
在将算法模型部署至J6芯片平台的实际应用中,由于算法设计与硬件架构特性存在差异,可能会出现部分算子适配度有待提升、运行效率有待优化以及量化精度可进一步优化等情况。解决好这些问题有助于模型更快更好的运行,充分发挥硬件性能。
本文聚焦于算法模型在J6芯片上部署时的算子支持问题,包括算子不支持、算子运行效率低、算子量化精度差问题的解决和优化建议。重点阐述解决上述问题的优化思路给出优化案例,使模型在J6芯片平台实现更快速、更稳定的运行,为算法高效落地提供实用的技术路径。
1. 算子替换
算子替换主要解决模型中存在BPU不支持的算子问题。当遇到无法支持的算子时,为提升执行性能需要使用BPU支持的算子对不支持的算子做替换,使尽可能多的运行在BPU中。
1.1 Scatternd的产生和消除
ScatterND算子由op 做了 slice操作 之后 又进行inplace产生,因此会引入CPU算子。若导出的onnx中均存在大量 ScatterND,希望从算法侧进行移除, 等价替换相关操作即可。以下给出几种使用场景:
场景1:
将模型导出后会发现存在scatternd算子:
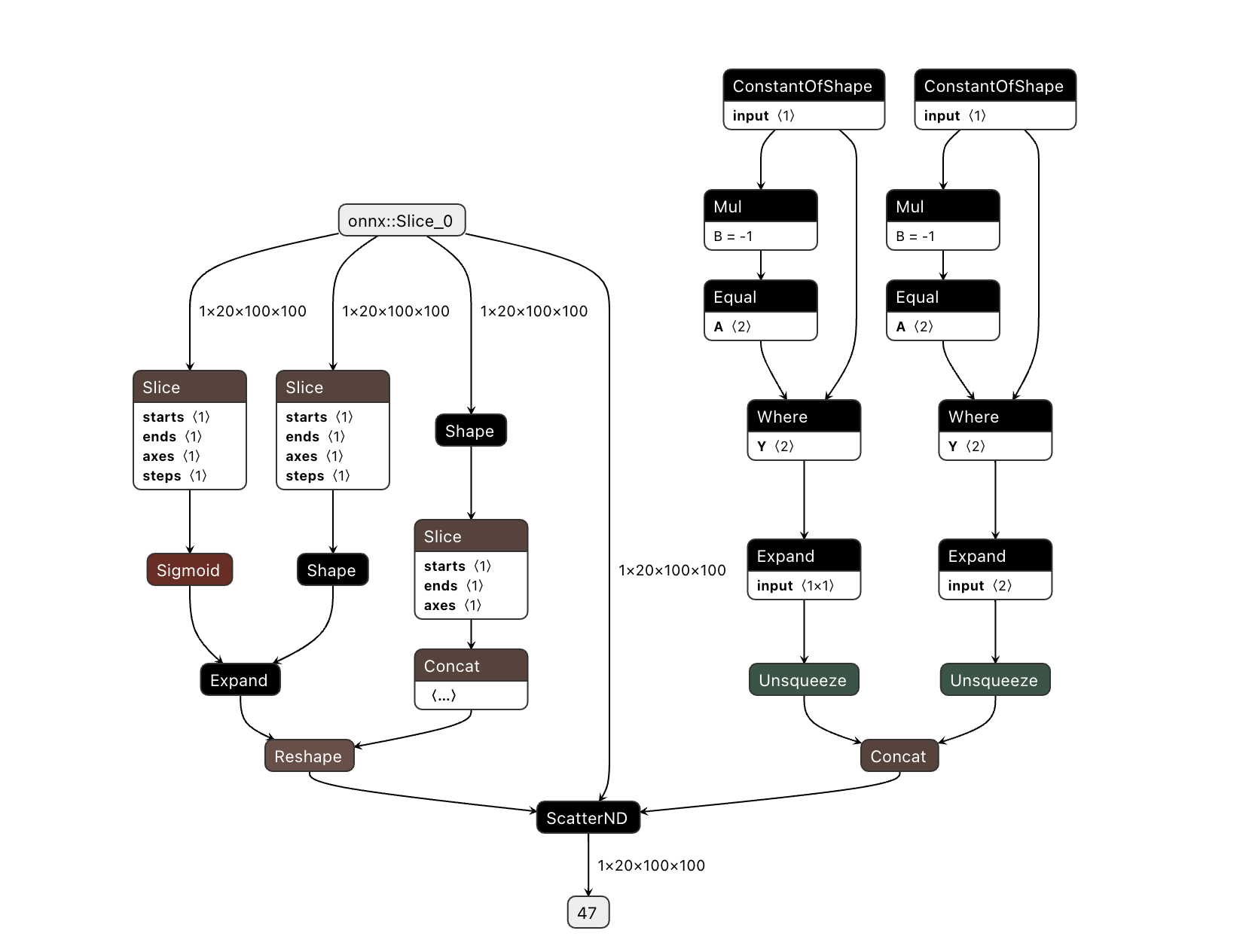
修改后不带ScatterND的代码与模型结构
查看onnx,scatternd算子不存在,已被替换。
场景2:
修改前onnx中带有ScatterND算子的代码示例
修改后onnx中不带ScatterND算子的代码示例
