
1. 概述
kernel panic包含了多种内核异常类型,包括但不限于:空指针/异常指针、HungTask、RCU Stall、softlockup、hardlockup、OOM、BUG_ON。
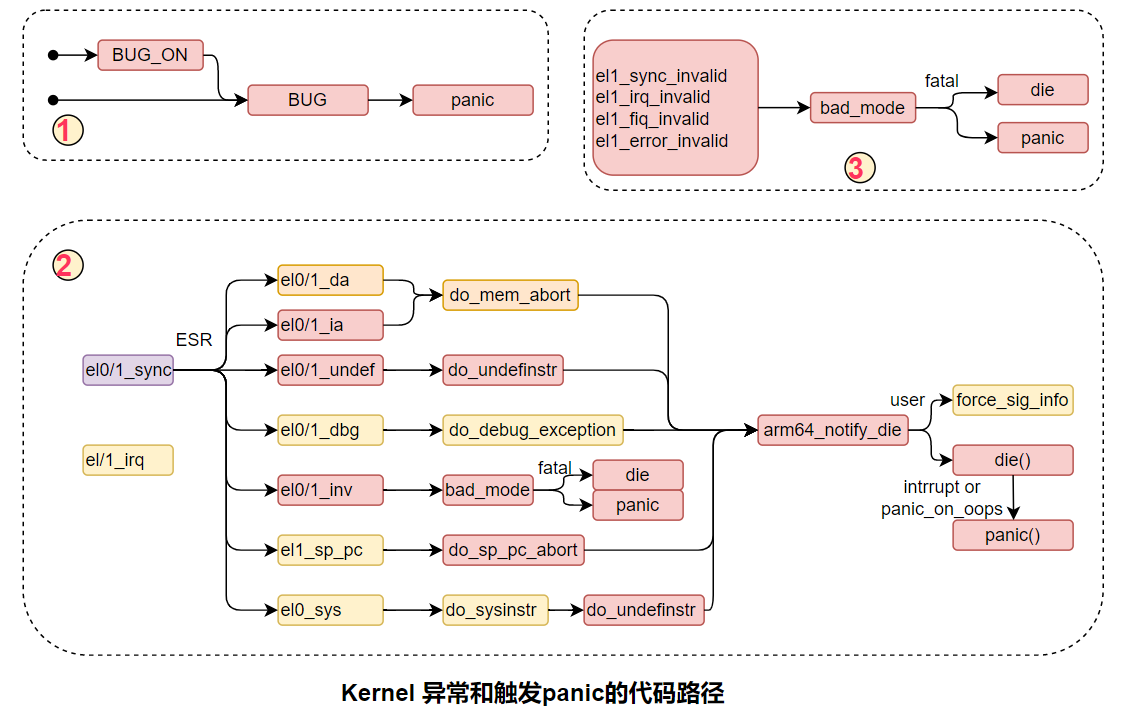
下图是各种类型panic的路径:
2. 通用方法¶
kpanic类异常均为kernel软件可感知到的异常, kernel完成panic流程后会由bl31完成一次WarmReset,所以所有panic现场我们都是能够拿到pstore log的。
由于是软件异常,所以pstore中都能看到异常调用栈、寄存器等信息,通过这些信息就可以初步分析70%的问题。
BUG_ON类是软件主动触发的panic,所以直接检查代码逻辑即可。
对于一些依赖于时序最终产生的panic问题,还需要进一步加log或ftrace进行复现,以跟踪时序(竞争类)引发的异常。
对于复杂的panic问题,还需要开启ramdump功能,抓取dump进行分析。
3. 典型问题¶
3.1. 异常指针访问¶
此类问题代表内核中访问了一个空指针、未映射、没有权限的地址空间,导致触发mem abort。
例:
这类问题,首先我们可以看到mem abort的CPU调用栈,所以马上就能够定位是哪个函数访问的异常地址,如果这个函数比较简单,也就能够很快定位到是哪个变量的空指针访问。
如果函数比较复杂,我们可以使用gdb,addr2line等工具配合符号表进行汇编分析定位代码位置,通过偏移确认变量。
确认异常指针的变量和来源后,有可能是下面的原因导致的错误:
检查调用栈代码,从业务/调用逻辑上看是否存在引入错误指针情况。
检查对应变量相关代码逻辑,考虑是否可能存在竞争风险。
如果异常地址没有发现竞争或引入错误的可能,考虑是否是被踩踏,参考memory correcption节。
检查设备是否存在随机crash的情况,设备是否有单体问题,如果多设备存在随机crash,也有可能是DDR软/硬件配置问题。
3.2. HungTask¶
khungtaskd是内核对D状态的进程进行扫描的内核线程,当内核某进程/线程长期处于D状态,hungtask就会被触发,在J6的系统中,hungtask超时时间设置为120s,且CONFIG_BOOTPARAM_HUNG_TASK_PANIC_VALUE=1,故当hungtask检测到有进程处于D状态超过120s后就会直接触发panic。
例:
这类问题,khungtaskd进程会在触发crash前,将长时间D状态的进程栈都输出出来,所以在pstore中能够快速定位到对应的调用信息。
对于驱动中长时间处于D状态,一般是由于在等待的资源无法获取,需要分析业务流程,对于时间不可预期的资源,可以使用*_interruable族、或*_timout族函数进行优化。
另一类由于死锁导致的hungtask,需要代码分析死锁的根源,可以根据log中输出的所有D状态进程栈和running进程栈进行综合分析,对于大量D状态进程的复杂死锁问题,只能抓取ramdump去分析了。
3.3. RCU Stall¶
RCU(Read-Copy-Update),顾名思义就是读-拷贝修改,它是基于其原理命名的。对于被RCU保护的共享数据结构,读者不需要获得任何锁就可以访问它,但写者在访问它时首先拷贝一个副本,然后对副本进行修改,最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针替换为新的被修改的数据。
释放原来资源的工作由RCU软中断和rcu线程负责,RCU Stall在tick中断中检查,当负责释放线程一直未执行起来(RCU Stall timeout时间为30s),就会出现RCU Stall panic。
例:
所以,当出现RCU Stall问题一般是出现了调度问题:
长时间关闭硬/软中断、中断风暴,RCU软中断无法执行。
长时间关闭强占。
高优先级RT进程占用CPU导致rcu线程无法执行。
由于RT版本中软中断由cfs:19优先级的ksoftirqd负责,rcu软中断的工作可能被各种高优先级强占导致超时。
从RCU Stall的log中能看到发生Rcu Stall的核,检查对应core上进程,及调度情况定位问题,这种问题最好打开ftrace,或者至少打开CONFIG_SCHED_LOGGER抓取到各核的调度信息才能更快的分析。
解决RCU Stall问题的方案:
检查是否存在高负载的RT进程一直被调用。如果存在,请评估是否降低为非RT进程,或者降低优先级。
调整RCU Stall Timeout。修改/sys/module/rcupdate/parameters/rcu_cpu_stall_timeout。
检查/proc/interrupts中所有中断的次数,排除是否是中断风暴导致。
如下面的evt_thread进程每次调度都会占用1s时间:
'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)