
原论文信息如下:
From Forecasting to Planning: Policy World Model for Collaborative State-Action Prediction 发表日期:
2025年10月 作者:
Zhida Zhao, Talas Fu, Yifan Wang, Lijun Wang, Huchuan Lu 发表单位:
大连理工大学 原文链接:
https://arxiv.org/pdf/2510.19654 开源代码链接:
https://github.com/6550Zhao/Policy-World-Model
想象一下,当你开车时,是不是会下意识地"脑补"前方可能出现的各种情况?比如突然窜出的行人、前方车辆的急刹,或是路口突然出现的障碍物?这种"预判未来"的能力,是人类驾驶员安全驾驶的关键。
那么问题来了:AI能否学会这种"脑补"未来的能力,从而做出更安全的驾驶决策呢?
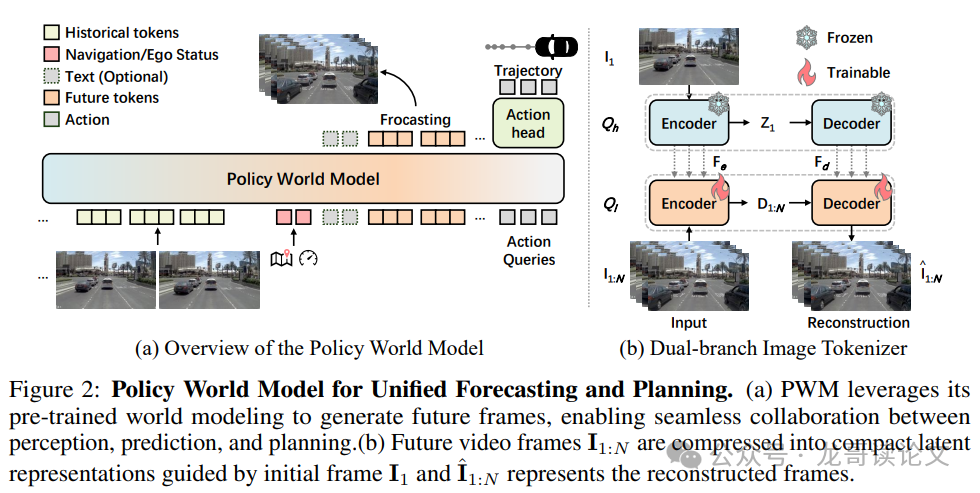
图1:Policy World Model整体架构图,展示了从预测到规划的完整流程
重新定义自动驾驶:从预测到规划的协同状态-动作预测
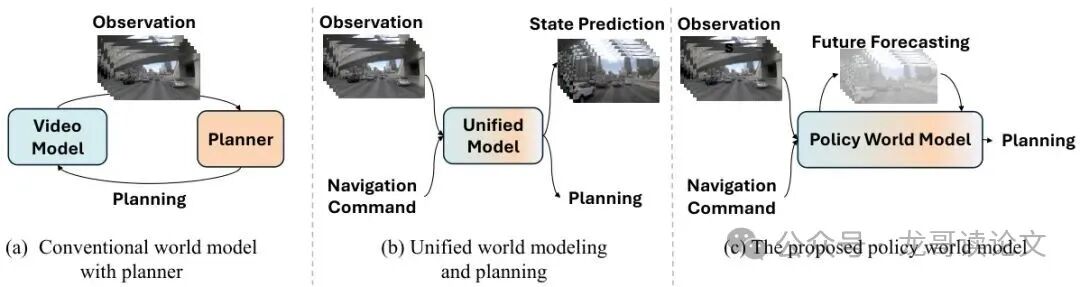
图2:自动驾驶视频世界模型对比 (a)传统视频世界模型作为像素空间的数据引擎 (b)统一世界模型将视频生成和规划作为独立任务 (c)本文提出的策略世界模型基于学习的世界知识进行规划
