
文档版本 | 修订内容 | 修订时间 |
|---|---|---|
v1.3 | 新增第10章-UCP中继续模式使用 | 2026/07/07 |
v1.2 | 新增第9章-UCP环境变量详解 | 2026/06/23 |
v1.1 | 新增3.2.5节-LRU内存优化 | 2026/06/22 |
v1.0 | 初始版本 | 2025/10/26 |
1. 前言
在模型板端部署过程中,开发者主要关心图像如何获取,模型性能如何评测以及如何优化模型等问题。对于图像的获取,地平线提供了Pyramid硬件,其不但可以获取多尺寸图像,且利用内存共享机制可将内存给到BPU直接进行推理。针对耗时,内存占用,DDR带宽占用等指标进行评测和优化,地平线提供了诸如Trace,hrt_ucp_monitor等一系列性能分析工具用于性能监测,使得开发者能够清晰掌握模型运行时的资源占用和硬件效率。最后,地平线提供VP,HPL以及DSP多种模块用于前后处理环节的算法开发。本文将结合实例说明模型如何进行部署,性能分析以及常见的问题解析。
2. UCP简介
UCP还定义了一套统一的异构编程接口,支持对SoC上各后端硬件资源的调用,包括BPU、DSP、ISP、GDC、STITCH、JPU、VPU、PYRAMID 等,以完成 SoC 上任务的统一调度。
UCP 的架构图如下所示:
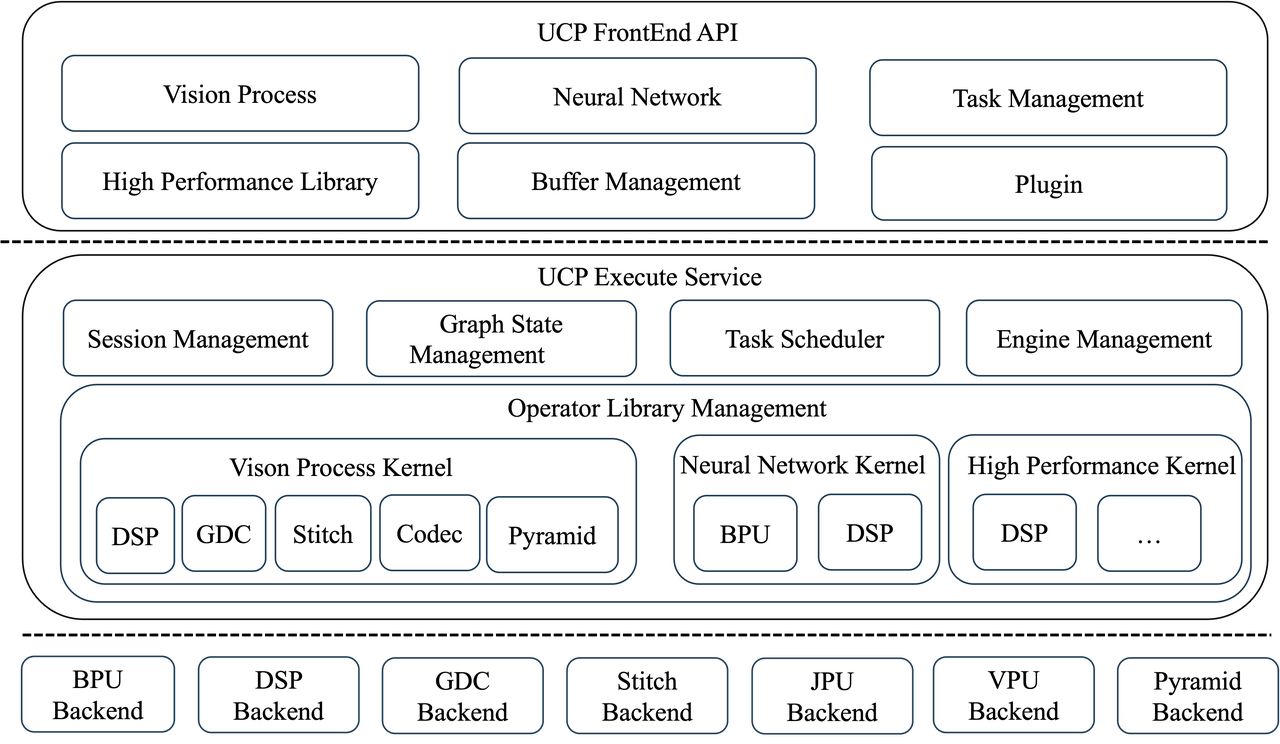
backend | 描述 |
|---|---|
BPU | Brain Process Unit,地平线神经网络计算单元。 |
DSP | Digital Signal Processor,数字信号处理器,是一个可编程的硬件单元。 |
GDC | Geometric Distortion Correction,几何畸变校正模块,可对输入图像进行视角变换、畸变矫正、图像仿射变换等操作。 |
STITCH | stitch,图像拼接模块,可对输入的图像进行裁剪,拼接,拼接模式分别有:alpha融合、alpha beta融合、直接拷贝。 J6B 上没有此器件。 |
JPU | JPEG Processing Unit,主要用以完成JPEG的编解码功能。 |
VPU | Video Processing Unit,是一种专用的视觉处理单元。 |
PYRAMID | Image Pyramid,图像金字塔,可对整幅原始图像进行缩小。 |
ISP | Image Signal Processor,图像信号处理模块,可以将富含图像原始信息的RAW格式转换为易于传输处理的YUV格式。 |
3. 模型推理
3.1 快速上手

⚠️上面的例子仅为demo,实际使用时,需要注意以下几点:
图像可以直接从Pyramid接口直接获取nv12的输出,无需进行拷贝,可直接传递给BPU进行推理
输入输出内存的大小和对齐stride,详见第5.3节说明
接口进行返回值检查,以保证函数的正确执行
3.2 实用技巧
3.2.1 添加desc
有的时候,为了方便自动化作业,需要给不同的模型,输入和输出打上标签以区分他们。
需要注意的是,如果是为输入添加描述信息,由于pyramid和resizer节点会改变bc的输入节点数,因此需要给对应每个节点都添加对应的信息。
比较推荐的做法是在compile之前再添加:
模型部署时,通过下面的接口来获取描述信息:
3.2.2 模型打包
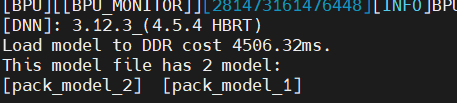
推理测试时,用model_file指定hbm路径,model_name指定具体哪一个模型

3.2.3 小模型批处理
由于BPU为资源独占型硬件,对于那些耗时较短的小模型,其框架调度耗时开销可能大于其模型运行时间,为了缓解这个问题。在J6平台,UCP支持通过复用task_handle方式来一次将多个模型下发,全部执行完成后再一次性返回,从而将N次开销合并为一次:
3.2.4 优先级抢占
此时很容易出现BPU计算资源被一个大模型任务独占,进而影响其他高优先级模型任务的执行,针对这个问题,工具链采用cpu调度的机制来优化BPU资源:
hbm模型在BPU推理表现为一个或多个function-call,function-call为BPU最小的执行单元。当一个模型的所有function-call都执行完成时,这个模型也就执行完成了
BPU模型任务抢占粒度设计为function-all,如果一个模型只有一个function-call那么其无法被抢占,如果一个模型有多个function-call可能出现这个模型完成部分function-call后,BPU挂起当前模型,然后切换执行其他模型
UCP支持任务优先级调度和抢占,可通过hbUCPSchedParam结构体进行配置:
priority:任务优先级,支持[0, 255]之间的数值,对于模型任务而言:
[0, 253]普通优先级,不可抢占其他任务,但在未执行时支持按优先级进行排队
254:为high优先级,支持抢占普通任务
255:为urgent优先级,支持抢占普通任务和high任务
可被中断抢占的任务,需要在模型编译阶段配置max_time_per_fc进行模型拆分
customId:自定义优先级
backend:任务硬件id
- deviceId:设备ID
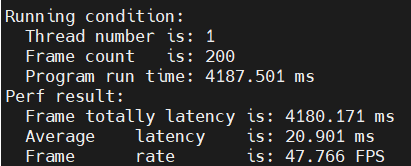
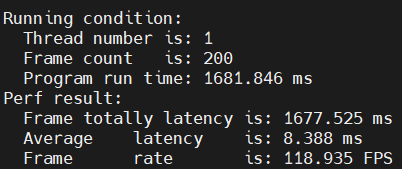
比如,有下面的两个模型,一个单线程耗时20.9 ms,一个单线程耗时8.3ms:
 |  |
|---|

