前言
当前端到端智能驾驶技术发展迅速,SparseDrive 作为代表性模型受行业关注。工程化落地时,其模型导出与性能评测环节存在普遍技术挑战,涉及架构与环境兼容性、算子适配等多维度。为推动端到端智驾技术社区化发展,本文梳理 SparseDrive 从 ONNX 导出到硬件部署的技术链路,剖析算子替换、编译报错修复、量化策略优化等案例,构建含环境配置、数据集处理、权重管理、配置工程化的全流程技术指南,为社区提供可复用的端到端模型工程化方案,加速智驾模型从研究到车规级部署转化。
代码库:https://github.com/swc-17/SparseDrive
环境部署
解压公版代码包,然后创建python虚拟环境:
直接pip3 install -r requirement.txt会报错,这里打算逐个安装whl包。
升级gcc(for 安装mmcv-full)
步骤 1:安装新版 GCC/G++
使用 conda 安装,不会破坏系统自带的 GCC 4.8.5:
安装完成后,你会在 Conda 环境里有新 GCC,例如:
/home/users/yue01.chen/anaconda3/envs/sparsedrive/bin/x86_64-conda-linux-gnu-gcc
步骤 2:指定编译器环境变量
为了确保 pip 编译 mmcv-full 时使用 Conda 的新版 GCC,而不是系统 4.8.5,需要设置环境变量:
可以把这两行添加到 .bashrc 或 .zshrc 中,保证每次激活环境自动生效。
步骤 3:卸载旧的 mmcv/mmcv-full
pip uninstall mmcv mmcv-full -y
步骤 4:从源码编译 mmcv-full
pip install mmcv-full==1.7.1 --force-reinstall --no-cache-dir --no-binary mmcv-full
说明:
步骤 5:验证安装
Python 中验证 mmcv-full GPU 扩展是否可用:
- 如果报错 ModuleNotFoundError: No module named 'mmcv._ext',说明编译仍有问题,需要检查:
GCC 版本 ≥ 7
- CUDA 环境变量 CUDA_HOME 是否指向 /home/users/yue01.chen/cuda-11.8
- nvcc 可用 (nvcc --version)
后续在运行中缺乏什么库就直接pip3 install即可。
创建数据集与权重下载
生成pkl
从官网下载nuscenes数据集,解压后把expansion文件夹放到maps下,
然后运行:
代码运行完成会在data/info目录下生成:
报错的时候把这个注释了:
报错的时候把这个注释了:
生成kmeans.py
权重下载
https://download.pytorch.org/models/resnet50-19c8e357.pth
下载完成后放在ckpt文件夹。
config文件修改
导出脚本和适配修改
导出思路:为了不大幅侵入源码,在导出脚本里重写了forward,并增加环境变量进行控制
去除后处理
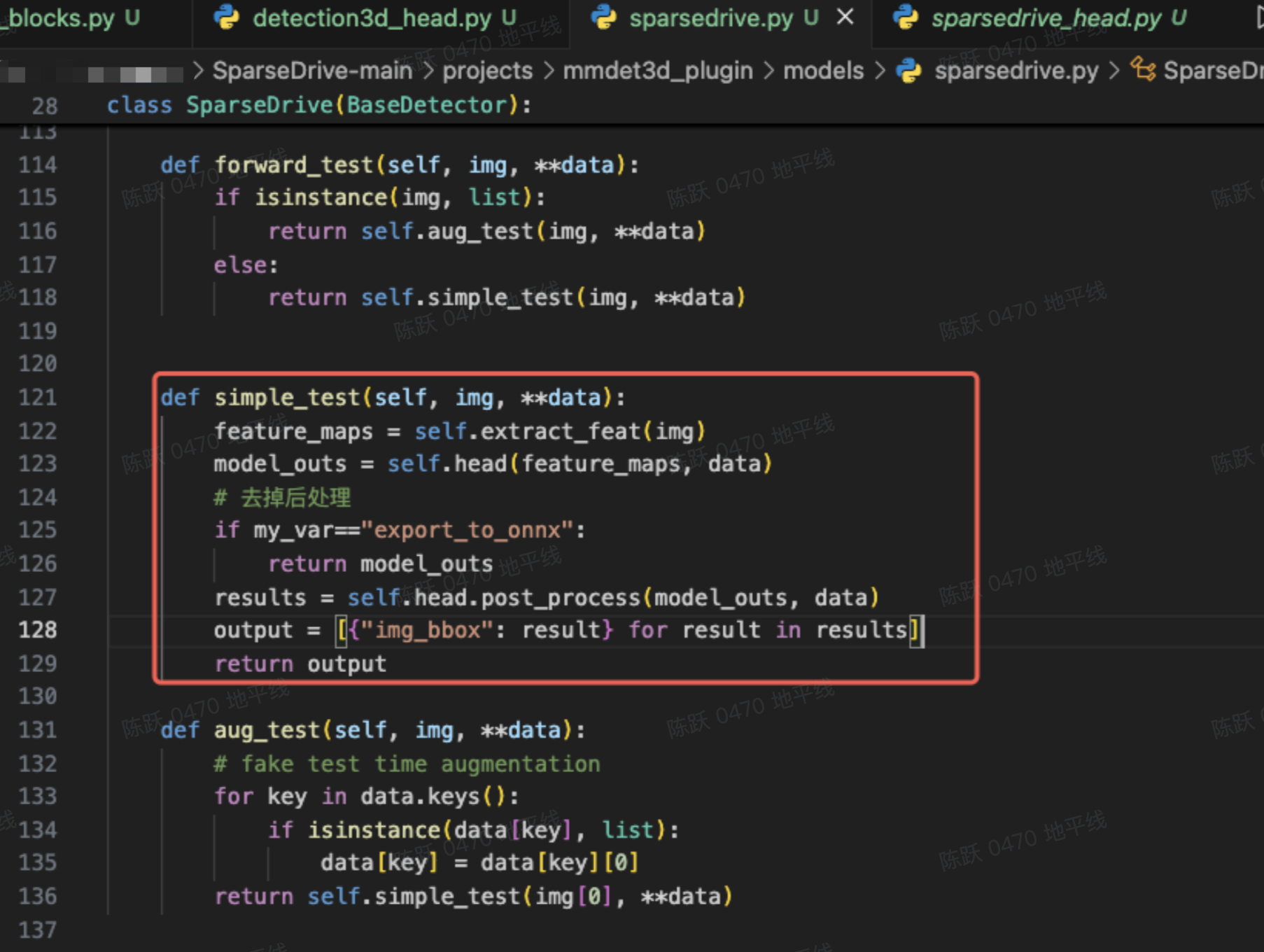
重写forward
在tools文件夹下构建forward_export.py,重写sparsedrive、det_head和map_head的orward函数,如下所示:
self.instance_bank.get_for_export_det_onnx()函数
路径:SR/12yuanrong/SparseDrive-main/projects/mmdet3d_plugin/models/instance_bank.py
self.instance_bank.get_for_export_map_onnx()函数
路径:SparseDrive-main/projects/mmdet3d_plugin/models/instance_bank.py