场景3:
如下代码会引入scatterND
修改与验证代码如下:
方案1与方案2思想一样
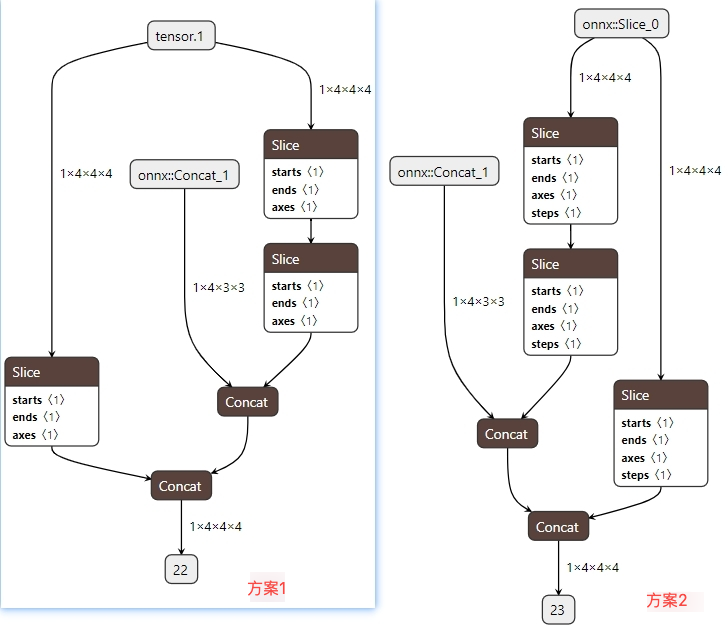
场景4:
原包含scatternd算子的代码:
修改之后:
场景5:
Swin Transformer中为滑动注意力窗口计算对应的掩码值,不同区域做标识符区分
原代码为:
修改之后:
主要思路,把对原tensor划区域的赋值方式修改为划区域的拼接,先对w维度进行拼接,再对h维度拼接
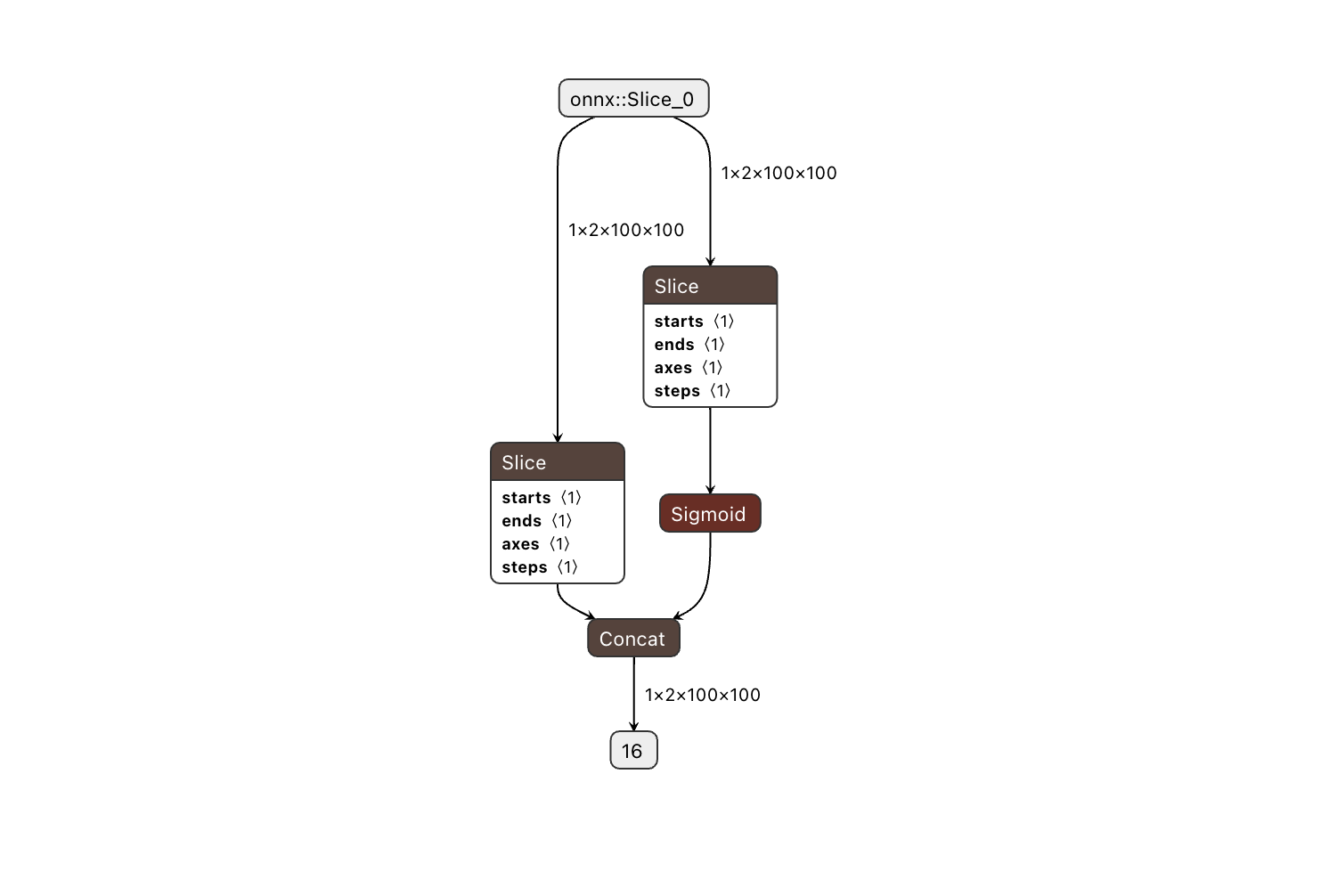
1.2 Bool赋值和Mask替换
对于PNC以及静态目标检测模型,模型中较多逻辑判断涉及到bool数据类型的赋值和mask操作,这一类操作可以考虑替换为torch.where算子,可以消除潜在的cpu算子并提升模型性能,例如
该操作在E/M会引入cast和equal算子cpu,如下
可以修改为:
1.3 Mod和Rem 替换
对于模型中常见的取余操作以及编译器的支持情况,整理如下:
torch.fmod:余数符号和被除数一致,后端为Mod算子,在9/30 版本中可以VPU直接支持,类型为int16/int32。
对于除数和被除数均为正数的场景,可以用torch.fmod直接替换%或者torch.remainder,否则需要考虑余数符号来看是否可以做替换。
1.4 Nonzero等效替换