当将模型2的优先级设为high,模型1仍为普通优先级时:
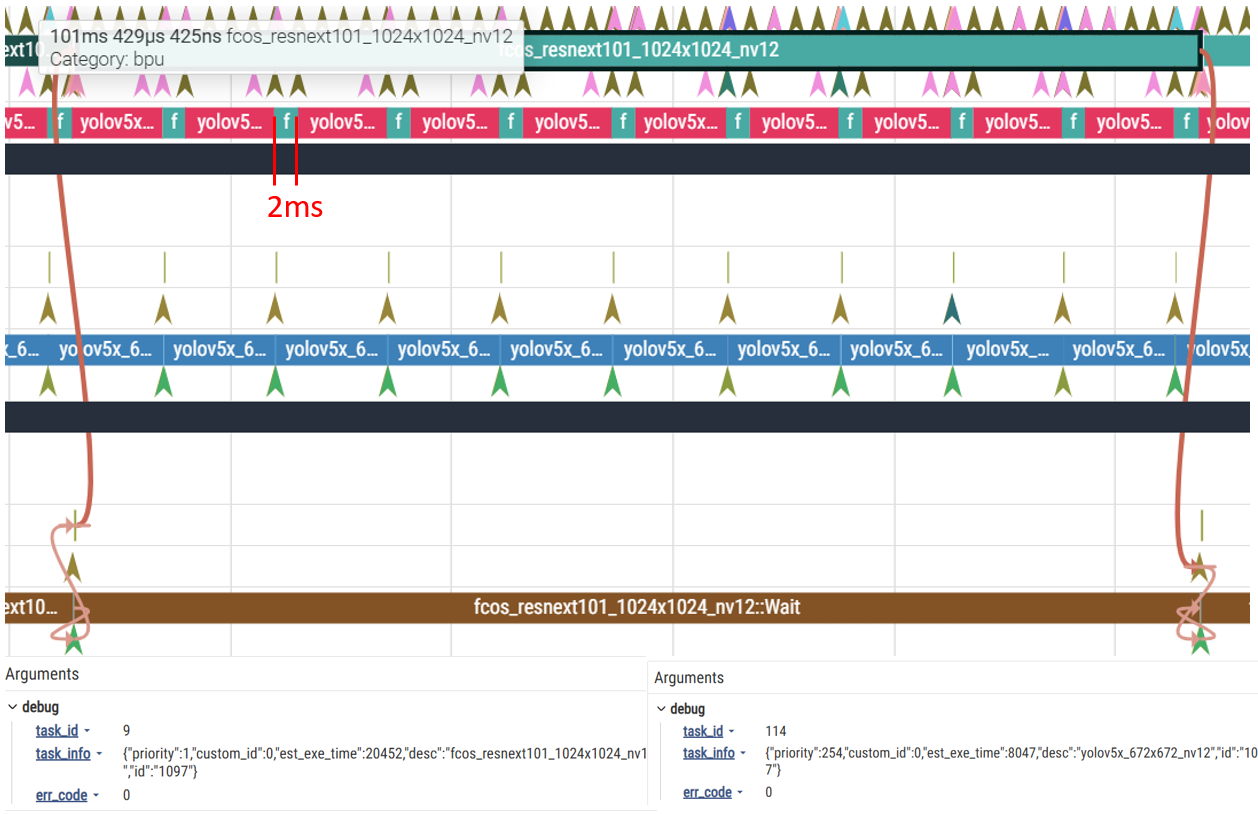
可以看到,在下面的模型一次infer过程中,模型被切分为多个2ms运行的function-call运行,中间插入了很多high优先级模型,导致一次模型前向耗时大大增加。
3.2.5 LRU内存优化
3.2.5.1 什么是LRU
在UCP中也存在着近似于OS LRU的功能, 主要用于优化BPU内存的map/umap操作的缓存策略。在使用BPU的内存时,NN模块需要对该块内存进行映射处理map操作才能被BPU正常使用,在使用后需要unmap。如果频繁对模型输入输出内存执行map/unmap,会导致cpu负载变大。LRU主要是通过缓存已map的内存块,减少虚拟内存重复map/unmap的操作,从而降低cpu开销。提升推理性能。
3.2.5.2 使用说明
HB_NN_ENABLE_MEM_LRU_CACHE:设置NN模块是否使用内存LRU缓存,true为使用,默认为false不使用
判断是否开启LRU内存可以通过配置NN模型环境变量HB_NN_LOG_LEVEL=1来确认。
HB_NN_MEM_LRU_CACHE_CLEAN_INTERVAL:置NN模块清理LRU缓存的时间间隔,单位为毫秒,默认为1000ms及1s之后再释放
推荐使用场景:模型输入输出内存被频繁使用的场景(如连续推理、多帧处理);频繁申请/释放BPU内存导致CPU负载过高的场景。
不推荐使用的场景:模型输入输出内存仅使用一次,或使用频率较低的场景。
3.2.5.3 注意事项
LRU缓存功能只适用于BPU推理模块,其他模块没有此功能
在开启LRU后,内存在调用释放接口后,不会立即释放,因此需要注意,如果频繁释放和申请,可能存在内存泄漏感知风险
LRU功能暂时不支持跨进程
3.3 输入输出处理
3.3.1 Crop裁剪
限制:
图像输入大小要大于模型实际输入大小,w_stride要32(E/M)/64(P/H)字节对齐
模型的validShape为固定值,stride为动态值
裁剪偏移的输入首地址要32对齐
3.3.2 Resizer
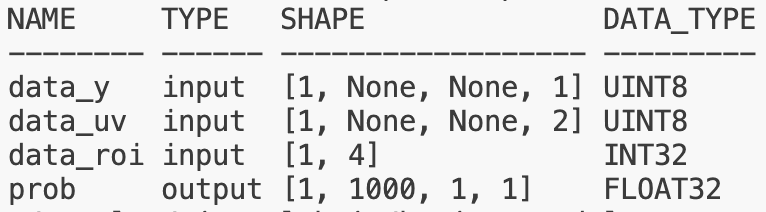
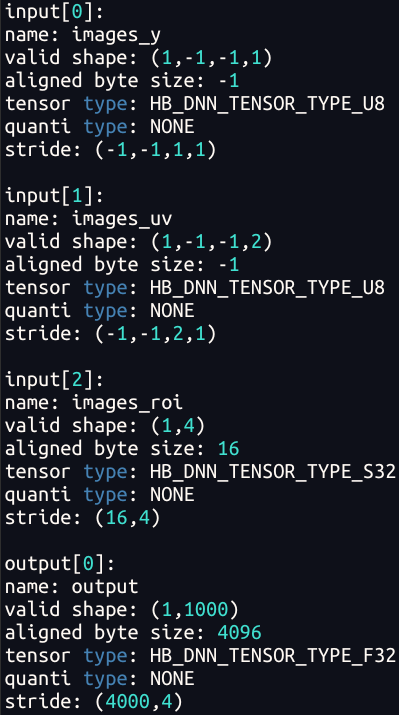
3.3.3 图像tensor对齐
在J6芯片,有一块叫Pyramid的金字塔硬件处理模块,可提供Camera输入图像的缩放及ROI抠图能力,其输出为nv12类型的图像数据,并可基于共享内存机制直接给到BPU进行模型推理,因此在J6工具链中:
Pyramid模型是指具有nv12图像输入的模型
- Resizer模型指的是具有nv12图像输入和ROI输入的模型,编译器支持通过JIT动态指令的方式,从nv12图像上完成ROI抠图+Resize功能
J6P/H要求nv12 stride满足64对齐,J6E/M/B是32对齐。
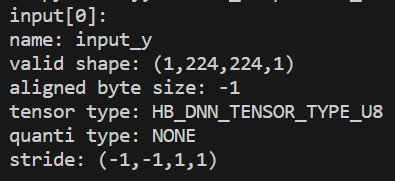
Pyramid的输入stride为动态,比如模型输入为224x224的nv12图像,其格式为:
 | 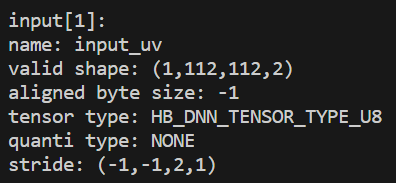 |
|---|
其中,-1为占位符,表示为动态,Pyramid输入的stride为动态。那么此时我们就需要通过手动计算方式来获取了:
输入申请的大小可以通过aligned byte size来获取:
3.3.4 内存单元对齐
J6H/P tensor最小申请内存是256字节,J6E/M是64字节,J6B是128字节,这个差异会体现在模型的aligned byte size和stride属性上。
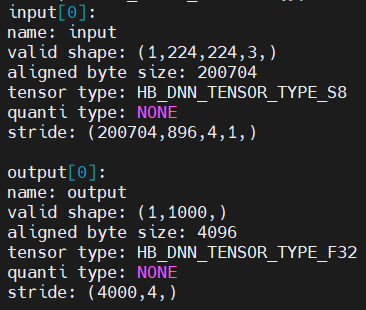
举个例子:
上面模型的stride=4000,output需要申请的内存为4000Byte,但由于内存需要对齐,所以实际上的需要申请的内存大小为((4000+(256-1))&~(256-1))=4096Byte。
在模型实际部署中,非图像输入/输出节点所需申请的内存大小均可以从模型节点属性的结构体中读取到,因此无需特别关注:
3.3.5 padding
由于内存单元对齐的影响,feature申请的大小和拷贝需要根据stride和alignedByteSize来进行。用户侧需要手动处理这些padding,可能对前处理和后处理的代码有较大的变动。这里地平线提供了一种优化方案:input_no_padding/ouput_no_padding,在开启这两个选项后,可以直接将输入/出实际大小的内存送入接口,接口内部会自行处理对齐,无需用户侧修改代码。但开启这个参数后,可能会对模型延时产生微小影响。
- input_no_padding:对所有非图像的输入去padding
- output_no_padding:对模型所有的输出去padding
若编译时配置了input_no_padding=True,output_no_padding=True,无需关注非图像的对齐问题:
举个例子,比如一个模型的输出shape为1x21x21x255,其output_no_padding=False和output_no_padding=True的结果如下图所示:
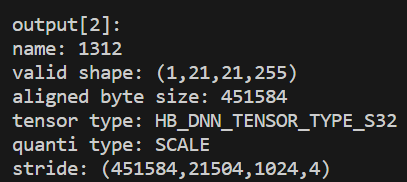 | 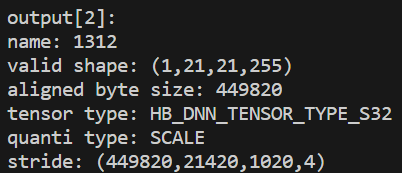 |
|---|
4. 性能分析
4.1 模型性能分析
如果开发者没有实体板子,只有hbm模型,可以使用hbdk4中的hbm_perf接口获取静态性能评估文件(html,json格式)以及模型耗时:
模型中如果有CPU算子,则会影响perf的结果,建议去除CPU算子之后再进行分析。CPU算子一般可以通过以下两种方式查看到:
convert之后的模型可视化,然后查询是否有hbtl类型算子
利用statistics接口统计bc模型算子类型
如果有与开发环境直连的板子可以使用下面的方式进行测试,与实测偏差会更小:
4.1.1 带宽占用
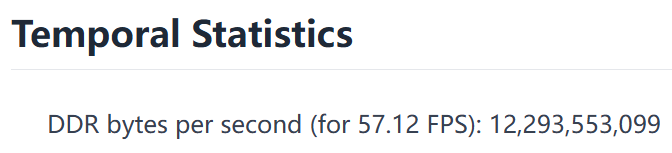
平均带宽
平均带宽(GB/s) = DDR bytes per second( for n FPS)/n * 设计帧率/2^30,以下面的模型为例,实际需求帧率为30FPS,那么该模型所需的平均带宽为:12293553099/57.12 * 30/2^30 = 6.01GB/s:
 |  |
|---|
峰值带宽可以通过推理带宽柱状图来进行分析,最高的柱子即最大的load/strore带宽。比如下面这个图,该模型的最大load需求为15515MB/s=15.15GB/s,最大的store需求为13125MB/s=12.82GB/s,最大的load+store需求为11954+11812=23766MB/s=23.21GB/s
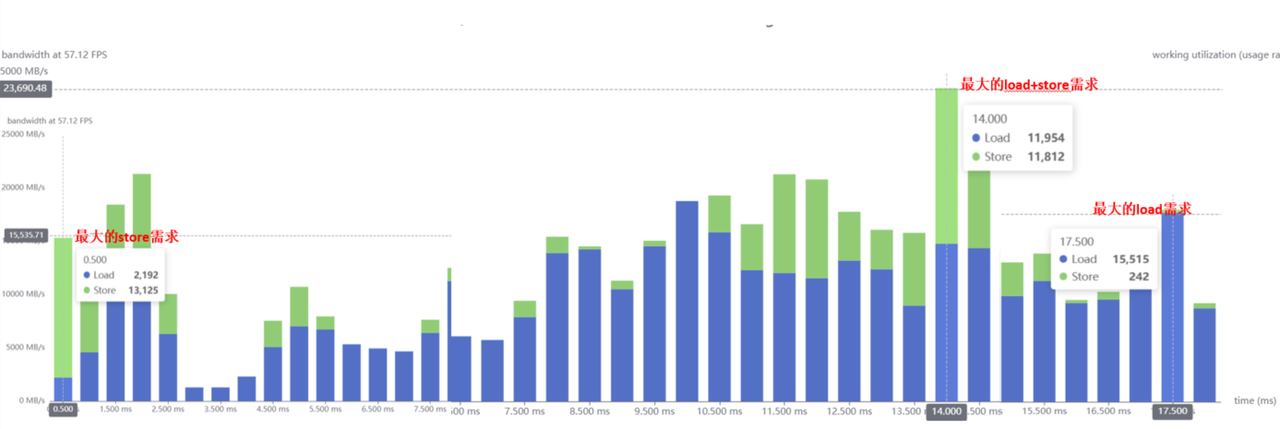
4.1.2 带宽优化
BPU模型的带宽消耗主要集中在模型加载、推理时的featuremap读写,输出写回,优化策略如下:
使用balance参数来平衡带宽和延时
ptq时,修改配置文件中的compile_mode:
对于小模型使用多batch推理模式,可以减少weight的加载次数
减少模型抢占调用:优先级255的抢占任务会刷新整个SRAM,导致大量带宽开销,建议通过任务编排方式运行模型,而不是优先级抢占
Batch拆分:若模型需要concat多路输入(比如BEV类模型),将batch mode拆分,每一路单独提取特征,牺牲很少的延时来降低峰值带宽
4.1.3 内存占用
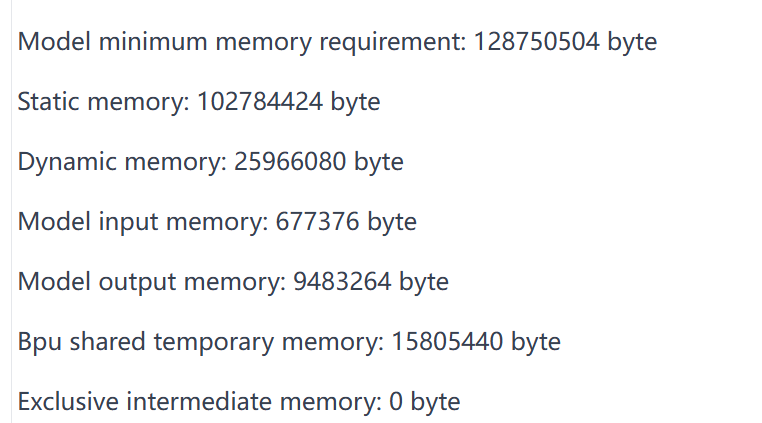
含义 | |
|---|---|
Model input memory | 模型输入内存 |
Model output memory | 模型输出内存 |
Shared temporary memory | 运行时内存 |
Intermediate memory | 运行时内存 |
Dynamic memory | 前面的相加 |
Static memory | hbm文件大小 |
Shared temporary memory共享临时内存,主要目的是用于相同优先级模型共享内存,优化模型推理内存的使用。对于相同优先级的模型,会共享temporary memory。该功能的约束条件:
跨BPU Core不可用
跨优先级不可用,0-253的优先级之间的都可以共享,254只能和其他254共享,255只能与其他255共享
跨进程不可用
当开发人员对模型运行时所需内存进行评测时,可先通过Summary的内容先进行静态数据评估,模型的内存占用=Static Memory + Dynamic Memory。
4.2 动态性能分析
在模型的部署和运行过程中,我们比较关注模型的推理耗时,bpu/cpu占用,DDR读写带宽以及内存占用。这些信息可以通过以下工具来获取:
4.2.1 hrt_model_exec
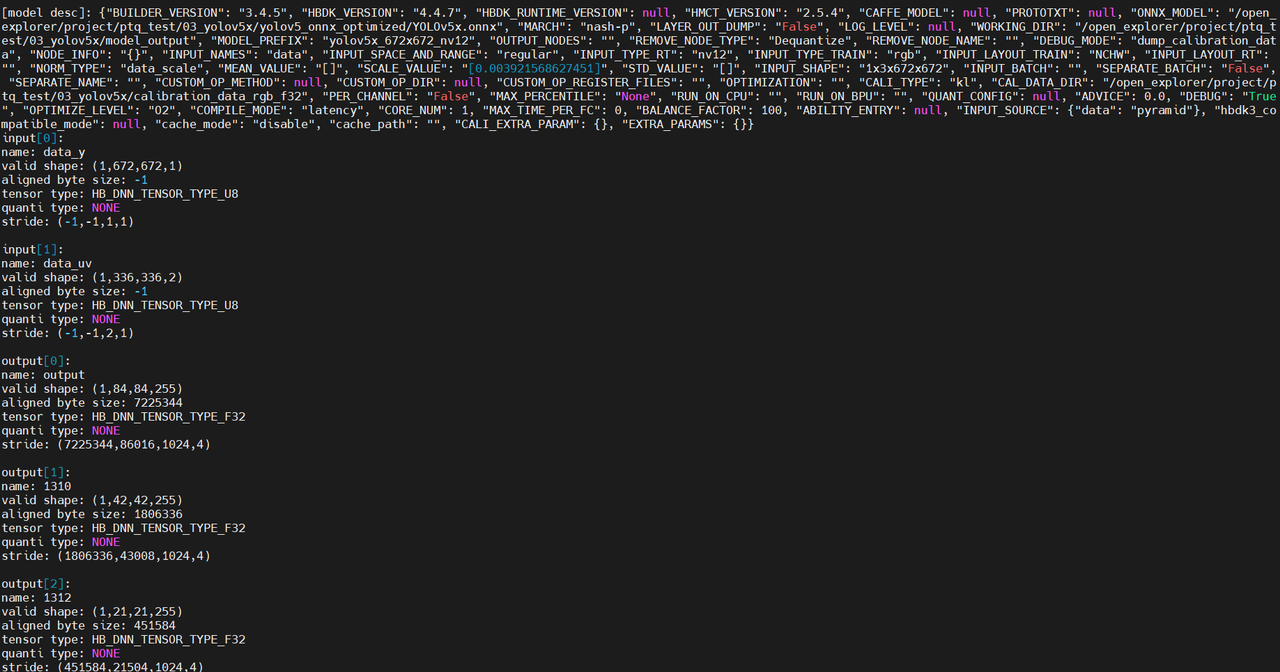
模型输入输出信息:
模型单线程耗时:
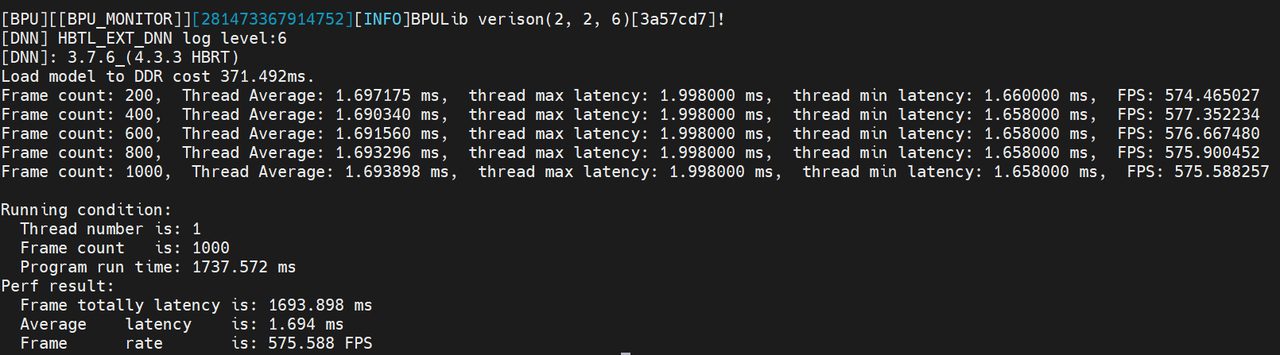
模型多线程耗时:

指定优先级运行:
4.2.1.1 单线程和多线程差异
在多线程下,工具会启动多个线程进行模型推理,统计得到的FPS表示充分使用资源情况下模型的吞吐量,主要用于评测高并发情况下的模型处理能力。
- 为什么单线程模型运行耗时比多线程耗时短?
答:由于BPU本身是一种独占硬件,同一时间只能运行一个任务,多个线程同时提交任务时,只能按一定顺序执行,因此多线程模式下,模型的Latency耗时的增大,主要来源于任务下发后的等待时间。
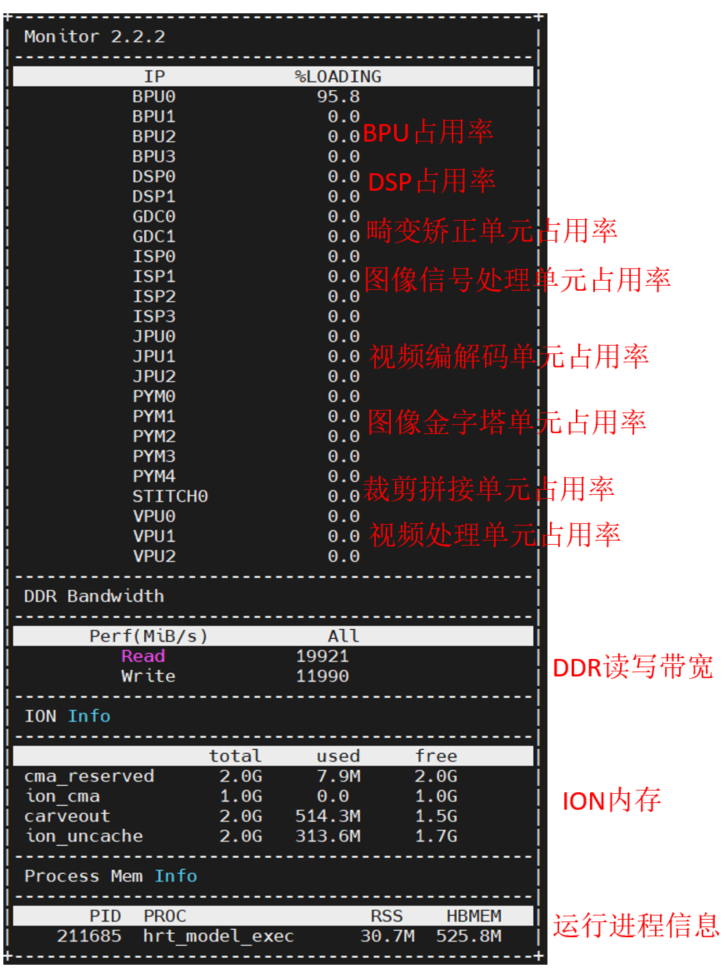
4.2.2 hrt_ucp_monitor
hrt_ucp_moitor支持的内存信息包括DDR读写带宽,ION内存,进程内存,默认为每秒采样 500 次,详细的运行参数请参考《hrt_ucp_monitor 工具》。
hrt_ucp_monitor 是一个监控硬件 IP 占用率和内存信息的工具,在使用UCP提交任务时,可以指定任务部署的后端(Backend),这些后端与本文档中的硬件IP相对应。 hrt_ucp_monitor 工具位于 horizon_j6_open_explorer 发布物的以下路径中: Linux 系统:samples/ucp_tutorial/toolsQNX 系统:samples/uc
。在终端运行命令hrt_ucp_monitor即可看到对应的监控信息:
rss查看可以通过以下命令查看:


HBMEM为应用进程申请的总ION大小:
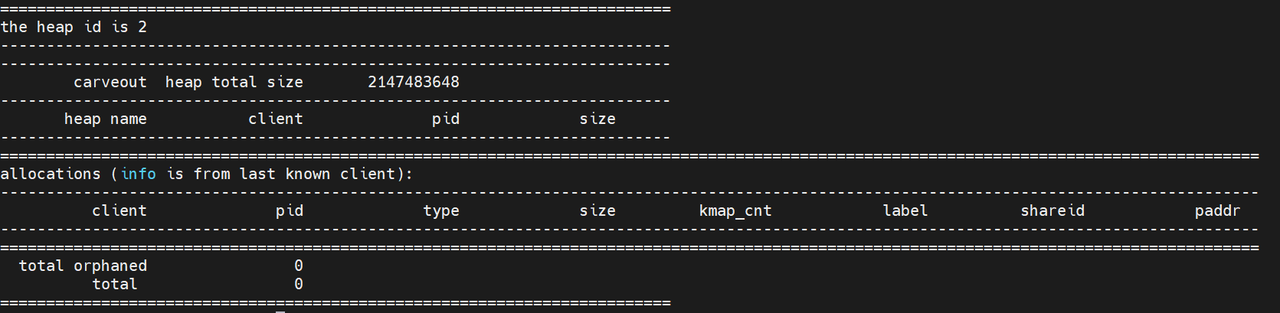
ION:ION是为了解决内存碎片化而引入的通用内存管理器,一共有三种:ion(上面的ion_cam),reserve(上面的cma_reserved)和carveout(上面的carveout)。ion是主要类型,用于一般的内存分配。reserve本质上也是carveout,区分的主要目的是DDR支持多个bank。对于BPU模型来说,其优先在carveout上分配内存。可以通过观察 /sys/kernel/debug/ion/heaps/carveout来测试内存占用:
上图为未加载时,carveout的状态
模型加载后,carveout的状态