修改导出会报错的代码
报错1
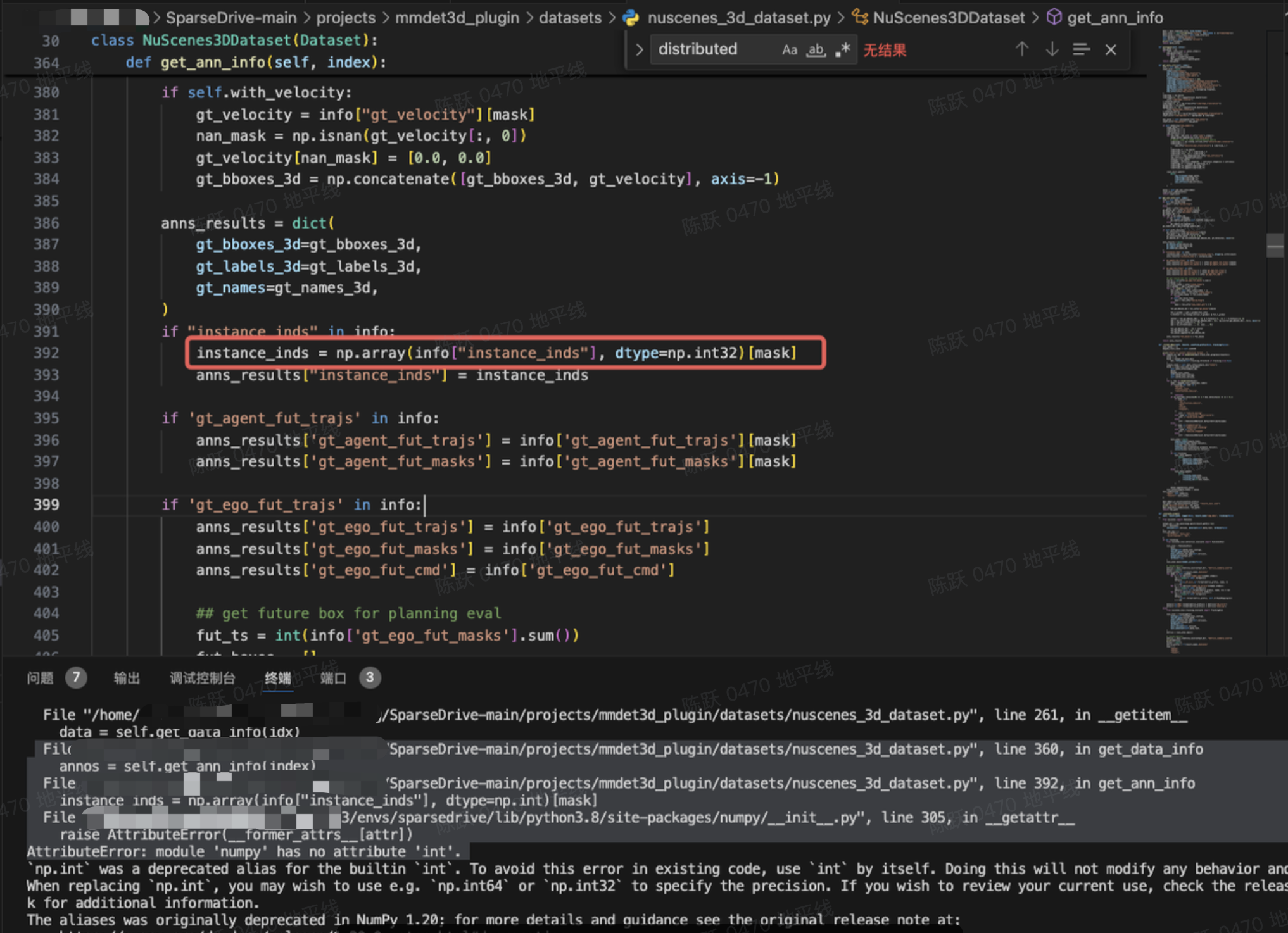
将instance_inds修改为np.int32类型。
报错2
报错:
报错原因:
解决办法
解决办法:
把self.instance_bank.get_for_export_det_onnx()和self.instance_bank.get_for_export_map_onnx()函数中的
修改成repeat实现,如下:
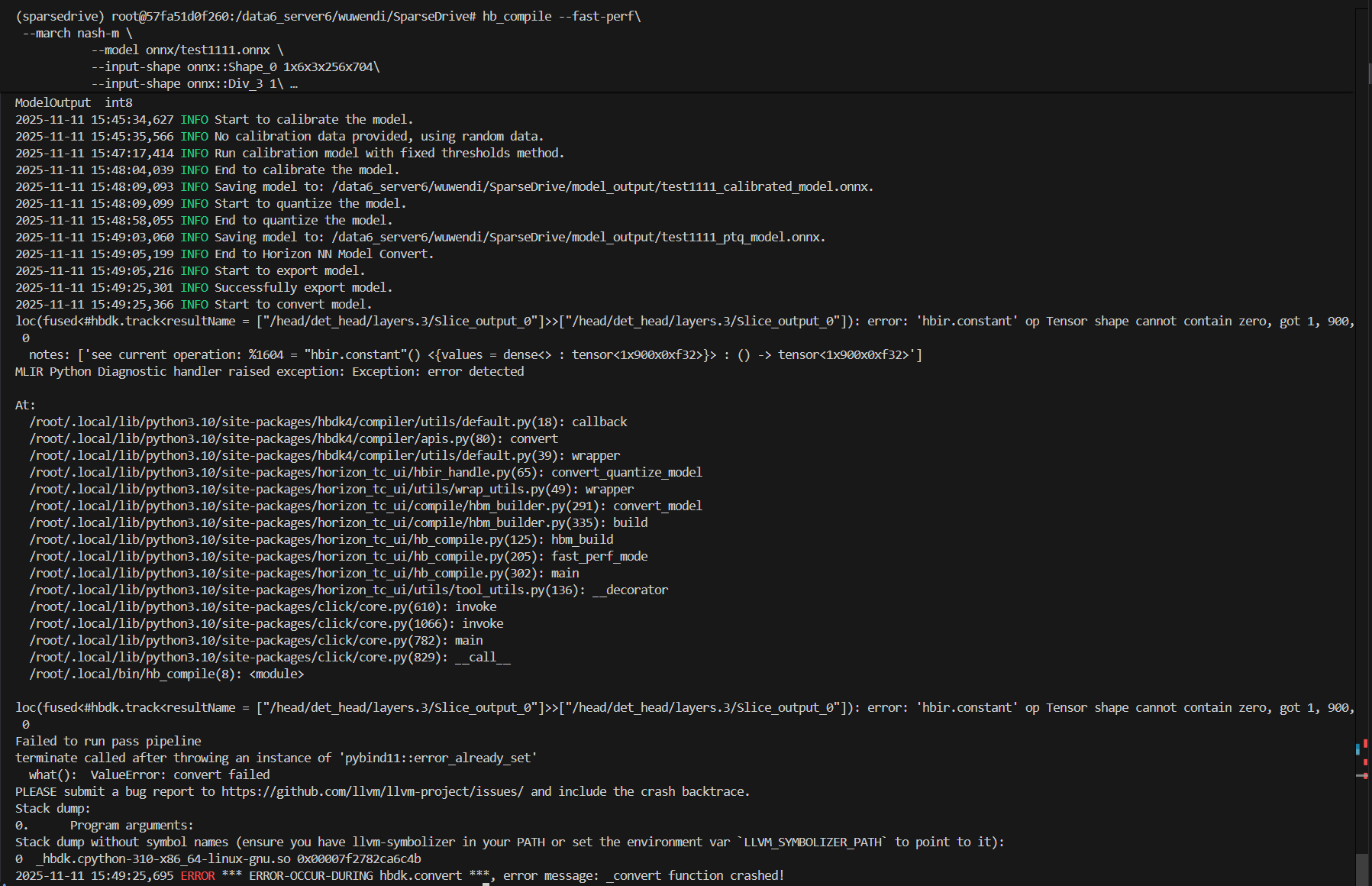
报错3(重要)
报错截图:
报错原因:
优先级修复建议(按顺序尝试)
- 定位问题代码:查找模型中类似 x[:, idx] = y、x[index] = y、index_put、masked_scatter、masked_fill 的用法。也可在 torch.onnx.export(..., verbose=True) 打印的导出图里查找 aten::index_put、index_put、prim::ListConstruct 等节点位置。
- 把原地/索引赋值改写为 ONNX 友好的算子:常用替代方法:
- 用 scatter:
- x = x.clone()