目前J6芯片不支持BPU Nonezero算子,需要对其做替换使算子跑在BPU中:
1.5 Enisum等效替换
目前J6芯片不支持torch.einsum算子,可以使用以下两种方式替换:
2. 算子优化
算子优化分为执行效率的优化和精度的优化。在部署时可能出现算子引入的其他开销,或者算子的执行效率支持的不够好的情况,同时在部署时我们还需要考虑算子的量化精度友好性。本章节将分别针对算子的效率优化和精度优化,给出部署建议和优化方案,帮助模型更快、更好的运行。
2.1 效率优化
2.1.1 Topk算子
J6E/M在工具链OE3.2.0已支持topk算子在SPU上运行(J6B在OE3.5.0版本支持),在convert时配置enable_spu=True后算子将会被指定在SPU上运行。若topk算子后接的gather、index算子出现CPU的cast算子时,建议将OE版本升级到OE-3.5.0(或者将hbdk升级到4.5.5及以上版本)。
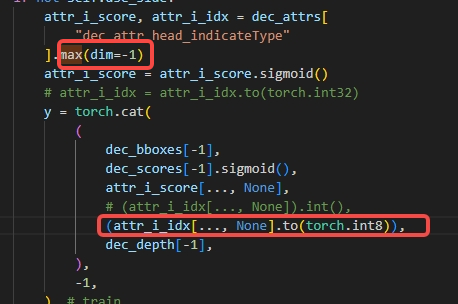
2.1.2 Argmax后cast消除
pytorch的argmax输出的idx为int64类型,若不做改动会导致引入CPU算子,可以将idx 的类型转为int8/int16(视数值范围而定避免溢出)避免引入的开销,参考下图:
2.1.3 多个eltwise操作效率提升
当多个大尺寸的op做add时,若一次性add可能会引入带宽问题。若存在带宽问题,即load&store的时间大于计算时间,建议拆为逐个add相加,