4.2.3 hrut_ddr
带宽占用主要使用hrut_ddr来进行分析:

4.3 问题
在实际的运行中,可能会出现与上面带宽评测结果差距较大的情况。这是由于在实际中不仅仅是模型的运行需要带宽,cam和cpu也是需要带宽的。根据过往的经验,可以根据峰值带宽和均值带宽来提前判断是否存在风险,高于理论带宽的75%以上,就需要进行测试验证了。
5. 推理典型问题处理
5.1 timeout问题
5.1.1 模型timeout时间是否设置合理
如果模型是异步推理的,模型本身执行的时间较长,而异步等待接口设置的超时时间不足也可能造成timeout。
timeout的耗时可以设置为模型正常推理时间的一倍即可。
5.1.2 CPU负载是否过高
在运行过程中,可以使用top/htop等监视CPU利用率,如果CPU负载超过90%,可能出现系统异常,这个必须得到解决
5.1.3 内存泄漏
当存在内存泄漏时,在系统内存不足的情况下,内存申请缓慢,可能会导致推理超时。可以在编译时添加检测:
或在单元测试时,利用getpid()获取当前进程的pid,再查看/proc/pid/status中的VmRSS。
5.2 推理hang
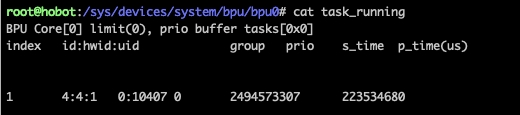
s_time不为空表示任务已经正常开始,而p_time一直增加没有减少,即可认为BPU任务hang住了, 可以使用watch命令来记录bpu任务情况:
如果发生此类问题,可以提供bpu log给地平线技术支持人员分析,log的地址在:/log/bpux/message 中。
5.3 log获取
在遇到上面的问题的时候,我们可以通过分析日志来获取问题原因,需要的是UCP日志以及系统日志:
5.3.1 UCP日志
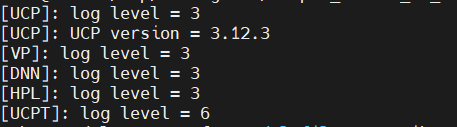
在发生上面的问题后,为了获取具体的问题原因,可以修改log等级来抓取不同等级的日志,配置方式如下:
UCP log设置主要通过以下环境变量:
HB_UCP_LOG_LEVEL:ucp模块log等级(等级从0到6,分别为trace, debug, info, warn, error, critical, never, 默认为warn)
HB_NN_LOG_LEVEL:nn模块log等级
HB_UCP_LOG_PATH: ucp日志存储路径
5.3.2 系统日志
dmesg:在Linux系统中用于显示或控制内核环形缓冲区的内容更,允许查看或操作内核消息。
logcat:可以用于打印设备的系统日志
6. UCP Trace使用
UCP Tracer记录点:UCP记录点包括任务trace记录点和算子trace记录点
trace类型 | 名称 | 说明 |
|---|---|---|
算子 | SubmitOp | 算子提交 |
OpInfer | 算子开始执行 | |
OpFinish | 算子执行结束 | |
任务 | hbDNNInfer | 创建模型推理任务 |
hbDNNRoiInfer | 创建ROI模型推理任务 | |
hbVPxxx | 创建视觉处理任务 | |
hbHPLxxx | 创建高性能计算任务 | |
hbUCPSubmitTask | 任务提交 | |
${TaskType}:Wait | 等待任务执行结束 | |
TaskSetDone | 通知任务执行完成 | |
hbUCPReleaseTask | 任务释放 |
6.1 in_process模式
6.1.1 运行实例
启动步骤:
ucp_in_process.json
ucp_in_process.cfg
在该目录下会生成trace文件:文件名为output_path中配置的文件名:

1.Perfetto不支持自动覆盖,如果设置路径中有之前的ptrace文件会报错
2.ucp_in_process.json中指定的文件路径是相对路径,需要配置文件和脚本放在同一个路径下