这种机制完美模拟了人类驾驶员的"预期感知"能力——我们在做出驾驶决策前,会先在脑海中想象各种可能的未来情景,然后选择最安全的行动方案。

Policy World Model的核心创新:统一世界建模与轨迹规划
PWM的核心架构设计体现了真正的端到端思维。让我们来深入解析这个创新模型的几个关键设计:
无动作视频生成预训练
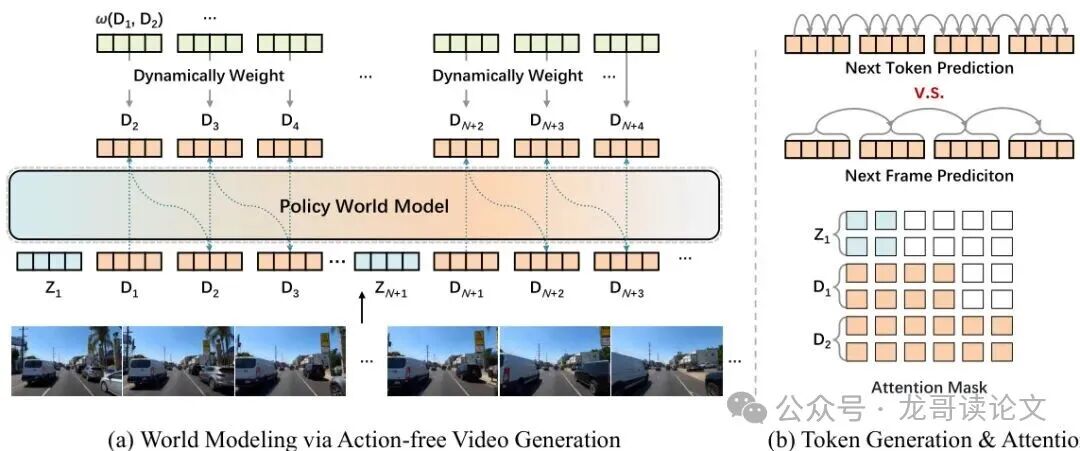
图3:视频世界建模流程 (a)世界建模在无动作、高压缩视频数据上使用动态增强的并行预测进行 (b)token预测格式和注意力交互的比较
上下文引导的图像分词器
为了实现高效的视频预测,PWM采用了一个巧妙的双分支图像分词器设计:
这种设计在生成质量和计算效率之间找到了完美的平衡点——既保证了视觉连贯性,又实现了快速的并行帧生成。
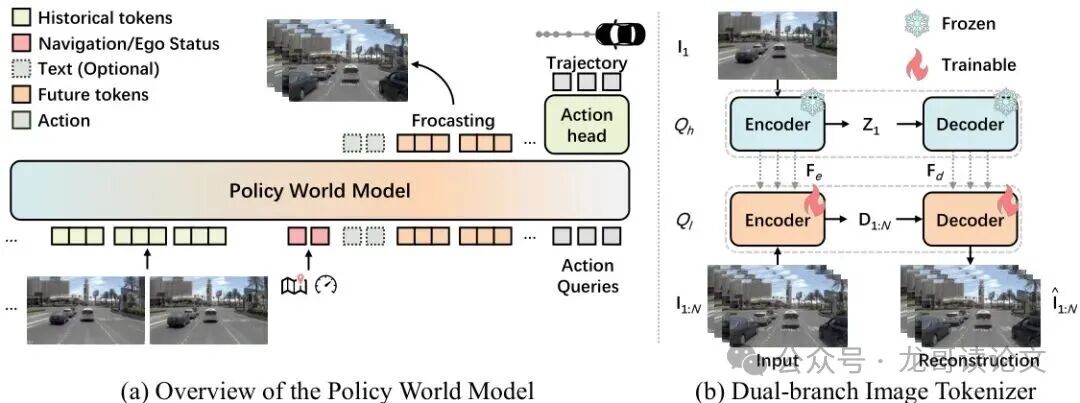
图4:统一预测和规划的Policy World Model (a)PWM利用其预训练的世界建模能力生成未来帧,实现感知、预测和规划的无缝协作 (b)未来视频帧在初始帧引导下压缩为紧凑的潜在表示
端到端的多模态推理
在推理阶段,PWM展现出了真正的多模态协同能力。给定当前和历史观测,模型会:
首先生成文本描述来理解当前环境,然后基于学习的世界知识推演合理的未来状态,最后结合生成的描述和预测的未来状态,输出最优的驾驶动作。
