
前言
SmoothQuant技术出现的背景
当我们把大语言模型(LLM)的参数数量增加到 67 亿个以上时,激活过程中会出现幅度很大的异常值,而且这些异常值是有规律的。这会让量化误差变大,降低模型的精度。ZeroQuant 采用了动态逐符元激活量化和分组权重量化的方法。这种方法能有效实施,在 GPT - 3 - 350M 和 GPT - J - 6B 模型上可以保证较好的精度。但对于有 1750 亿个参数的大型 OPT 模型,它没办法保证精度。LLM.int8()通过引入混合精度分解来解决精度问题(就是把异常值用 FP16 格式处理,其他激活用 INT8 格式)。不过,这种分解方法很难在硬件加速器上高效率地实现。所以,现在还没有解决的一个问题是,为大语言模型找到一种“高效”“对硬件友好”,最好还“不用训练”的量化方案,让所有计算密集型操作都能用 INT8 格式。
SmoothQuant技术原理
SmoothQuant是一种针对大语言模型的准确又高效的训练后量化(PTQ)解决方案,在不需重新训练的情况下,通过平衡权重和激活的尺度,将激活中难量化的“尖峰值”平滑掉,从而安全地量化激活。SmoothQuant基于一个重要发现:激活比权重更难量化,原因是存在异常值,但不同token在通道间的变化情况是相似的。基于这个观察结果,SmoothQuant在离线状态下把量化难度从激活转移到了权重。
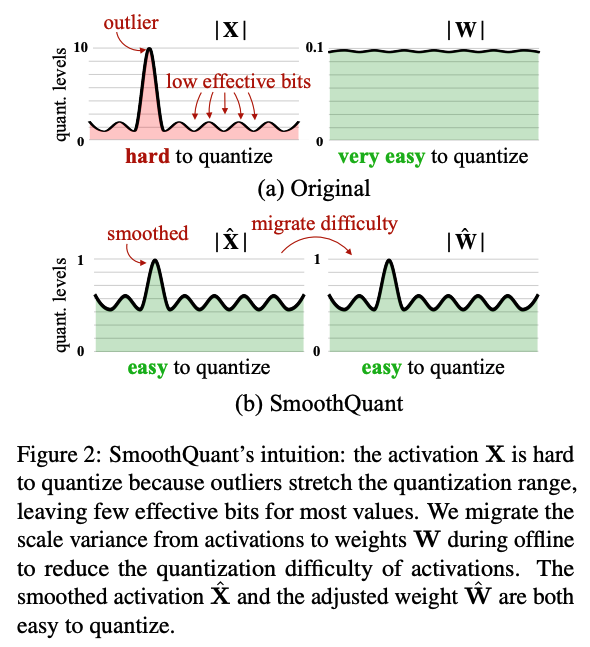
图a:在原始情况下,激活值(X)存在离群点(outlier),这些异常值会拉伸量化范围,导致大部分数值只有低有效位(low effective bits),从而难以准确量化。相比之下,权重(W)的分布较为平稳,量化容易。
(图b):SmoothQuant通过离线操作,将激活值的scale变化迁移到权重上。具体来说,它对激活值进行平滑处理,使量化变得容易;同时调整权重,也保持易于量化的状态。这相当于将量化难度从激活值转移到了权重上。
SmoothQuant通过除以逐通道平滑因子 𝐬来“平滑”激活输入。 为了保持线性层的数学等价性,相应地在weight上乘以缩放权重:
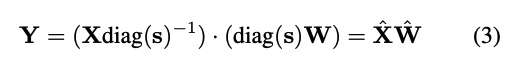
考虑到输入 𝐗 通常是由先前的线性操作(例如 、线性层、层归一化等 )产生的,可以轻松地将平滑因子融合到先前层的参数中 离线,这不会因额外的缩放而产生内核调用开销。 对于其他一些情况,当输入来自残差输入时,可以在残差分支中添加额外的缩放。
将量化难度从激活迁移到权重
SmoothQuant的目标是找到per-channel平滑因子s,使得
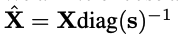
更容易量化,同时增加所有通道的有效量化位数。
论文引入一个超参数$$\alpha$$来控制用于控制从激活迁移到权重的难度,公式如下:
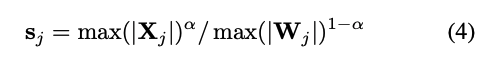
对于大多数模型,例如,所有 OPT 和 BLOOM 模型,α=0.5 是一个均衡点,可以均匀地分配量化难度,尤其是在我们对权重和激活使用相同的量化器(例如,per-tensor,静态量化)时。 该公式确保对应通道的权重和激活具有相似的最大值,从而共享相同的量化难度。