6.1.2 结果解析
选择生成的ucp.pftrace文件,选中一个带有forward::Wait字样的一块,如下图所示:
单线程+多帧

多线程+多帧
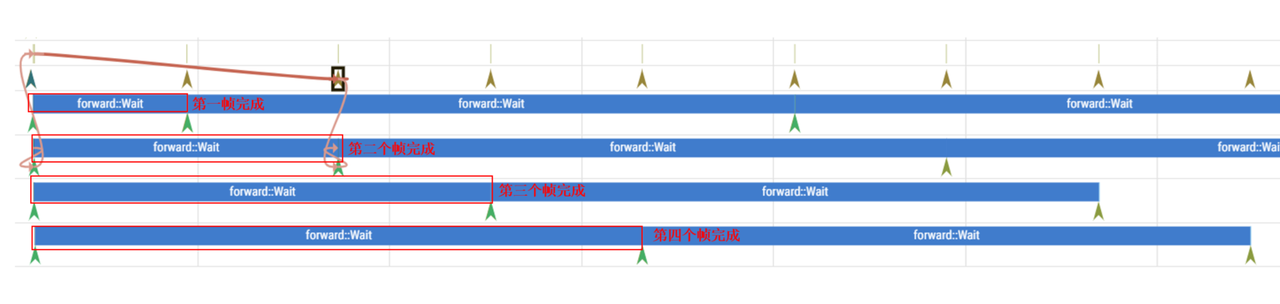
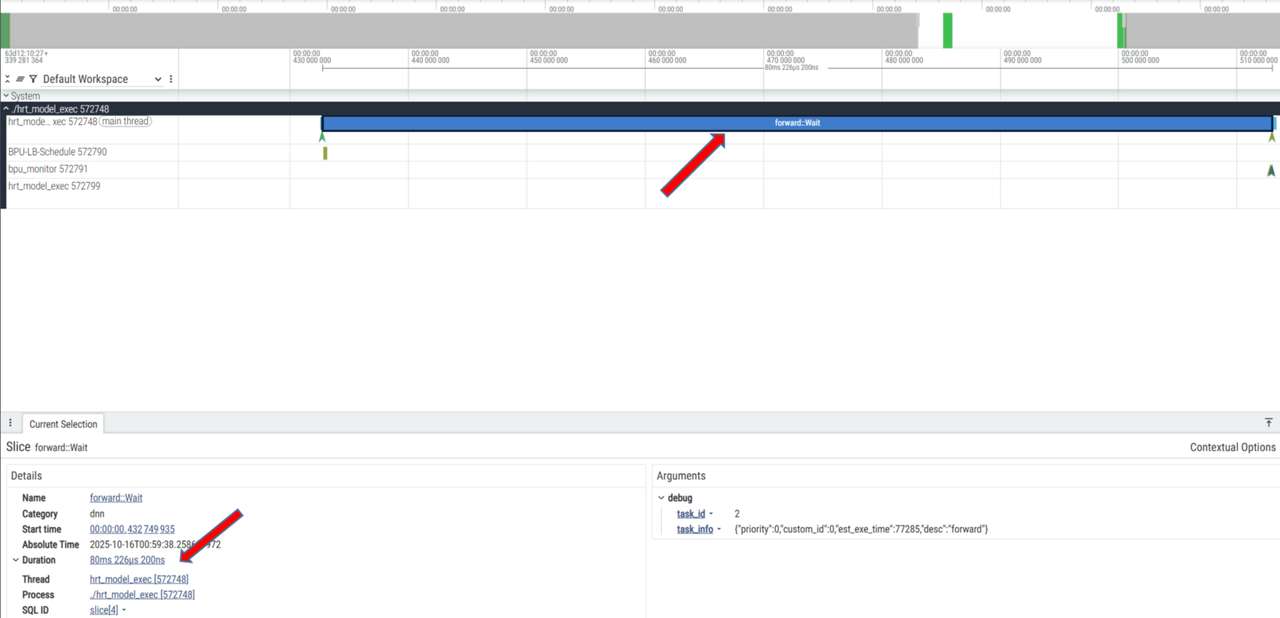
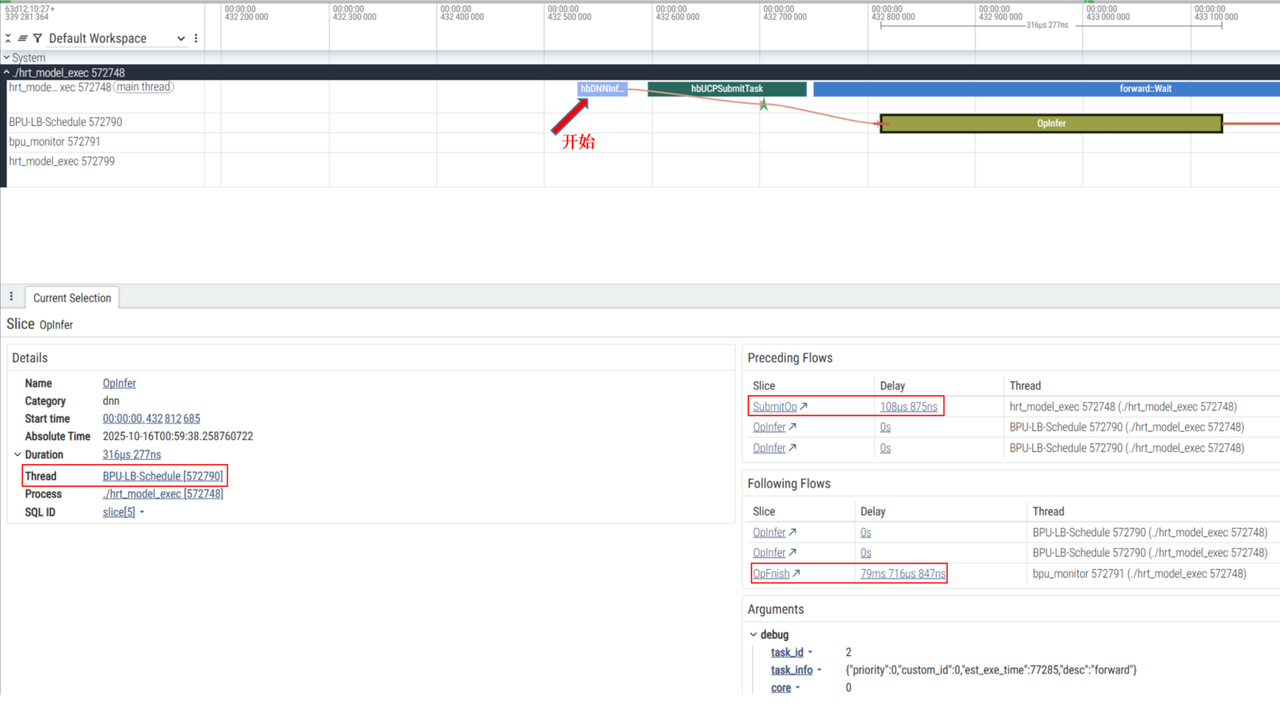
如何分析:
查看UCP内部调度是否正常例如哪块耗时明显高于预期
观察BPU是否持续在使用:例如两个BPU Opfinish之间的耗时是否符合预期,继而判断任务编排是否合理,任务下发是否及时
多线程+多帧+CPU结果
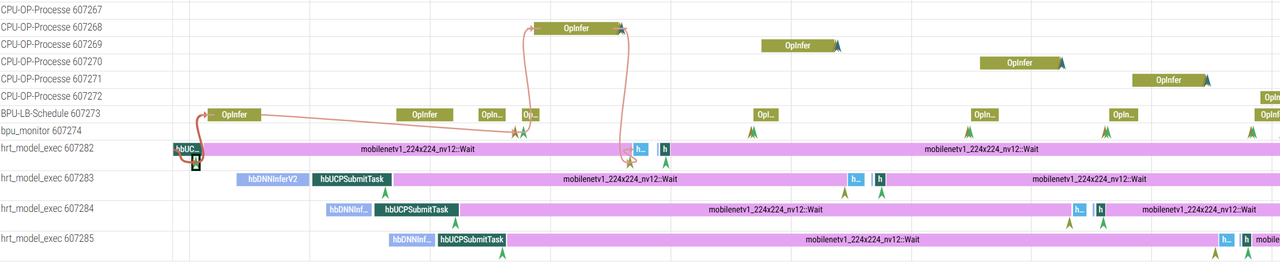
6.2 system模式
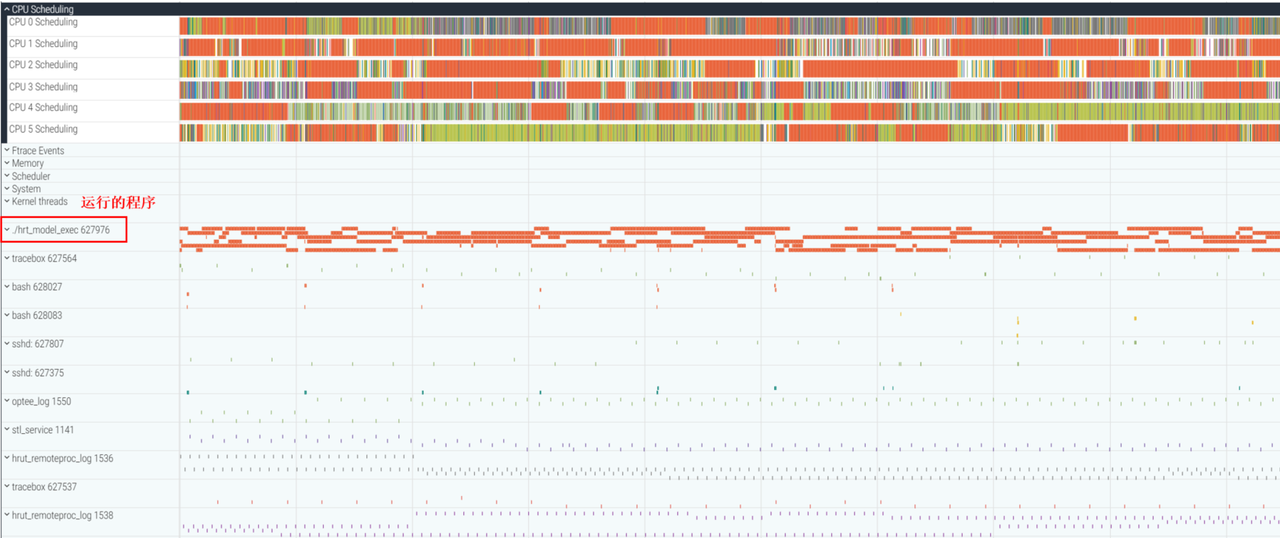
在system模式下,UCP trace只是其中一个数据源,因此需要运行Perfetto的后台进程来完成trace捕获。
运行Perfetto后台进程
请注意,为了能够获取完整的数据,需要确保hrt_model_exec执行结束前,perfetto进程未退出。可以适当增加ucp_system.cfg中的duration_ms,当前默认为10000ms
开启一个新终端,设置环境变量和运行程序
- 运行程序,比如运行hrt_model_exec命令,并将获取到的ucp.pftrace解析:
7. 视觉处理/高性能算子
UCP提供了视觉处理和高性能算子两大方向的多种接口:
视觉处理主要针对视频编/解码,光流,AVM拼接等常规视觉算法
- 高性能算子依赖于DSP的实现,主要用于fft和ifft的加速
更多信息可以参考用户手册《统一计算平台》的相关章节。
8. DSP使用
当前DSP可以用于加速模型前后处理比如点云体素化,模型量化反量化等操作,模型中间的算子加速暂不支持。更详细的说明,请参照《DSP算子开发》章节。
完整的算子开发分为三个步骤:
DSP算子开发
注册算子,编译镜像
通过UCP API调用,申请计算资源并执行任务
9. UCP环境变量详解
9.1 环境变量配置说明
UCP中的环境变量分为下表中的几大类:
名称 | 环境变量名称 | 功能 |
|---|---|---|
日志等级配置 | HB_XXX_LOG_LEVEL | 设置ucp日志等级,XXX为对应模块 |
后端硬件配置 | HB_UCP_ENABLE_XXX_BACKEND_CORE_NUM | 设置启用后端硬件的数量,XXX为对应硬件 |
HB_NN_ENABLE_MEM_LRU_CACHE | 设置模型推理是否使用LRU缓存 | |
HB_DNN_USER_DEFINED_L2M_SIZES | 设置开启L2缓存时每个bpu核心L2M的大小 | |
线程管理配置 | HB_UCP_SCHEDULE_PRIORITY | 设置ucp调度任务的优先级 |
HB_UCP_CPU_PROCESS_THREAD_PRIORITY | 设置模型中cpu算子处理的优先级 | |
任务管理配置 | HB_UCP_MAX_TASK_NUM | 设置VP、HPL、NN各模块允许启用最大任务数量 |
仿真平台配置 | HB_UCP_SIM_PLATFORM_TYPE | 设置在x86上推理HBM文件的目标平台 |
9.2 环境变量配置说明
9.2.1 UCP模块日志配置

