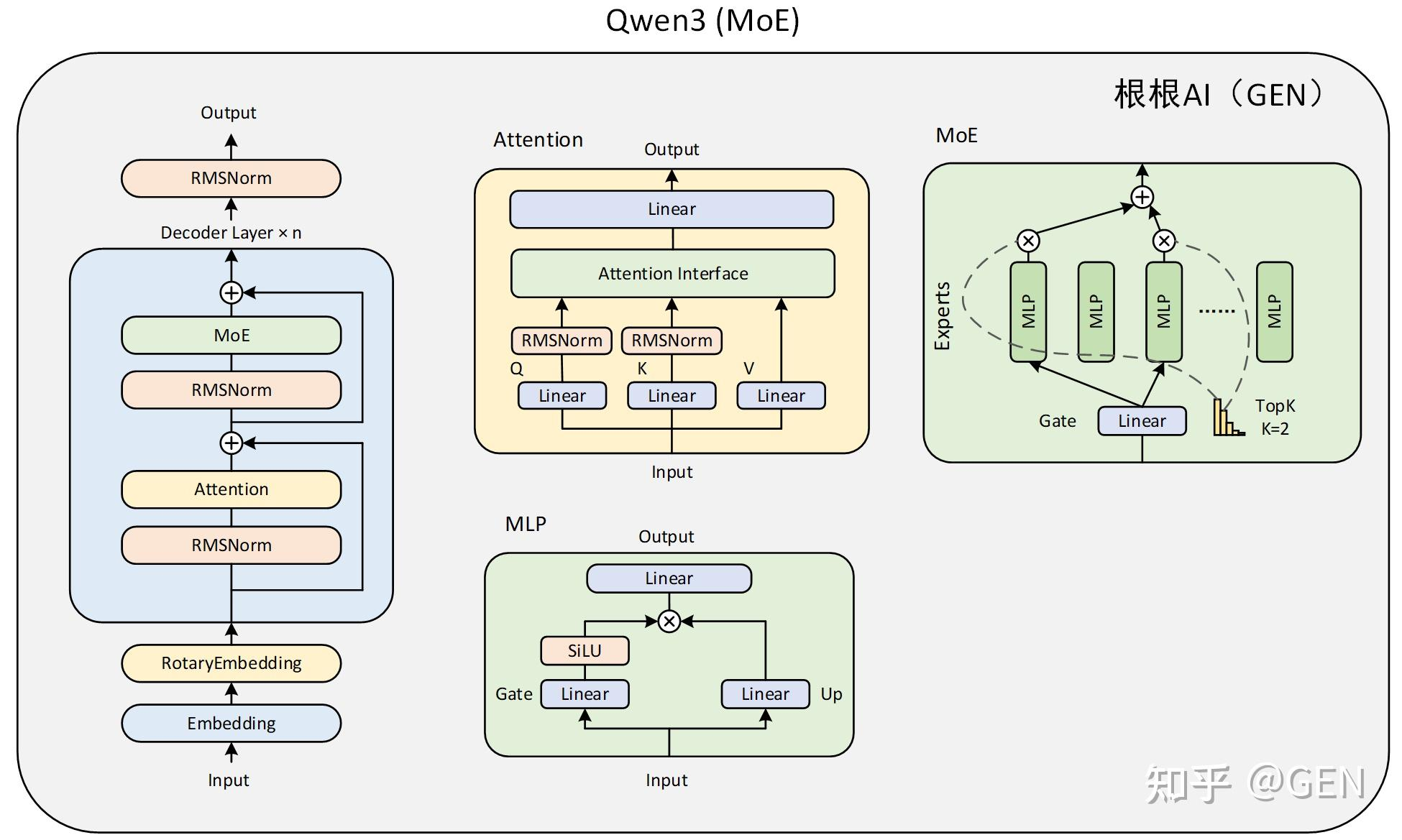
将传统Transformer模型中的全连接MLP层替换为新型的稀疏专家模块(Qwen3MoeSparseMoeBlock)。该模块由以下两个关键组件构成:
包含num_experts个轻量级专家网络(Qwen3MoeMLP)的并行计算单元;
- 基于注意力机制的路由网络(gate)。在计算过程中,路由网络通过动态决策机制为每个输入Token生成路由决策,筛选出匹配度最高的top_k个专家节点。随后,系统将根据路由权重对选定专家的计算结果进行加权融合,最终生成该隐层的表征输出。
https://zhuanlan.zhihu.com/p/1902461213255925825
代码解析:
QWen3部署实战
huggingface中下载的文件:
文件说明
config.json
模型的结构配置文件,比如隐藏层维度、层数、注意力头数、激活函数等。
- AutoModelForCausalLM.from_pretrained() 会先读取它,决定用哪种架构初始化模型。
generation_config.json
- 文本生成时的默认参数,例如 max_new_tokens, temperature, top_p, do_sample 等。
- 如果你用 model.generate(),没手动传参数,就会用这里的默认值。
merges.txt
BPE (Byte Pair Encoding) 分词的合并规则文件。
- 跟 vocab.json 一起定义了 tokenizer 的词表。
vocab.json
tokenizer 的词表文件,存储了 token 到 ID 的映射。
- 例如 "hello" -> 1234。
tokenizer.json
Hugging Face 的标准 tokenizer 文件,包含 vocab 和 merges 的完整定义。
- 用 AutoTokenizer.from_pretrained() 会加载它。
tokenizer_config.json
Tokenizer 的额外参数,比如是否大小写敏感、padding/truncation 策略等。
- model-00001-of-00003.safetensors, model-00002-of-00003.safetensors, model-00003-of-00003.safetensors
模型的权重文件,分成了多个分片,每个几 GB。
- safetensors 是一种比 pytorch_model.bin 更安全和高效的格式。
model.safetensors.index.json
权重索引文件,指明每个参数在分片文件中的位置。
加载模型时,transformers 会先读这个文件,再去对应分片里加载。
将huggingface中的文件全部下载到 "./Qwen/Qwen3-4B-Thinking-2507"文件夹
在docker环境中安装(torch 2.3.0):
部署代码:
参考链接
https://github.com/QwenLM/Qwen3
https://zhuanlan.zhihu.com/p/1901014191235633835
https://zhuanlan.zhihu.com/p/1902019286836449827
https://qwen.readthedocs.io/zh-cn/latest/
https://github.com/huggingface/transformers

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)