使用示例
以下提供两个常见的对多个eltwise计算的使用示例,方式1为多次相加;方式2为一次相加。
方式1:
方式2:
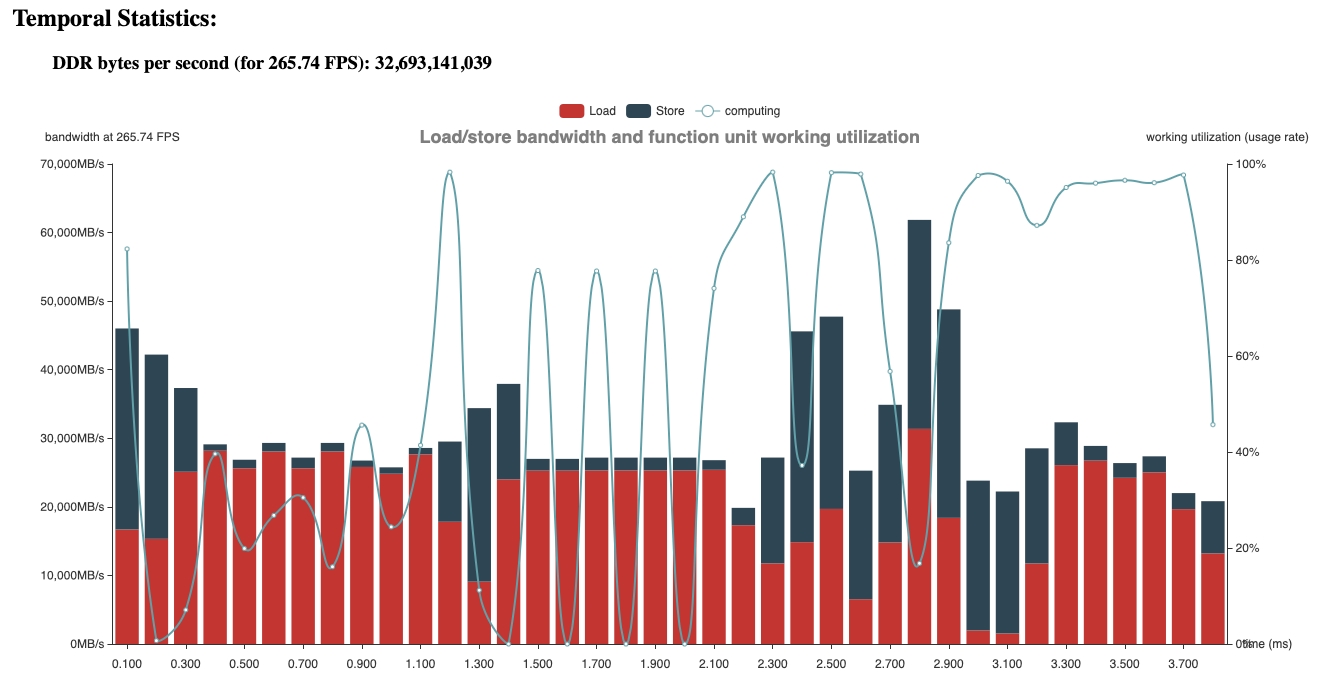
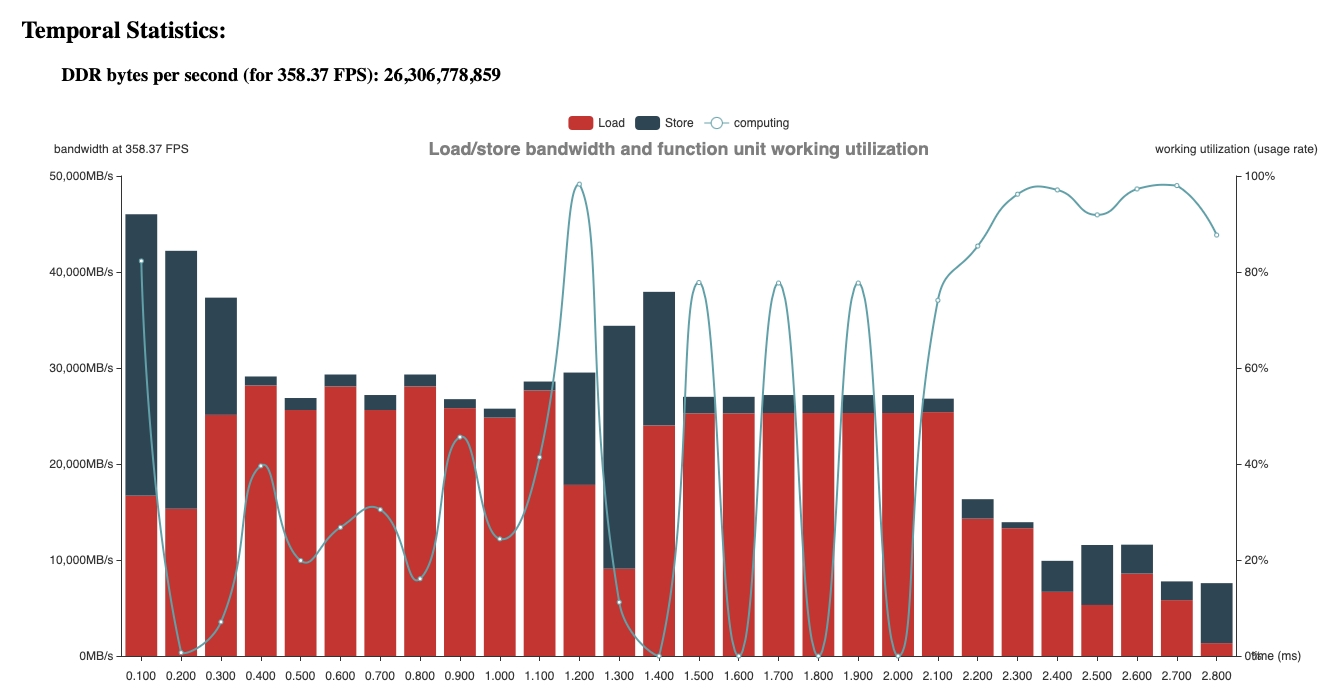
性能表现
以如下输入大小来测试性能差异:
Temporal Statistics:
方式1:latency为3.267 ms
- 方式2: latency为2.321 ms
2.1.4 LayerNorm 优化
https://cloud.tencent.com/developer/article/2509912
论文:https://arxiv.org/abs/2503.10622
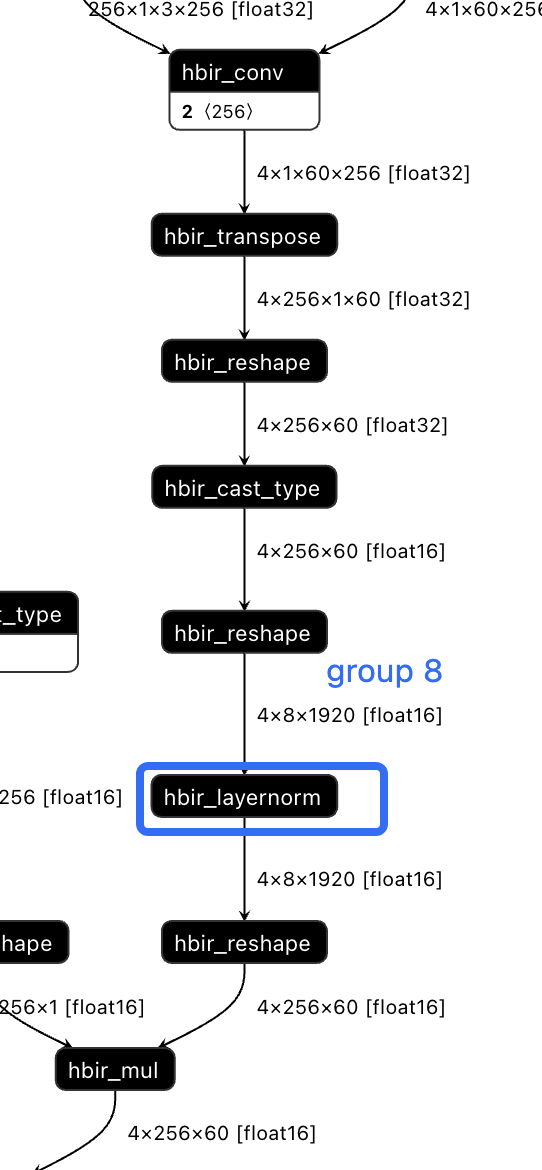
Dynamic Tanh(DyT)是由何恺明、Yarnn LeCun等研究者提出的新结构,用于替代Transformer中的归一化层(如LayerNorm),原理简单,在于归一化层的input-output mapping曲线近似tanh函数,可以直接使用tanh函数来拟合线性归一化层的效果。其设计简单高效,仅需9行代码即可实现,展现出优于或持平传统归一化层的性能,不仅部署性能明显优于ln,训练速度也会有明显提升:
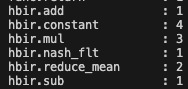
对于transformer模型的J6部署,替换为dyt也是一个很高效的选择,layernorm会被拆分为8个算子,而dyt只有4个算子,且避免了reducemean的计算(相对来说不是那么高效,且量化不友好),部署性能以及量化友好度都有提升。
2.1.5 传统Attention 优化
论文:https://arxiv.org/pdf/2206.08898
SimA针对传统Transformer Self-Attention存在的主要问题,例如长序列任务的计算复杂度高;softmax指数运算导致的梯度爆炸或消失等,完全移除Softmax,采用线性相似度计算降低计算复杂度,同时保持模型近似表达能力,在主流的ViT/NLP模型中取得相当或更好的模型精度同时,有效降低了部署推理的延时,同时减少了训练时间
值得注意的是,实际使用中,在多层attention的encoder结构中,如果使用SimA做替换优化,往往保留最后一层为传统softmax attention做数值修正来保证模型整体精度效果,避免每层线性归一化带来的累计数值误差从而对encoder输出产生影响
2.1.6 Norm优化
从计算效率从高到低排序:batchnorm > dyt > layernorm/instancenorm > groupnorm
但在实际算法场景中例如transformer类的模型,替换batchnorm后浮点精度可能无法训回来,因此layernorm更常用,此外还有groupnorm和instancenorm
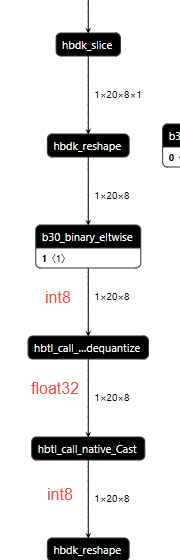
对于group norm而言,groups=1就是layernorm,groups=channels就是instancenorm,所以对于group norm的实现:
plugin导出时通过transpose+reshape将gn转成ln
经实验layernorm比group norm要快(因为可以避免前后reshape),但是用户手动将group norm替换layernorm1d,需要手动在前后加permute(因为ln从最后一维开始norm),替换比较麻烦。使用下面的方式对channel维度做norm,同时避免引入前后的permute:
2.1.7 nn.Embedding优化
例如下面结构,让embedding的一路维持定点类型可优化
对定点数tensor的quant需要给scale=1的fix_scale配置,参考如下
优化后可实现BPU全一段。
2.1.8 where常量广播优化
优化前:
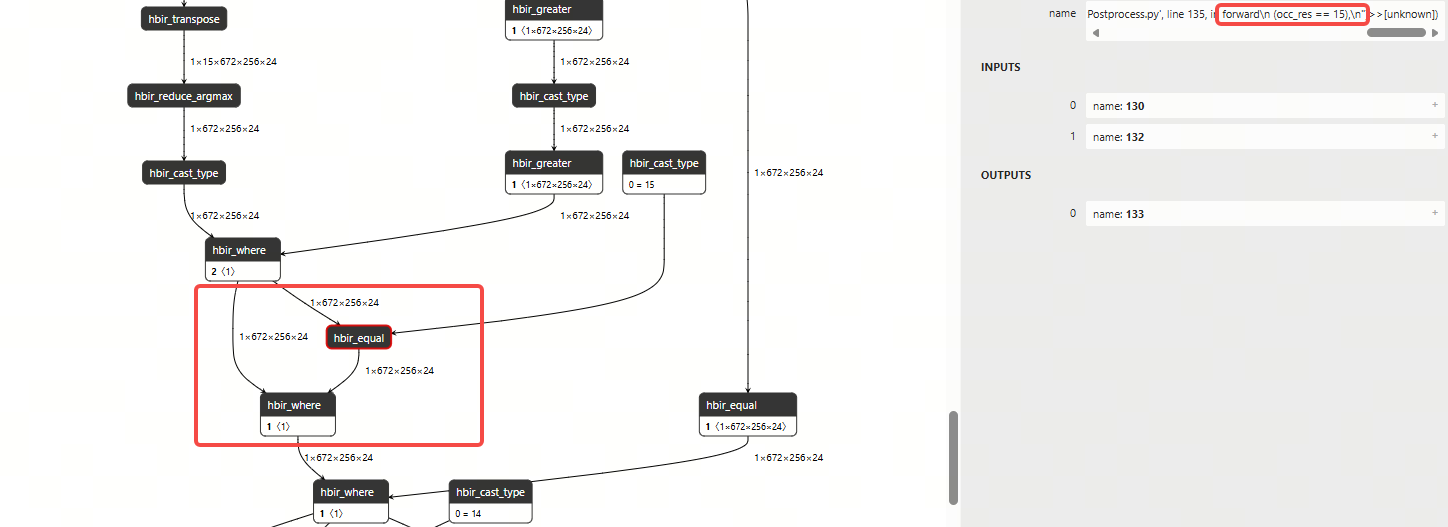
优化后:
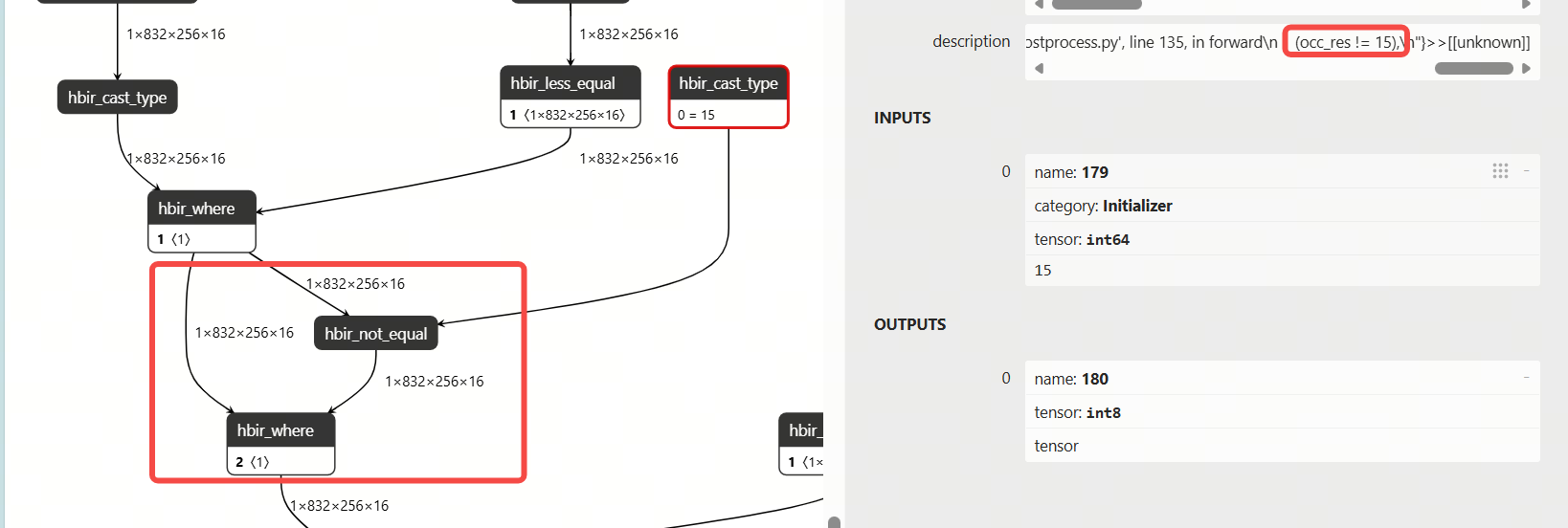
补充真实模型中的性能收益:
模型 | perf性能/ms |
base(优化修改前) | 5.92 |