- HB_UCP_LOG_LEVEL:用于设置ucp模块的日志级别
- HB_VP_LOG_LEVEL:用于设置vp模块视觉处理的日志级别
- HB_HPL_LOG_LEVEL:用于设置HPL高性能算子模块的日志级别
- HB_NN_LOG_LEVEL:用于设置NN模型推理模块的日志级别
- HB_UCP_LOG_PATH:设置日志存储路径,支持滚动切分
- HB_UCP_LOG_MAX_SIZE:滚动切分时文件大小,单位MB,默认为1024
- HB_UCP_LOG_ROTATE_NUM:滚动切分时的文件数量,默认为16
9.2.1 UCP模块日志配置
- HB_DSP_ENABLE_CONFIG_VDSP:配置DSP侧日志及日志写入ARM侧显示,默认为false,这个变量会决定HB_DSP_WRITE_VDSP_LOG_TO_ARM和HB_DSP_VDSP_LOG_LEVEL是否会被下发到dsp侧
- HB_DSP_WRITE_VDSP_LOG_TO_ARM:设置DSP侧日志ARM侧显示,默认为false,配置为true后,arm侧能够通过日志查看到dsp的运行日志
- HB_DSP_LOG_LEVEL:UCP的dsp模块arm侧日志等级,一共7个等级,分别对应Verbose、Debug、Info、Warning、Error、Critical、Never,默认为Warning等级3
- HB_DSP_VDSP_LOG_LEVEL:UCP的dsp模块dsp侧日志等级,一共5个等级,分别对应为Debug、Info、Warning、Error、Always等级,默认为Warning等级3
dsp侧日志输出配置示例:
9.3 UCP模块日志配置
9.3.1 后端硬件启用配置
在程序运行的时候,默认会启动所有的后端,对于那些对资源要求比较严格的情况,每启动一个器件的线程,就代表浪费了一部分资源,因此,我们可以利用如下环境变量,对不使用的器件进行关闭:
- HB_UCP_ALL_BACKENDS_DEFAULT_DISABLE:禁用所有后端,值非0则禁用,默认值为0,表示打开所有后端
- HB_UCP_ENABLE_GDC_BACKEND_CORE_NUM:设置GDC可支持的核数,默认当前计算平台可支持的最大核数(B/E/M上为1个,P上为2个),0表示关闭GDC
- HB_UCP_ENABLE_STITCH_BACKEND_CORE_NUM:设置STITCH可支持的核数 , 默认当前计算平台可支持的最大核数(E/M/P上均为1个),0表示关闭STITCH
- HB_UCP_ENABLE_JPU_BACKEND_CORE_NUM:设置JPU可支持的核数,默认当前计算平台可支持的最大核数(E/M上为1个,P上为3个),0表示关闭JPU
- HB_UCP_ENABLE_VPU_BACKEND_CORE_NUM:设置VPU(Video Process Unit,非BPU中的VPU)可支持的核数,默认当前计算平台可支持的最大核数B/E/M上为1个,P上为3个,0表示关闭VPU
- HB_UCP_ENABLE_DSP_BACKEND_CORE_NUM:设置DSP可支持的核数,默认当前计算平台可支持的最大核数(B/E/M上为1个,P上为2个),0表示关闭DSP
- HB_UCP_ENABLE_BPU_BACKEND_CORE_NUM:设置BPU可支持的核数,默认当前计算平台可支持的最大核数(B/E/M上为1个,P上为4个),0表示关闭BPU
- HB_UCP_ENABLE_PYM_BACKEND_CORE_NUM:设置PYM可支持的核数,默认当前计算平台可支持的最大核数(B上为2个,E/M上为3个,P上为5个),0表示关闭PYM
- HB_UCP_ENABLE_ISP_BACKEND_CORE_NUM:设置ISP可支持的核数,默认当前计算平台可支持的最大核数(B/E/M上为1个,P上为4个),0表示关闭ISP
- HB_UCP_ENABLE_CPU_BACKEND_CORE_NUM:设置CPU推理算子的线程数,默认线程数为6,0表示关闭
下面以J6M为例,进行简单说明:
在不屏蔽禁用任何后端的情况下,启动程序后,在运行到第一个ucp接口后,可以看到所有线程默认都会启动:
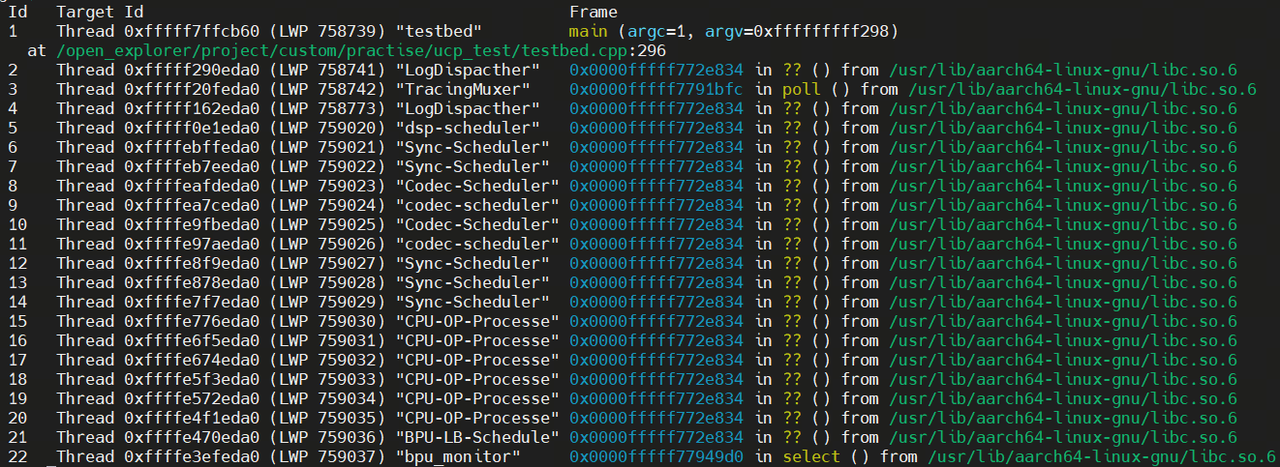
在开启HB_UCP_ALL_BACKENDS_DEFAULT_DISABLE环境变量后,如果依赖的对应器件没有开启,运行到对应位置就会报错:

仅开启1个BPU(设置),可以看到多了2个bpu的线程:

如果在推理模型中有cpu算子,可以使用HB_UCP_ENABLE_CPU_BACKEND_CORE_NUM来进行控制,下图为使用1个bpu+1个cpu线程来运行模型:

9.3.2 BPU推理环境变量配置
在模型推理过程中,可以配置一些环境变量,用于优化模型推理效率:
- HB_NN_ENABLE_MEM_LRU_CACHE:设置NN模块是否使用内存LRU缓存,true为使用,默认不使用
- HB_NN_MEM_LRU_CACHE_CLEAN_INTERVAL:设置NN模块清理LRU缓存的时间间隔,单位为毫秒,默认为1000ms
上述两个变量的原理和具体使用方法请参考LRU章节。
- HB_DNN_USER_DEFINED_L2M_SIZES:用于设置每个BPU核心的L2 Memory大小,让模型推理时使用片上L2 Cache作为临时存储,减少DDR访问带宽,提升推理性能,配置格式如下:
- 各core Size以:分隔,单位为MB,仅支持整数
core数量与平台的BPU数量相对应,P为4个,H为3个
- corexsize为0时,表示该bpu不配置L2M
模型需要编译时启用L2M才能在运行时利用L2 Cache。编译参数max_l2m_size用于控制模型可用的L2大小:
或者PTQ链路的yaml中进行配置:
设置的L2M内存大小不能超过板端最大可用L2M大小,其可以通过下面的命令来进行查看:
不配置时,默认每个BPU核值均为0。
该变量仅在J6H/P上生效,且启用后不支持优先级抢占推理。
9.4 线程管理设置
线程管理主要用于ucp调度以及模型推理时cpu算子处理的优先级设置:
- HB_UCP_SCHEDULE_PRIORITY:用于设置UCP线程实时调度优先级,取值范围为0~99,默认为1,设置数值越高,调度的优先级就越高,当优先级设置为0时,线程调度方式会退化为SCHED_OTHER,当优先级设置大于0时,线程的调度方式为SCHED_FIFO(其管理的线程主要有:BPU-LB-Scheduler(bpu任务下发),Codec-Scheduler(编码器后端比如JPU,VPU),Sync-Scheduler(DSP,GDC,PYM等后端)
当设置这个环境变量后,其会设置pthread库中pthread_setschedparam的优先级,pthread_setschedparam接口参数为:
thread:创建的线程
policy:调度策略(SCHIED_OTHER,SCHIED_FIFO,SCHIED_RR)
param:用于设置优先级,即HB_UCP_SCHEDULE_PRIORITY需要设置的值(创建线程时,默认优先级为0)
以BPU模型推理为例:在调用hbDNNInitializeFromFiles后,每个BPU会创建一个BPU-LB-Scheduler线程,其会根据设置的HB_UCP_SCHEDULE_PRIORITY来设置在BPU负载监控线程在系统OS层面的实时调度优先级,它影响的是BPU-LB-Scheduler线程多快能响应消息并做出调度决策,不会影响BPU实际的推理耗时。在多BPU的平台上,如果配置的后端为HB_UCP_BPU_CORE_ANY提交任务时,该线程会根据各核负载情况,决定将任务分配到哪个BPU核上执行。
- HB_UCP_CPU_PROCESS_THREAD_PRIORITY:设置模型推理的cpu算子处理线程优先级,取值范围为0~99,默认为0,设置数值越高,计算的优先级也就越高。当优先级设置大于0时,线程的调度方式为SCHED_RR(时间片轮转)

9.5 任务管理设置
任务管理环境变量主要用于VP、HPL、NN各自模块允许同时存在的最多任务数量,默认为32,可以通过下面的变量来进行配置:
HB_UCP_MAX_TASK_NUM
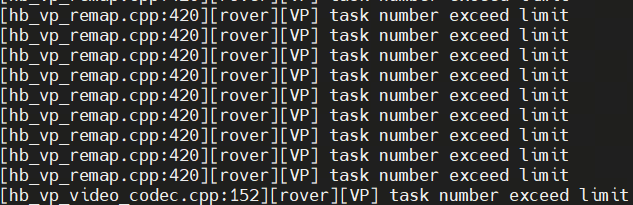
这个时候可以通过配置HB_UCP_MAX_TASK_NUM来提升任务数量以满足要求。
9.6 任务管理设置

可以通过下面的变量进行设置:
- HB_UCP_SIM_PLATFORM_TYPE:支持如下几个参数: nash-e, nash-m, nash-p, nash-b,nash-h
在pc中可以写入bashrc中 :
10. 中继模式
10.1 中继模式介绍
UCP框架支持两种主要工作模式:直连模式、中继模式。系统默认运行在直连模式下。中继模式是为了方便多进程任务的统一调度而开发的功能,是一种典型的Service/Client模式。通过ucp_service中继服务来进行进程间的任务分发和调度,支持多进程任务的统一调度。
10.2 中继模式使用
使用中继模式,只需要在运行程序前启动service,其他直连模式一致用法一致。用法如下:
- 首先要启动ucp_service,service文件位于oe包的samples/ucp_tutorial/deps_aarch64/ucp/bin/service路径下,并通过设置环境变量HB_UCP_ENABLE_RELAY_MODE=true来启用中继模式
运行程序
- 在任务完成后,使用命令pgrep ucp_service /dev/null killall ucp_service关闭ucp_service

10.3 注意事项
x86仿真平台不支持中继模式,即使设置中继也会被回退到直连模式
由于中继模式需要进行进程间通信和内存共享,会导致整体的 CPU 负载更高
模型任务底层资源的竞争都发生于 Service 进程内,相较于直连模式,多个独立进程的竞争强度更高,任务的耗时可能受到影响
ucp_service非正确退出时,会有残留的消息队列文件,需要手动清理(文件为/dev/mqueue/ucp\relay_s.pid和/var/run/ucp_relay_s.lock),否则会影响下次的使用

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)