
一、引言:算力焦虑与架构之思
无论是云端模型的规模竞赛,还是端侧部署的性能较量,大家都在谈:
“TOPS 更高了、TFLOPS 提升了、推理速度又快了 30%。”
即使两颗芯片的理论算力相近,在真实模型推理中,性能差距可能高达数倍。
大部分推理延迟,并不是因为“算得慢”,而是因为“数据动得太多”。
注:本文为个人理解,仅供技术交流与探讨
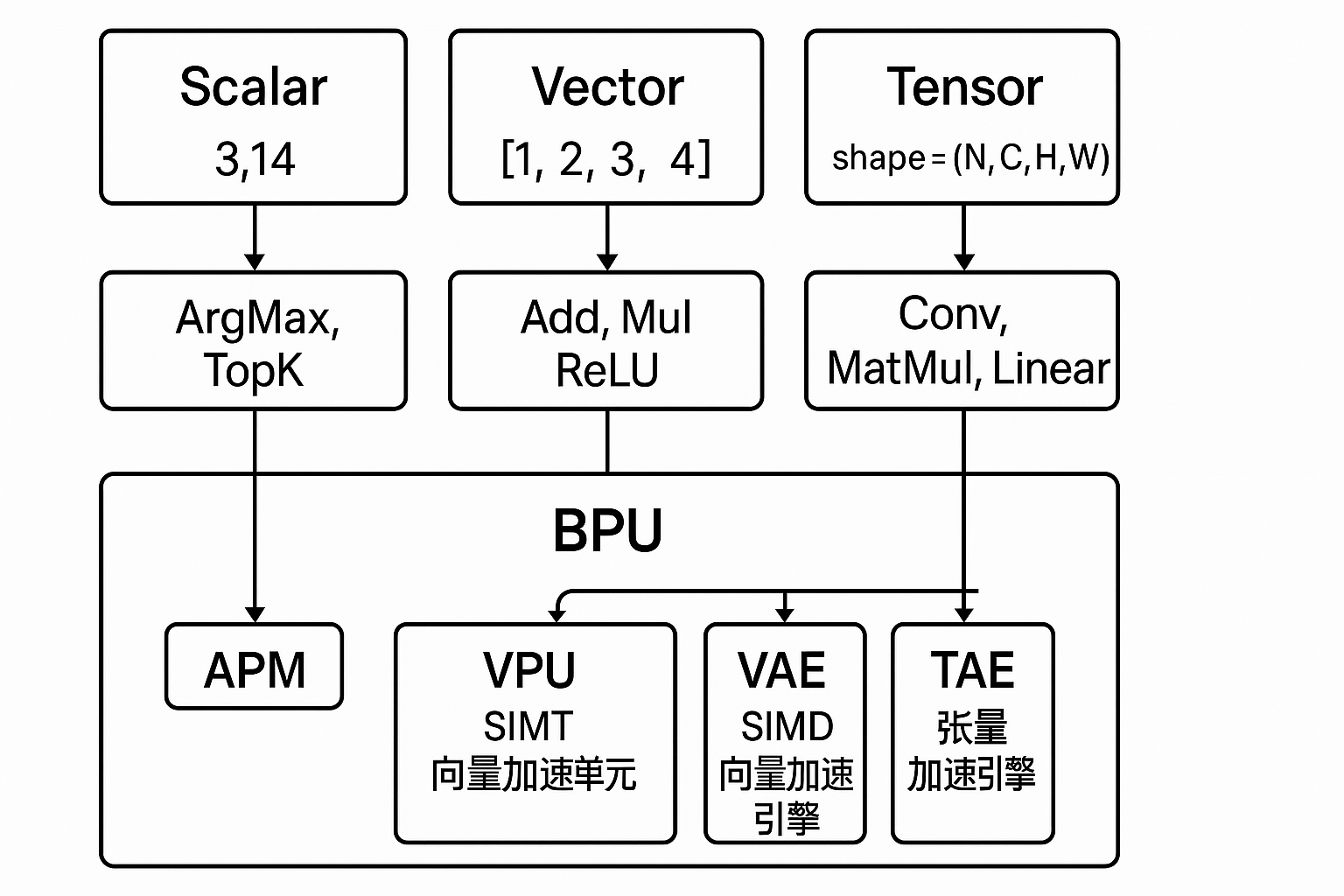
二、模型的三种计算形态:张量、向量与标量
张量(Tensor)、向量(Vector)、标量(Scalar)。
数据类型 | 数学含义 | 示例 | 常见来源 | 主要作用 |
|---|---|---|---|---|
标量 Scalar | 单个数值 | 3.14、-1 | 控制流、阈值 | 控制判断 |
向量 Vector | 一维数列 | [1,2,3,4] | 特征、偏置项 | 局部特征 |
张量 Tensor | 多维数组 | shape=(N,C,H,W) | 特征图、权重 | 主干计算 |
向量承担大部分“局部加工”;
标量则控制逻辑与条件分支。
BPU 的架构正是围绕这三种形态设计的:
- TAE → 张量类
- VAE/VPU → 向量类
- SPU/APM → 标量与调度类
张量决定算力上限,向量决定吞吐效率,标量决定系统智慧。
三、BPU 内部的五大执行单元:分工社会的秩序
BPU 拥有五个核心执行模块,每个都为一种计算类型而生:
模块 | 全称 / 类型 | 主要算子 | 职责定位 |
|---|---|---|---|
TAE | Tensor Acceleration Engine | Conv、MatMul、Linear | 主干计算核心 |
VAE | Vector Acceleration Engine | Add、Mul、ReLU | SIMD 向量计算 |
VPU | Vector Processing Unit | sigmoid | SIMT 向量控制 |
SPU | Scalar Processing Unit | TopK | RISC-V 控制核 |
APM | Accelerator Power Management | DMA、调度 | 任务分配与同步 |
VAE / VPU 是流水加工厂;
SPU 负责逻辑判断;
APM 是指挥与调度中心。
四、从 CPU 到 BPU:计算模式的演进
阶段 | 核心架构 | 特征 | 局限 |
|---|---|---|---|
CPU 时代 | 通用串行 | 灵活通用 | 并行差、能效低 |
GPU 时代 | 通用并行 | 高吞吐 | 分支昂贵、访存多 |
BPU 时代 | 异构分工 | 形态匹配、协同执行 | 定制度高 |
BPU 则追求“合适地算”。
五、协同执行机制:流水中的秩序与配合
BPU 把深度网络执行变成了一条异构流水线:
 {{{width="800"}}}
{{{width="800"}}}TAE 计算第 3 个 block 时,VAE 已处理第 2 个 block,VPU 正在处理第 1 个。
多层流水并行,让 BPU 的有效算力利用率接近 90%。
GPU 追求规模的力量,BPU 追求结构的智慧。
六、性能的本质:算力/带宽/访存的三角关系
- 算力(MAC 数)不是全部:算力 ≠ 性能
- 带宽/复用 才是关键:把数据“算在片上不落地”,单次搬运多次复用;在真实推理中,数据移动的成本往往高于计算本身。
- 调度 决定端到端利用率:APM 让各单元流水不堵车。
架构 | 并行度 | 访存频率 | 计算 | 调度 | 数据复用率 | 有效算力 | 能效 |