优化修改后 | 5.59 |
2.2 精度优化
2.2.1 Inverse_sigmoid 部署方案
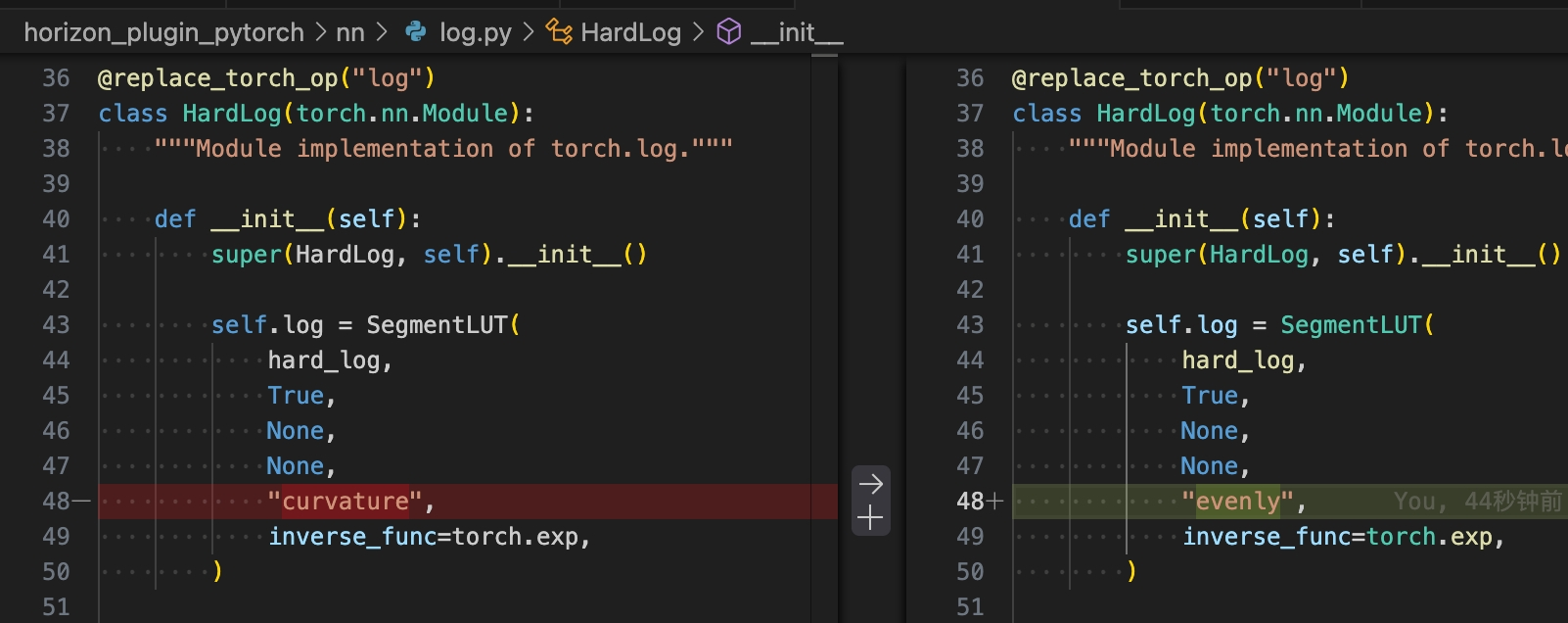
Inverse sigmoid容易出现bc导出掉点问题,若遇到此问题:
方式一:将segmentlut的参数从"curvature"改为"evenly"。
方式二:算法上去除Inverse sigmoid算子,对sigmoid的输入做clamp(需重训,此方案需要验证对浮点的影响。)
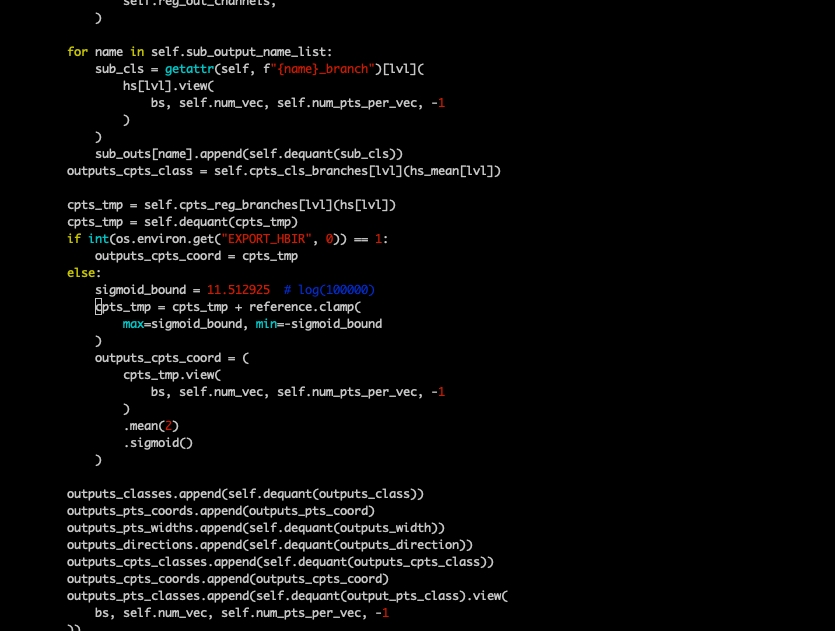
注意:此示例中为提高torch qat精度,将+reference sigmoid放在了cpu,若torch qat并不存在精度问题可以放在bpu中。
11.5219为inverse_sigmoid的输出上限
2.2.2 Gridsample拆分
由于BPU采用定点数值计算,grid_sample 算子在处理较大的W维度时,受限于硬件位宽精度,量化后的数值无法精确表示原始网格坐标,导致nearest (最近邻)和bilinear (双线性插值)两种采样方式均引入一定的精度误差。
示例:
拆分后:
2.2.3 Sin/Cos算子去周期
export时如果发现敏感度排在前面的是sin/cos算子,且输入范围较大(超出-pi~pi一个周期),可以将 sin/cos替换为 plugin的自定义算子,并配置single_period=True,注意需要重新做量化