整个过程通过端到端的自回归Transformer实现,确保了感知、预测和规划之间的无缝协作。

动态焦点损失:提升视频预测质量的关键技术

图5:动态焦点损失效果对比可视化。第一行显示真实帧,第二行显示无DFL的预测,第三行显示有DFL的预测
从可视化结果可以明显看出,使用DFL后模型能够更好地捕捉和表示随时间变化的动态场景元素,产生更准确和时间一致的预测。
这种技术不仅提升了视频预测的质量,更重要的是为下游的规划任务提供了更可靠的未来状态信息,从而实现了真正意义上的协同状态-动作预测。

实验结果:仅用单目相机超越多视角、多模态方法
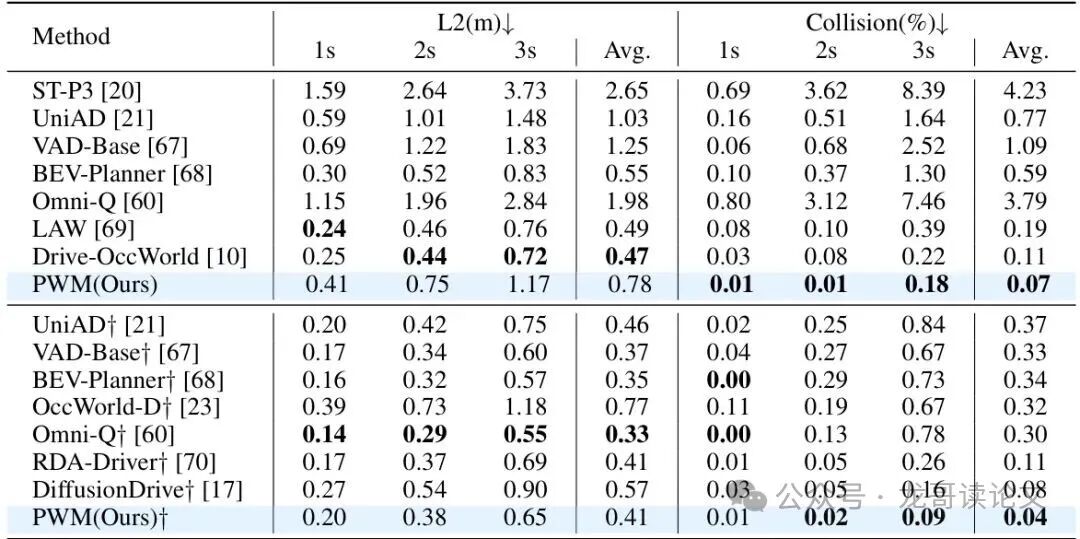
表1:nuScenes验证集比较。指标按照与[67]相同的协议计算。为公平比较,结果分别报告了无自车状态和有自车状态(标记为"†")的设置;UniAD和VAD的结果从BEV-Planner[68]复现。最佳结果加粗显示。
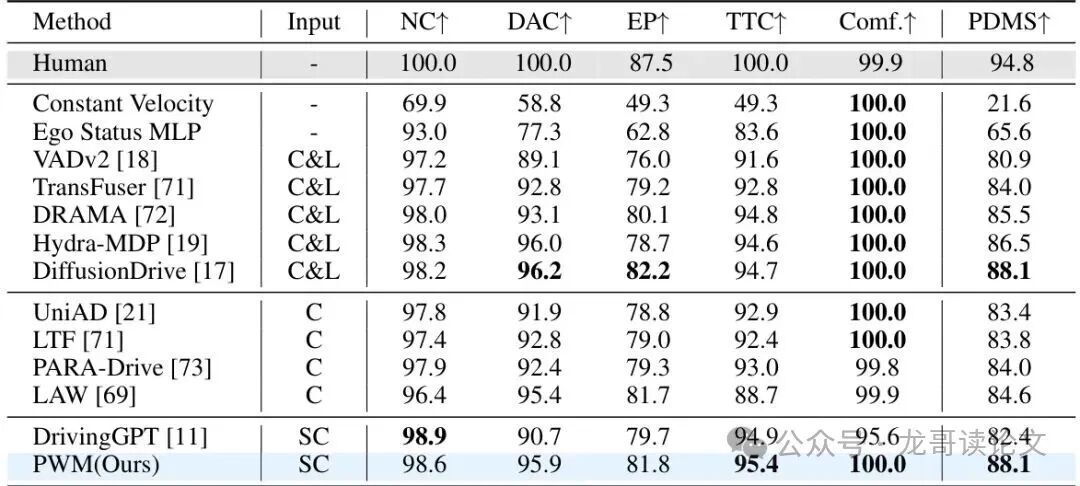
表2:NAVSIM NavTest分割比较。总体预测驾驶员模型分数(PDMS)和反映闭环性能的子分数。C:多视角相机;SC:单视角相机;C&L:多视角相机+激光雷达;"-":无视觉输入。最佳结果加粗显示。

这些结果不仅增强了自动驾驶的安全性,还凸显了从基于视频的环境表示中学习的潜力。想象一下,仅用一个普通摄像头就能达到多传感器融合系统的性能,这为降低自动驾驶系统成本开辟了全新可能!