上图说明了当取 α=0.5 时平滑变换的情况。平滑因子 s 是在校准样本上获得的,整个转换是在线完成的。在运行时,激活在没有缩放的情况下是平滑的。对于一些其他模型,其中激活异常值更为显著具有 ∼30% 的异常值,这些异常值对于激活量化更难),我们可以选择一个更大的 α 来将更多量化难度迁移到权重(如 0.75)。
应用SmoothQuant在 Transformer blocks
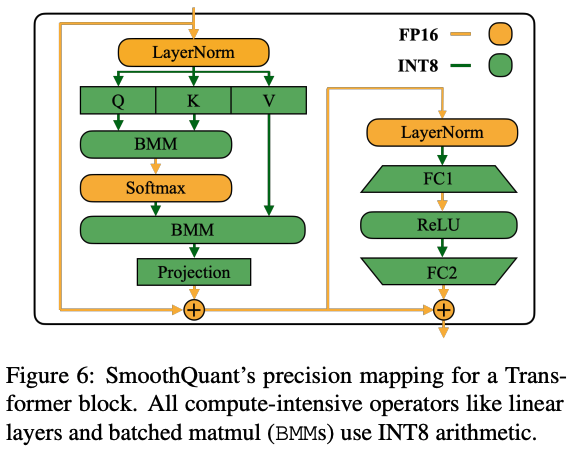
SmoothQuant使用示例
LLaMA 2 7B
官方代码库:https://github.com/mit-han-lab/smoothquant/blob/main/examples/smoothquant_llama_demo.ipyn中提供了 Llama-2-7B 模型示例,证明了SmoothQuant 可以对权重和激活值都采用 8 位精度,从而达到与 FP16 模型相近的困惑度。
环境与依赖
构建一个模型评估器 Evaluator
核心逻辑:
取 WikiText-2 测试集的前 40 条样本。
- 用 tokenizer 拼接成一长串文本 → 编码为 input_ids。
- 在 evaluate() 方法中:
将输入分成 2048 tokens 一段;
- 模型前向计算得到 lm_logits;
计算 cross-entropy 损失;
计算 PPL(Perplexity) = exp(平均 NLL)。
Perplexity 含义:
衡量语言模型预测下一个词的平均不确定度。 值越低,模型性能越好。 (PPL 越接近原 FP16 模型,量化效果越好。)
加载数据集与 Tokenizer
评估原始 FP16 模型的性能
Naive 量化 (没有 SmoothQuant)
- 使用 quantize_llama_like 对模型直接进行 权重+激活 INT8 量化。
没有平滑 (smooth),即直接硬量化。
SmoothQuant 平滑 + 量化
核心步骤解释:
- 重新加载原始模型(保证干净未改动的权重)。
- 加载激活统计数据 act_scales
这是在校准阶段提前收集的每层激活的最大值/尺度信息。
执行平滑:
这一步调整权重和激活的尺度,
- 参数 0.85 即 α,用来控制权重与激活的平衡。
- 再次量化为 W8A8。
- 重新计算 PPL。
在 Hugging Face Optimum 上使用 SmoothQuant
安装依赖
示例代码
优点
无需重新训练(PTQ)
支持 FP16 → INT8 自动转换
- 与 transformers 无缝集成,可直接推理或导出到 ONNX / OpenVINO / IPEX
在 vLLM 上使用 SmoothQuant
安装依赖
示例代码
优点
- 完整支持 W8A8 推理
与 vLLM 的高吞吐引擎集成良好
校准样本仅需少量文本
速度提升 1.5–2×,显存节省约 40–50%
参考资料
https://github.com/mit-han-lab/smoothquant
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
SmoothQuant+: Accurate and Efficient 4-bit Post-Training WeightQuantization for LLM
https://www.zhihu.com/question/576376372/answer/3388402085

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)