也可以自行处理sin/cos输入,按照周期性将输入处理到[-pi, pi)之间,注意需要重新做量化
2.2.4 Conv/Linear weight高低位拆分
该方案为保障conv的高精度计算,对weight对高低位的拆分。在用户不重训浮点的情况下,量化训练前需要对用户的浮点ckpt 部分linear weight 进行高低位拆分:
方式1:通过修改plugin源码方式,需要将红框后面的减法去掉
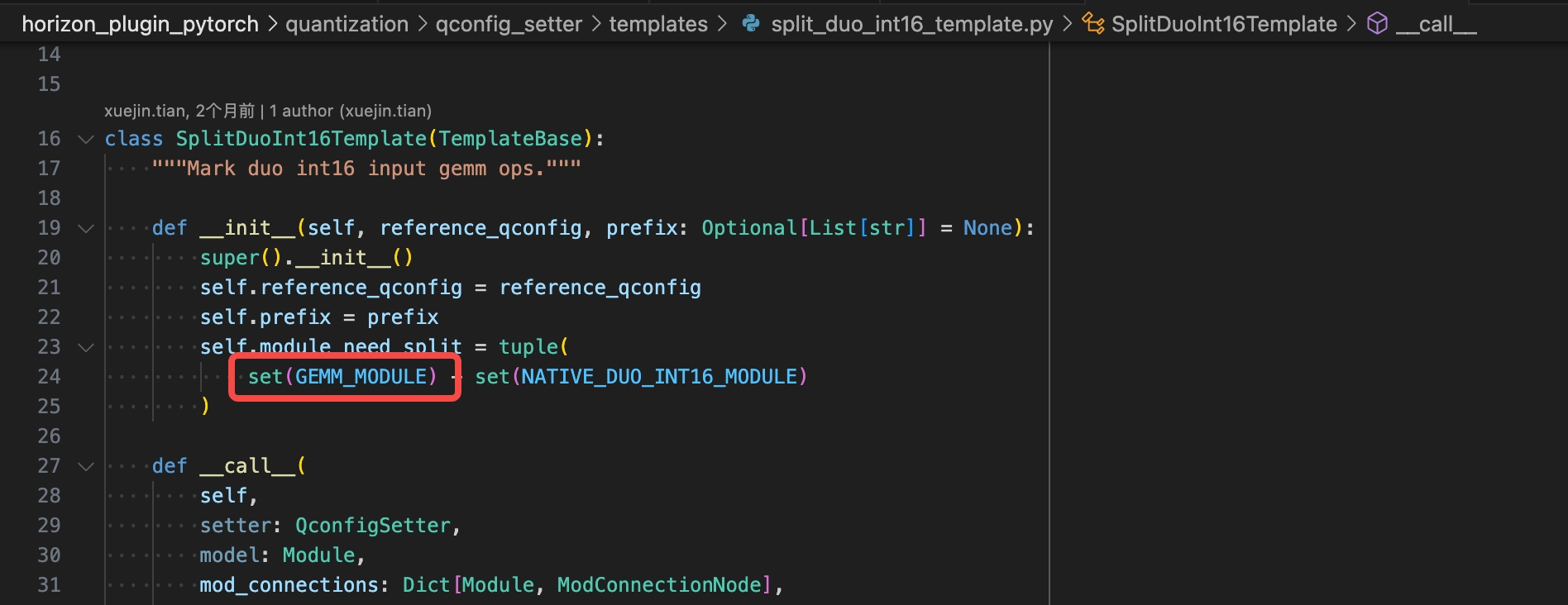
方式2:对model做拆分:
Ckpt weight拆分:
2.2.5 Matmul 高低位拆分
OE 3.5.0 已经支持matmul双int16的量化,如需要双int16输入则配置两个输入为int16量化即可。若使用时存在CPU的bitshift,可以开启VPU使其运行到VPU中,若不需要VPU或双int16存在性能问题时则需要用户在前端手动的对矩阵做拆分,用双int8模拟 int15,达到高精度的效果。
拆分思路:A*(B+C)=A*B+A*C,B为原scale能表示的int8的最大部分,C为剩余部分。
该方案matmul为int15计算,工具为int16。实际使用时可根据性能和精度做平衡。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)