消融研究揭示关键设计价值
为了深入理解PWM各个组件的作用,研究团队进行了系统的消融实验。结果清晰地展示了无动作视频世界知识和动态焦点损失对模型性能的关键影响。
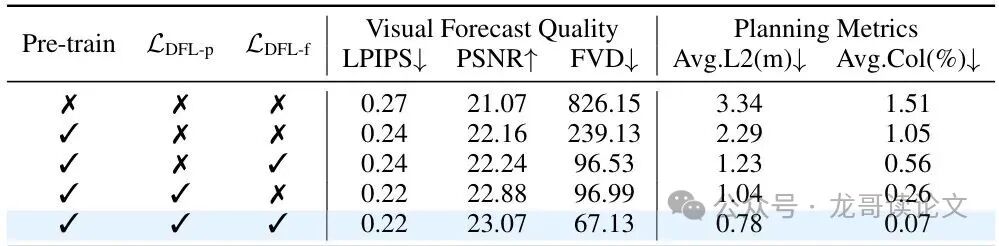
表3:世界建模和动态焦点损失对nuScenes和NAVSIM的影响。"Pretrain"表示在Open-Youtube视频上训练。"Fine-tune"表示在下游基准上训练。"·ℒDFL-p"和"·ℒDFL-f"分别表示动态焦点损失是否用于预训练和微调。报告了视频指标和规划分数。
在没有预训练的情况下,模型难以捕捉和预测动态场景变化,产生了最差的预测和规划指标。而在无动作视频生成上进行预训练后,模型显著提高了预测未来帧的能力,并在规划任务中获得了实质性提升。
动态焦点损失的应用带来了更加明显的改进。与在两个阶段都忽略动态权重相比,在预训练或微调中应用它都能在三个生成指标以及规划指标上带来明显提升。值得注意的是,仅在预训练阶段使用它在LPIPS和PSNR上取得了比仅微调更强的结果,表明从大规模视频中获得了更有效的时空建模能力。

表4:nuScenes和NAVSIM基准上的视觉预测消融研究
预测10个未来帧在两个数据集上都实现了最佳性能。研究团队推测,较短的时间范围捕捉不到足够的时序动态,导致规划能力较弱。相反,较长的时间范围会降低预测质量,并可能引入幻觉,特别是在单目前视相机感知有限的情况下,最终损害决策能力。
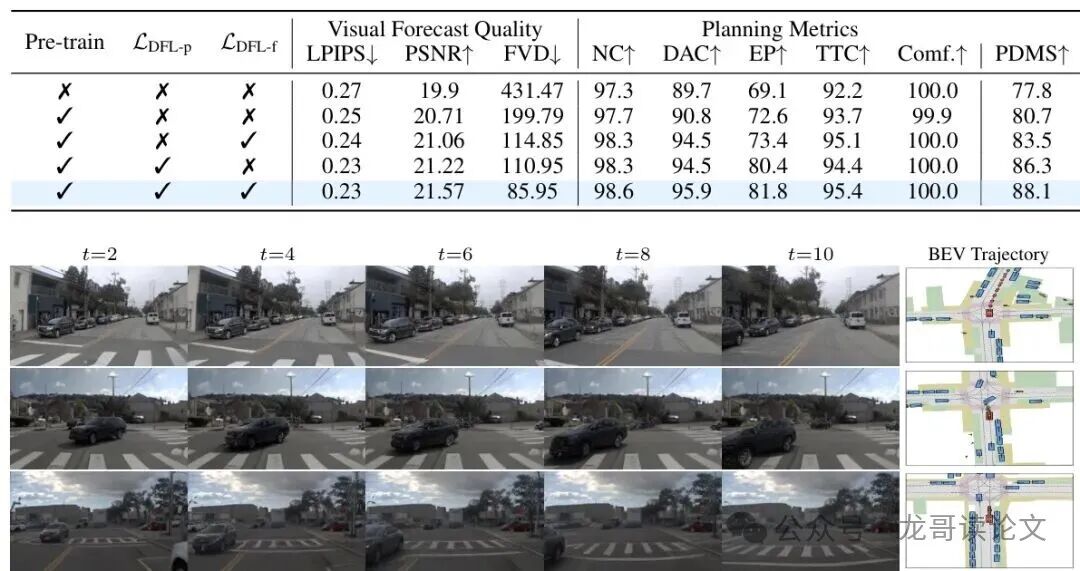
图4:NVASIM上的解码未来帧预测和对应BEV轨迹可视化(绿色:真实值,橙色:预测)
从可视化结果可以清楚地看到解码的未来帧预测与规划轨迹之间的明确对齐关系。这种视觉一致性证明了PWM能够生成合理的未来状态,并基于这些状态做出可靠的规划决策。
在nuScenes基准上,引入未来帧预测带来了平均碰撞率的大幅降低。在更具挑战性的NAVSIM数据集上,观察到了一个互补的权衡:当模型在训练中不预测未来帧时,它实现了更高的EP分数,表明其规划的轨迹在分配的时间范围内沿着路线前进得更远。相比之下,当模型在微调期间预测未来帧时,它获得了更高的NC和TTC分数,展示了更有效地避免潜在碰撞的能力,以及更高的DAC分数,显示其轨迹更好地保持在可行驶区域内。
