
1. 简介
在自动驾驶领域,BEV是一种从上方看对象或场景的视角,通过多个不同视场的传感器融合成BEV特征,可以提供车辆周围环境的完整视图,供下游任务使用,例如障碍物检测,路径规划等。
基于BEV的环境感知目前主要是有两种技术路线,一种是以petr为代表的sparse bev方法,它的主要思路是通过3D位置编码和2D的特征直接生成融合特征,再用基于transformer的decoder实现环境感知,这个过程不需要显式地生成Dense Bev特征; 另一种是以bevformer为代表的dense bev方法,该方法利用内外参信息将2D特征融合到一个BEV特征,再用BEV特征来进行后续的感知或规划任务。基于Dense Bev的方法,可以很方便地实现多传感器融合和多任务预测,因此在自动驾驶领域被广泛应用。
地平线面向智驾场景推出的征程6系列(J6)芯片,在提供强大算力的同时带来了极致的性价比。BEVFormer是当前热门的自动驾驶系统中的3D视觉感知任务模型,我们基于BevFormer与J6芯片,优化了多视图融合生成Dense Bev 特征的方案,进一步提升基于Dense Bev的算法推理效率。本文将详细介绍参考算法对BevFormer中ViewTransformer优化方法以及模型端侧的表现。
2.性能精度指标
模型
| 数据集 | Input shape
| backbone | bevsize
| encoder layers | J6M性能 (FPS) | 检测精度(浮点/定点) | |
|---|---|---|---|---|---|---|---|---|
NDS | mAP | |||||||
BEVFormer | Nuscenes | 480x800 | resnet50 | 50x50 | 3 | 28.51 | 0.3711/0.3686 | 0.2678/0.2630 |
BEVFormer-OPT | Nuscenes | 480x800 | resnet50 | 50x50 | 3 | 36.83 | 0.3713/0.3715 | 0.2673/0.2659 |
BEVFormer为参考算法V1.0版本,BEVFormer-OPT为优化后的参考算法V2.0版本
BEVFormer-OPT使用了Dense Bev的优化方案;
3.优化方法介绍
3.1 整体架构
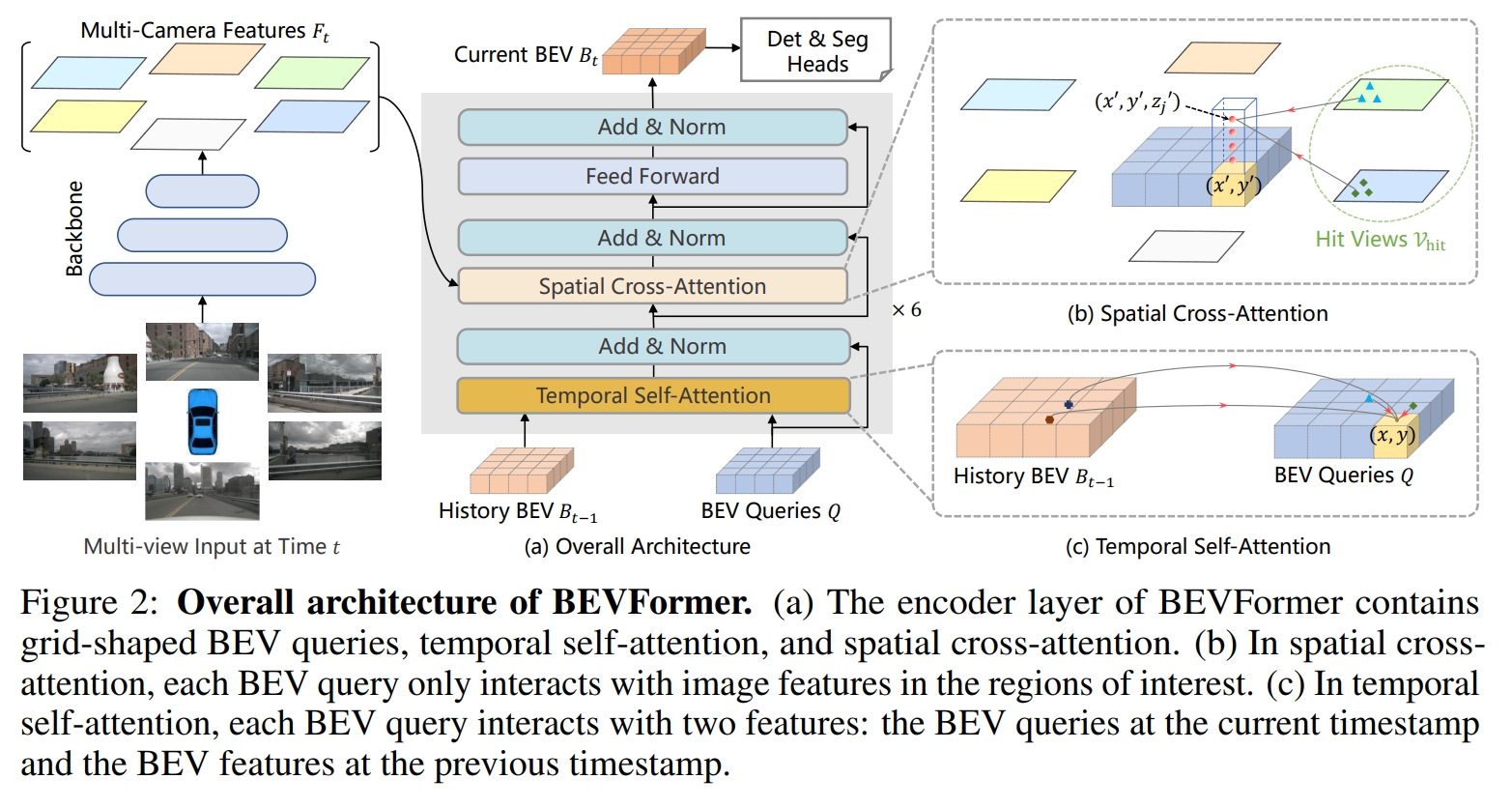
在BevFormer中,SpatialCrossAttention模块是用来做空间融合的,即将多个2D视图特征融合成Bev特征,由于公版的BevMask会根据内外参进行动态变化,进而导致模型中出现动态Shape,对部署非常不友好,因此在V1版本中我们直接去掉了BevMask,虽然对部署更友好了,但是SpatialCrossAttention模块多了很多冗余的计算和IO,对性能影响很大。整体框架如下图所示:
3.2 方案优化点
3.2.1 使用BevMask
在优化方案中,我们对内外参生成BevMask的原理做了详细的分析,发现:
当相机传感器位置固定时,内外参转换矩阵即固定,轻微抖动对BevMask影响不大。