x = x.scatter(dim, indices.unsqueeze(-1).expand(...), y) - 用布尔 mask + torch.where:
- mask = torch.zeros_like(x, dtype=torch.bool)
mask[:, indices] = True
x = torch.where(mask, y_broadcasted, x)
这两种通常能被 ONNX 导出器更好地支持。
- 确保传入 torch.onnx.export 的示例输入都有明确 dtype(不要传 None 或 Python 原始标量),例如 tensor.float().cuda()、indices.long().cuda()。
- 尝试不同的 opset 或更新 PyTorch:有些导出器 bug 在较新 opset 或 PyTorch 版本里被修复。可试 opset_version=12、14 等;若可行,升级 PyTorch 往往能解决这类问题。
- 临时回退方案:如果短时间无法改模型,可使用 ATen fallback(operator_export_type=OperatorExportTypes.ONNX_ATEN_FALLBACK)导出,得到包含 ATen 节点的 ONNX(不适合生产但便于调试)。
- 不要修改 site-packages(除非非常了解风险):虽然可以在 _type_utils.from_name 做防守性修改防止报错,但这不是长期或推荐的做法。
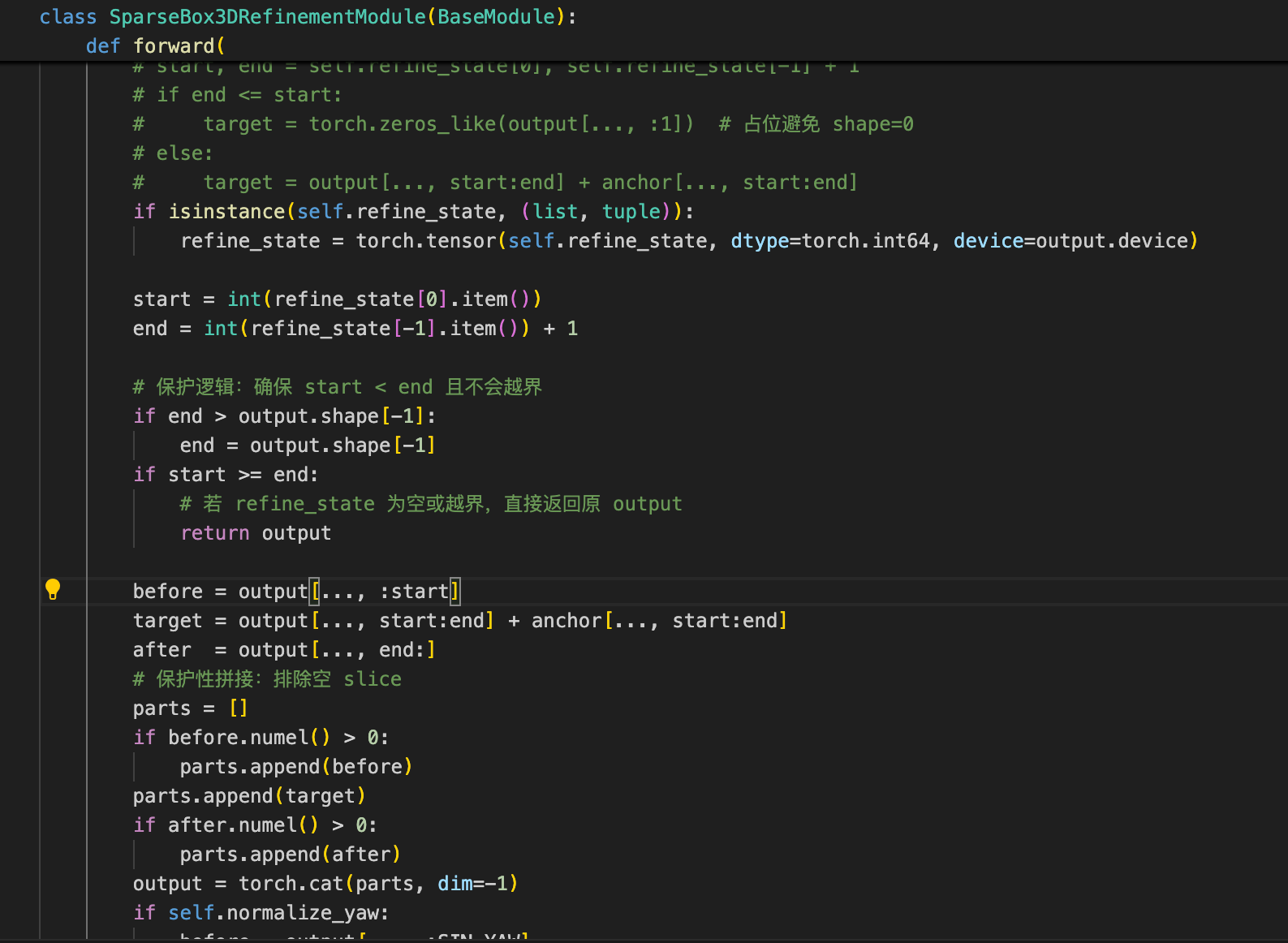
通过二分法定位到是refine模块的报错(即在refine模块前return导出onnx不报错,经过refine层以后return 会报错),然后逐渐定位到其中的这个部分触发了上述1中的错误,如下:
修改后的代码:
scatternd消除
由于J6工具链目前只支持CPU实现的scatternd,所以在导出onnx的时候把这部分替换成slice+concat的实现。
导出代码
另外,需要对tools/dist_test.sh进行修改如下;
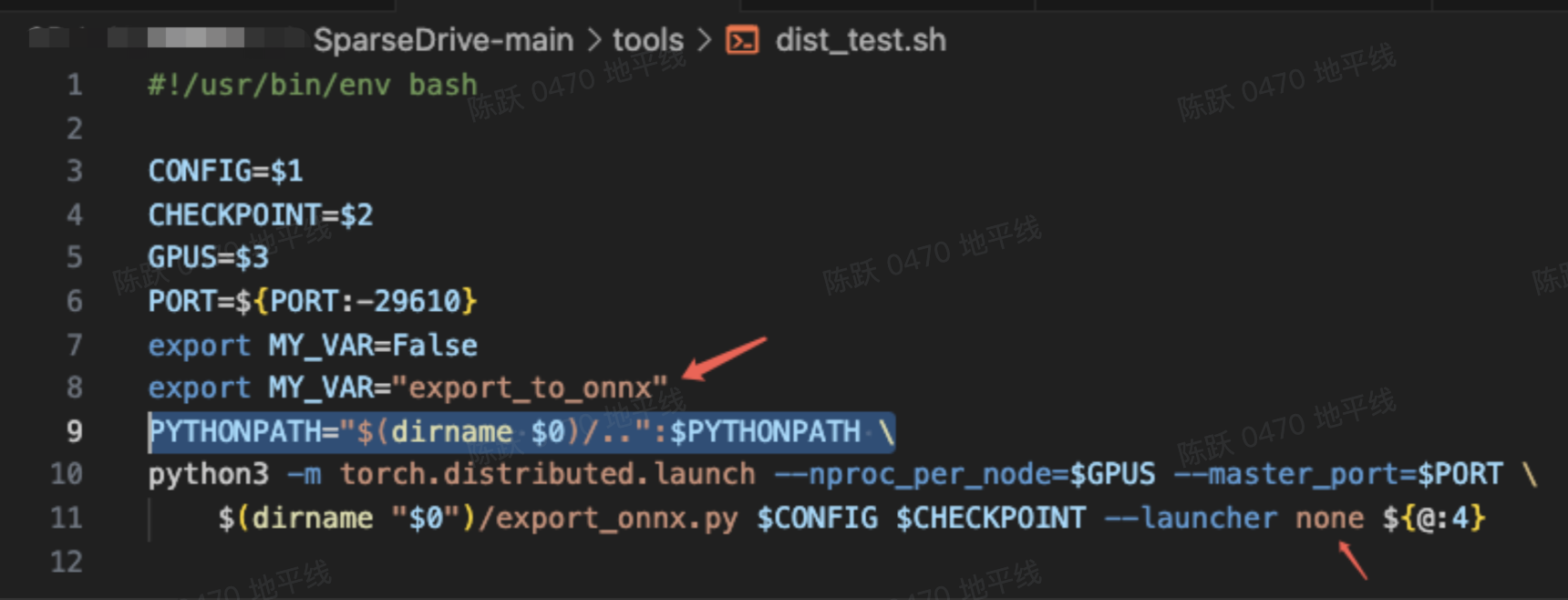
导出脚本运行:
cache过程的scatternd和 Cast算子消除(如果模型中存在cache过程的话)
如果想要在模型中增加输出cache的功能,即在forward_export.py的函数中增加以下代码:
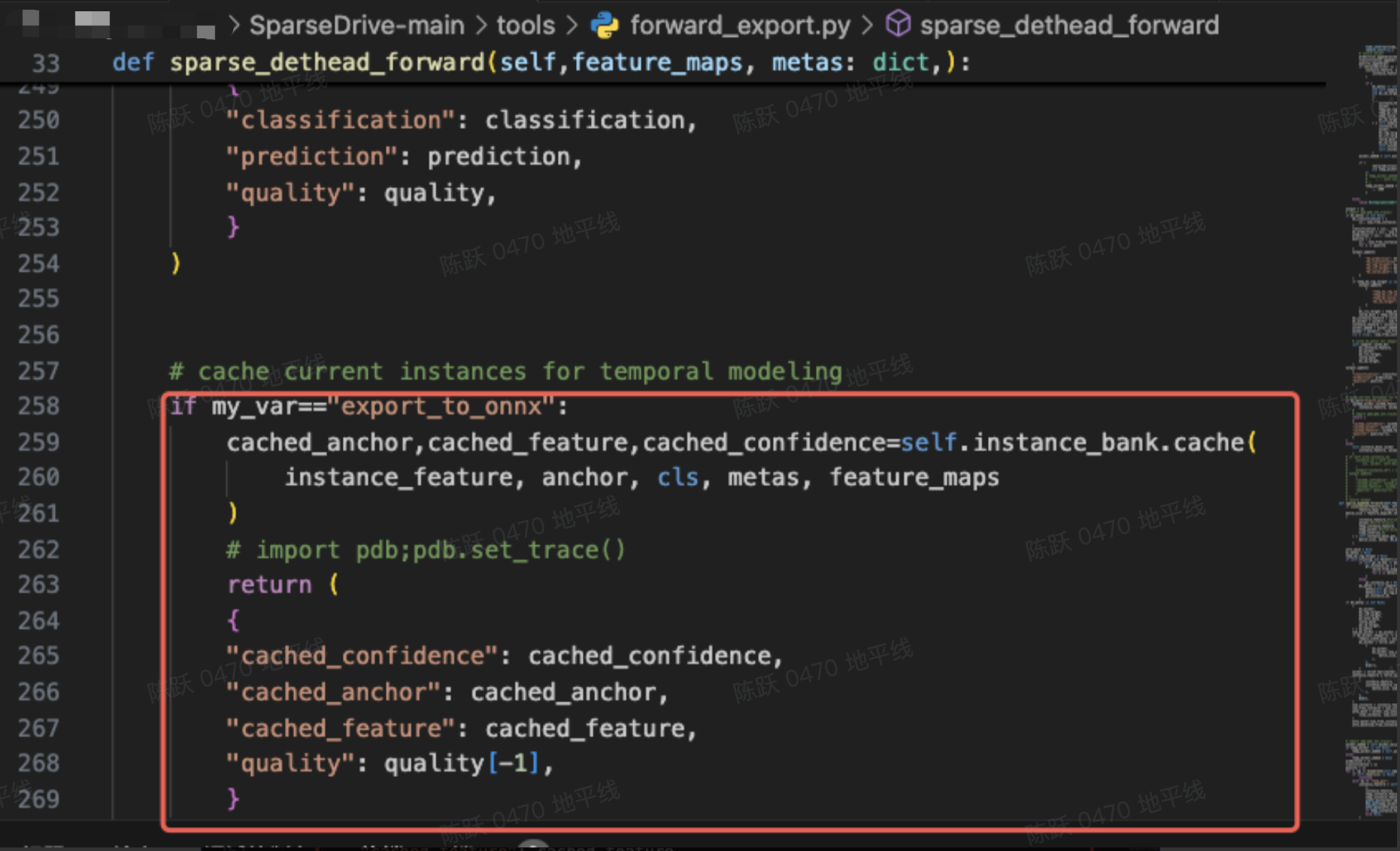
但是公版的self.instance_bank.cache()函数的写法会引入工具链只能在CPU上支持的ScatterND算子和Cast算子,所以这里需要对代码做两处适配。
