
整个部署流程涉及到网络结构的数据流包括:float train训练、float eval推理、calib、qat训练、qat eval推理、导出部署、qat eval回灌推理,建议使用一套forward,不要存在多forward的情况(特别是prepare时 算子替换的hook注册在forward上,换成xxx_forward_xxx不保证能成功)。否则,即使每个流程都跑通了,也容易有各种forward不对齐的问题。常见的训练与部署链路不一致情况:
train时forward中多了loss,eval+导出部署时不需要loss
train时forward中多了前后处理,建议快速挪到forward外面去
train时forward中多了辅助分支,eval+导出部署时不需要辅助分支
train时forward中某结构for运行n遍(时序),eval+导出部署时该结构只运行一遍
train时forwad中多loss/前处理
- 在模型输入前插入 QuantStub。
- 在模型输出后插入 DequantStub。
- PyTorch 的 nn.Module 有一个布尔属性 self.training
- 在调用 model.train() 后为 True(训练模式)。
- 在调用 model.eval() 后为 False(推理模式)。
- assert target is not None:训练时必须有标签 target。
- x = self.dequant(x):前面模型的 量化输出,进loss前需要先 dequant,把量化的输出转成浮点。
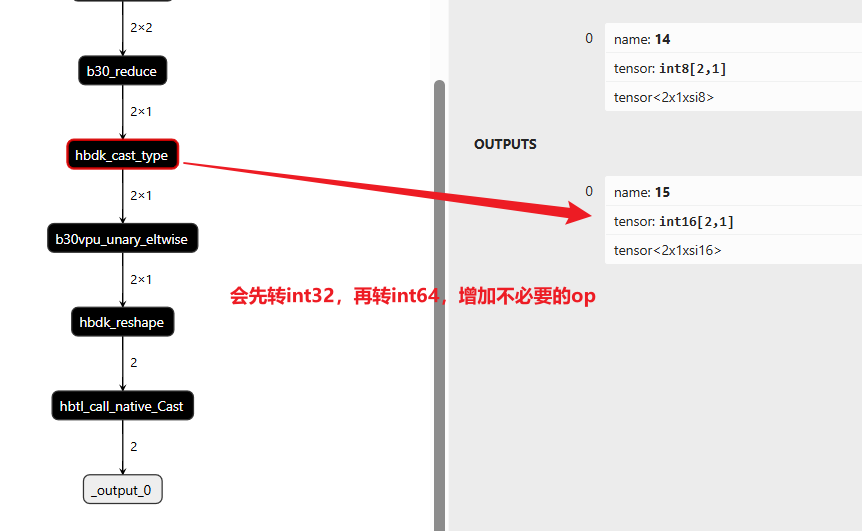
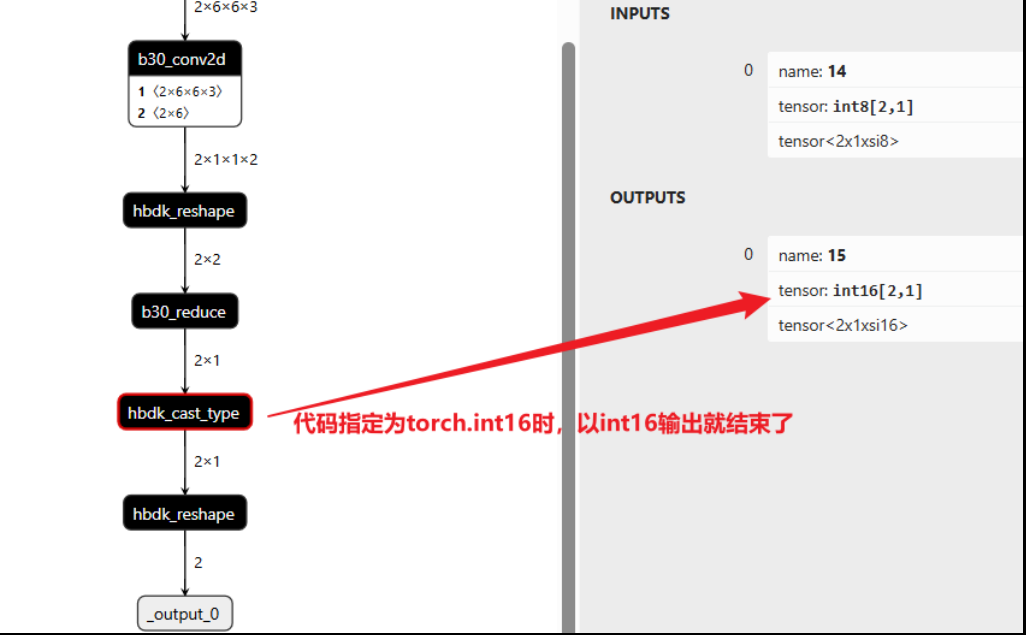
else: return torch.argmax(x, dim=1).to(torch.int16)
推理阶段不需要计算损失,而是返回预测类别。
- torch.argmax(x, dim=1) 取出概率最大的位置(类别 ID),默认为int64输出
train时forward中多辅助分支
train时forward中多了辅助分支,eval+导出部署时不需要辅助分支。针对这种情况,需要注意:
仅对部署上板的部分 插入伪量化节点,辅助分支采用float进行qat训练。
QAT 训练为全局训练,若辅助分支量化,会导致训练难度增加,若辅助分支处的数据分布与其他分支差异较大还会加大精度风险。
辅助分支处quant/dequant的处理需要注意,示例如下:
train时forward中for 某结构 n遍(时序)
当train与eval存在某些结构运行次数不一样时,可能会遇到图不一致的问题。
先介绍几种常见错误写法
在进行qat训练时报错
修改如下:
此时依旧报错:
relu的generated_modules次数发生变化,考虑是relu的写法问题,修改为:
最终版本:
报错如下:可以看到是在qat推理时,在add地方又报类似图不一致的错了。
参考如上修改即可不再报错。
常见替换为FloatFunctional的方式如下
'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)