从BEV voxel 的角度来看,中心点到multi camera的映射是稀疏的,在BevFormer开源的代码和模型中,默认利用了这个特性,加速计算而不会带来任何精度损失(也就是上面说的bev_mask)
从BEV pillar 的角度来看,通常每个pillar只会映射到1-2个camera,如上图右上角所示。
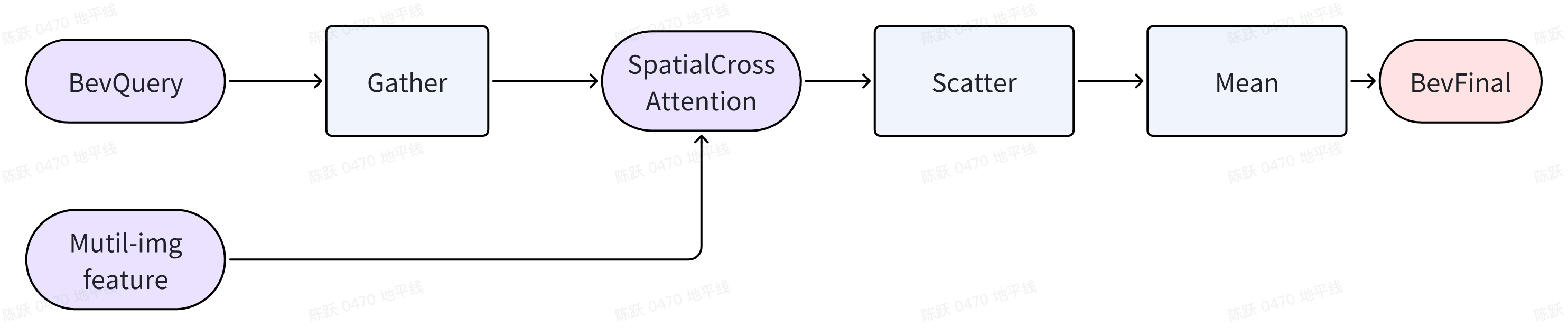
利用到上面的几个特性我们可以减少空间融合模块的复杂度,但需要引入一对gather/scatter操作,以及相关的index计算。即先通过gather将bev空间上的有效点取出来,计算完空间特征融合后,再用scatter将其还原到Bev空间对应的位置,然后根据每个bevpillar的有效点数来算Bev空间每个点的均值即可。
整体框架如下图所示:
为了能编译成静态模型,有2个额外需要关注的设置:
Bev空间映射到每个camera的最大点数。这个可以根据内外参计算得到,但为了应对一些抖动情况,可以适当放开,在Nuscenes数据集上,50*50大小的Bevsize下,我们设置为20*32。 这个数字直观理解就是,最大视场的相机在Bev空间覆盖的区域大小。
每个BEV pillar映射到的最大的camera数。目前是一个静态设置的最大值,可以根据数据统计得到,在Nuscenes数据集中,我们设定为2, 这个数字直观理解就是有视野重叠的最大camera数。
代码均在算法包位置:
hat/models/task_modules/bevformer/attention.py
3.2.2 使用Gridsample高效实现Gather和Scatter
gather/scatter这一对操作在BPU上不是很友好,通过分析这对操作的index我们发现可以换成BPU更友好的方式,即使用Gridsample来实现这一对操作。Index 只受camera内外参的影响,而往往内外参的变化是非常低频的,因此,我们可以把index生成的逻辑放在前处理,按需触发计算,再把生成好的index转换为对应Gridsample需要的grid作为模型输入给到模型,供Gridsample算子直接使用,代码均在算法包位置:
hat/models/task_modules/bevformer/view_transformer.py
根据Gather的Index计算Gridsample的Grid:
根据Scatter的Index计算Gridsample的Grid 和 每个Bev Pillar对应的有效点数:
4. 总结
4.1 优化策略小结
引入 BevMask, 可以大幅度降低空间融合模块的计算量和IO;
根据模型特征,使用BPU友好的OP。
4.2 总结
本文主要介绍了基于Bevformer优化的DenseBev方案,通过减少冗余计算和IO,使用BPU友好OP,相比于v1.0 版本模型,这种方案在精度相当的情况下,在 J6M平台上推理性能提升30%。同时,这种DenseBev的优化经验可以推广到其他相似结构或相似使用场景模型的部署中。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)