消除scatternd算子:
路径:SparseDrive-main/projects/mmdet3d_plugin/models/instance_bank.py中的cache函数:
消除cast算子:
路径:SparseDrive-main/projects/mmdet3d_plugin/models/instance_bank.py中的topk函数:
性能评测
算子支持情况
nash-p下可以编译成功
修改模型后,所有算子支持BPU实现
静态per性能分析
确定性能瓶颈
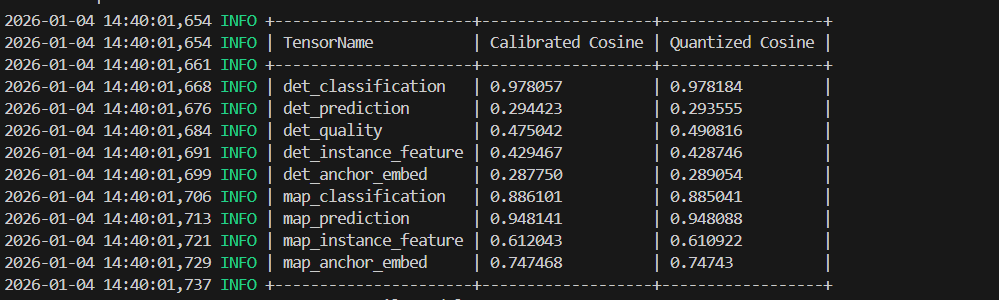
获取到perf.html和perf.json后,使用【新版perf文件解读与性能分析】附录中的脚本对性能进行分析,输入为perf.json,输出如下所示:
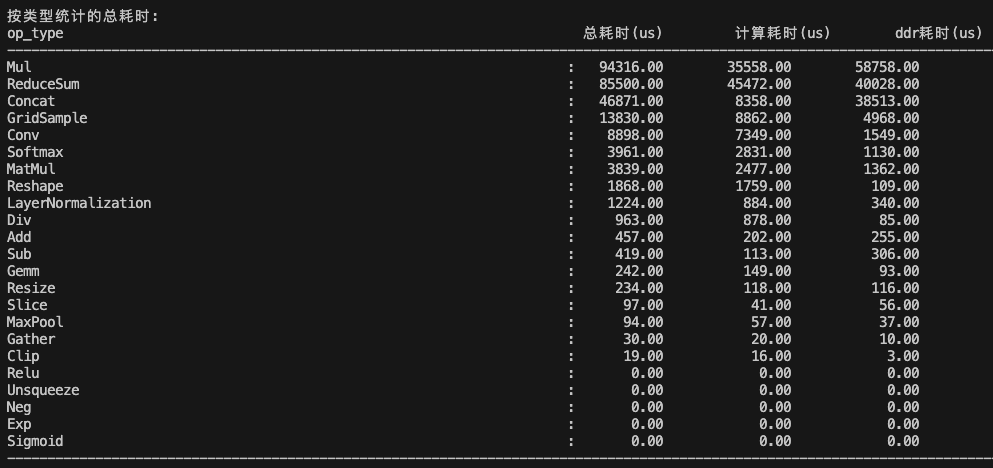
按照算子类型统计的耗时:
耗时排名TOP20的算子:
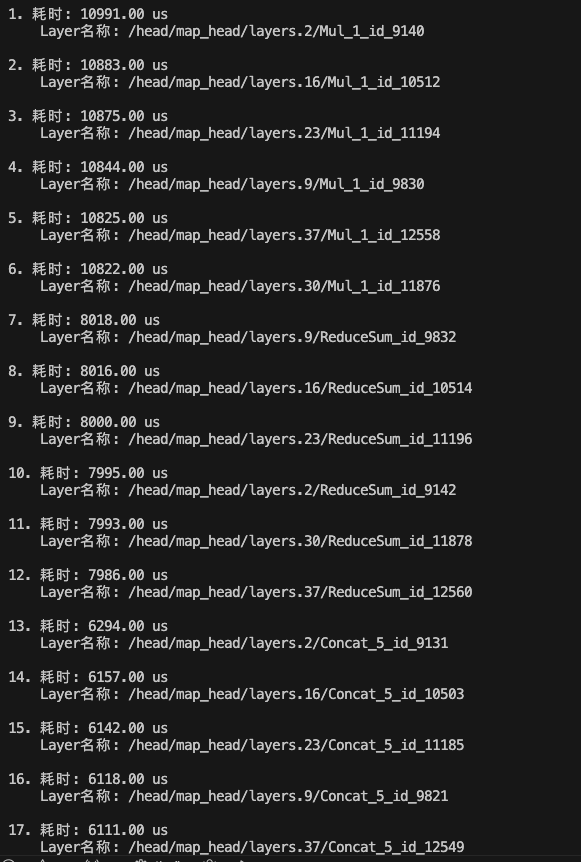
根据以上信息,可以得出优化目标:
Mul和ReduceSum算子的耗时最久,而且mul算子ddr耗时超过计算耗时的65%,引发了带宽问题;