|---|---|---|---|---|---|---|---|
CPU | 低 | 高 | 通用 | OS | 低(cache 有限) | 10–20% | 低 |
GPU | 高 | 中 | 通用并行 | 驱动+库 | 中 | 40–60% | 中 |
BPU | 极高 | 低 | 专用阵列 + 异构 | APM 硬件级 | 高(SRAM 片上高复用) | 80–95% | 高(TOPS/W) |
BPU 通过减少 DRAM 访问、提高片上复用率、并行流水,实现了惊人的能效。
七、VAE 与 VPU:SIMD 与 SIMT 的设计哲学
维度 | VAE | VPU |
|---|---|---|
执行模型 | SIMD | SIMT |
控制流 | 无分支 | 可分支 |
优化目标 | 吞吐率 | 灵活性 |
典型算子 | Add, Mul,查表等 Vector | Quantize、Dequantize |
对应逻辑 | 推土机 | 雕刻刀 |
VPU 是逻辑理解者,能处理归约与条件操作。
两者互补,让模型既完整又高效。
八、算子映射与实践优化:从模型到硬件的落地逻辑
模型落地过程:
- 转换 → PyTorch/TF → ONNX
- 编译 → 映射到 TAE/VAE/VPU/SPU/APM
- 部署 → .hbm 模型由 UCP / SDK 执行
典型映射:
算子类型 | 执行单元 | 特征 |
|---|---|---|
Conv / MatMul | TAE | 张量乘加 |
Add / ReLU | VAE | SIMD 并行 |
Sigmoid | VPU | SIMT 逻辑 |
TopK | SPU | 控制判断 |
DMA / 调度 | APM | 任务控制 |
优化原则:融合算子、减少访存、量化友好、任务合理切分。
让数据不动,让计算流动。
九、BPU 的设计哲学:计算的逻辑之美
它通过异构分工,让每种计算形态找到最优归宿。
层级 | GPU 思维 | BPU 思维 |
|---|---|---|
架构目标 | 更多核心 | 更聪明的分工 |
性能来源 | 核数量 | 数据复用率 |
调度方式 | 软件线程 | 硬件协同 |
执行逻辑 | 通用模板 | 形态匹配 |
本质哲学 | 算得多 | 算得巧 |
GPU 是算力堆叠的艺术,BPU 是计算组织的艺术。
 {{{width="550"}}}
{{{width="550"}}}
十、常见误区 与 快速问答
常见误区
- 误区1:把 BPU 当“小 GPU”。→ 错:BPU 更像“定制流水线 + 异构阵列”。
- 误区2:只堆算力忽视带宽。→ 错:访存才是吞吐瓶颈的常客。
- 误区3:把 Softmax 当纯 elementwise。→ 错:它涉及 reduce 与归一化流程,宜走 VPU/SPU 协同。
- 误区4:BN 一定独立执行。→ 误:可融合到 Conv/VAE,减少落地与搬运。
快速问答
Q:为什么 TAE 对 Conv/MatMul 提升巨大?
A:硬件 MAC 阵列把乘加铺开并行;配合片上 SRAM,极大降低访存。Q:Sigmod走 VAE 还是 VPU?
A:通常选 VPU,控制更灵活;SPU 参与 TopK。Q:如何判断算子是否受带宽限制?
A:看“计算/字节”比值(算力密度)。越低越可能带宽受限。尝试合并、复用或减少落地。
十一、结语:当“效率”变成一种美学
更因为它重新定义了智能计算的逻辑:
从“做得多”到“做得对”。
这,就是 BPU 的逻辑之美。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)