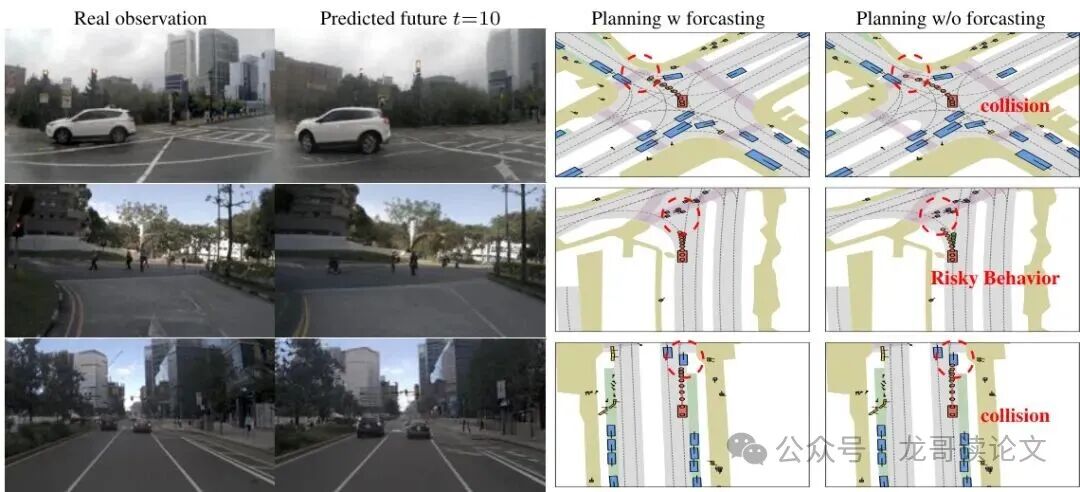
图5:训练中是否包含未来预测的规划结果比较(绿色:真实值,橙色:预测)
从这些发现中,可以推断未来帧预测可以诱导出更保守的规划策略,牺牲一些进度(EP)以确保更高的安全边际(NC和TTC)。因此,模型倾向于选择风险较低的路线,而不是最大化前进进度。

这种安全优先的规划策略在实际自动驾驶应用中具有重要价值。毕竟,对乘客和行人来说,安全到达比快速到达更重要!
未来展望:更安全、更高效的自动驾驶系统
Policy World Model的成功不仅仅体现在当前的实验结果上,更重要的是它为自动驾驶领域指明了新的发展方向。通过将世界建模和轨迹规划真正统一起来,并利用学习的世界知识来增强规划效果,PWM为构建更安全、更高效的自动驾驶系统提供了全新思路。
当前局限与改进方向
尽管基于视频的PWM表现出了强大的性能,但仅依赖单视角输入会在能见度条件差的情况下影响其鲁棒性。此外,其较短的规划视野限制了其在长视野场景中的适用性。
想象一下,未来的自动驾驶系统不仅能够预演视觉未来,还能用自然语言描述其推理过程:"我预见到前方车辆可能突然变道,因此决定稍微减速以保持安全距离。"这种透明化的决策过程将大大增强用户对自动驾驶技术的信任。
随着计算能力的持续提升和视频数据的不断积累,基于世界模型的决策系统有望在更多复杂场景中展现其价值。从城市道路到高速公路,从简单天气到恶劣条件,PWM的方法论为实现全天候、全场景的自动驾驶提供了有希望的技术路径。
龙迷三问
下面是龙哥对于大家可能的一些问题的解答:
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~
思路启发
文章转载自公众号:龙哥读论文
作者:龙行智械
原文链接:https://mp.weixin.qq.com/s/_a9PgHIoZKNHGKrMuAcRjQ

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)