ToP12耗时的算子就是Mul和ReduceSum,所以重点是优化Mul和ReduceSum算子。
性能优化策略
查看模型结构发现,模型中耗时的Mul和ReduceSum都处于这样的子结构中,所以我们主要是对这个结构进行性能优化。
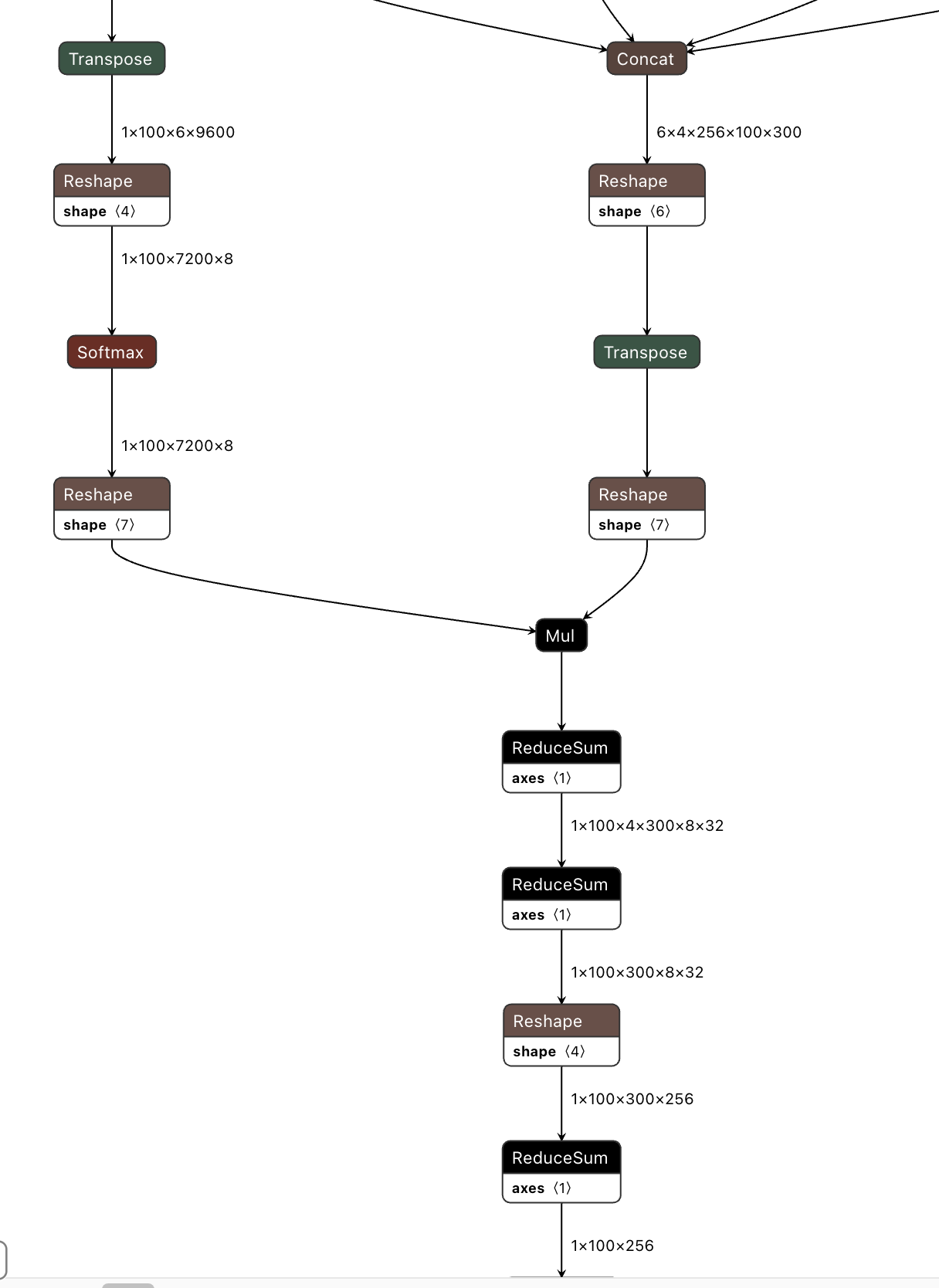
此结构主要由Mul、ReduceSum和数据搬运算子组成,一方面MulReduceSum是运行在专门做向量计算的VAE,加速效果不如张量,另一方面输入的shape非常大,也就解释了为何会引发带宽问题。、
所以这里考虑将Mul+ReduceSum计算替换为等价的Mamtmul,从而使得这部分计算在VAE上加速。
性能优化效果验证
这里主要有以下步骤:
- 替换为Matmul计算:根据上述子图结构将其替换为Matmul计算,并导出optimized.onnx;
- 替换等价性验证:在原始onnx中提取上述子图,和optimized.onnx进行输出一致性验证;
- 性能评测:同时对原始onnx子图和optimized.onnx进行fast-perf,验证性能收益。
上述步骤可以参考:https://developer.horizon.auto/blog/13065

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)