
前言
随着深度学习的快速发展,Transformer算法在各类AI任务中都得到了广泛关注。然而,Transformer的部署面临计算量大、延迟高等挑战,地平线计算芯片能够支撑Transformer算法的高效推理,可以成为用户在边缘平台部署Transformer算法的优先选择。本文将对Transformer性能优化方法做出详细说明。
性能优化策略
尽管地平线计算芯片和配套的算法工具链具备高效部署Transformer算法的能力,但由于Transformer结构的复杂性和特殊性,直接部署公版模型有时会不可避免地会遇到性能瓶颈,导致端侧推理速度较慢。这里介绍几种部署Transformer算法时常见的性能问题并提供优化策略。所有算子的耗时分析均基于模型编译时生成的html性能预估文件进行。
优化Softmax维度
以DETR算法为例,公版算法17个Softmax的总耗时约为58ms,优化算法17个Softmax总耗时约为42ms,有16ms的优化。
这些差异主要体现在SelfAttention部分,公版算法是对1x8x1050x1的Shape做Softmax,而优化算法是对8x25x42x1的Shape做Softmax。这个调整没有改变计算量,但是重排了Softmax的计算维度与批次结构,从而提高了并行度与缓存命中率。多个小Softmax(42维)比单个大Softmax(1050维)更容易并行化,并能让访存更加连续,减少访存延迟。多个Softmax同时分配到不同计算单元,使BPU计算资源被更高效地利用,从而有效降低计算耗时。
公版算法Softmax(1x8x1050x1)的静态耗时预估:
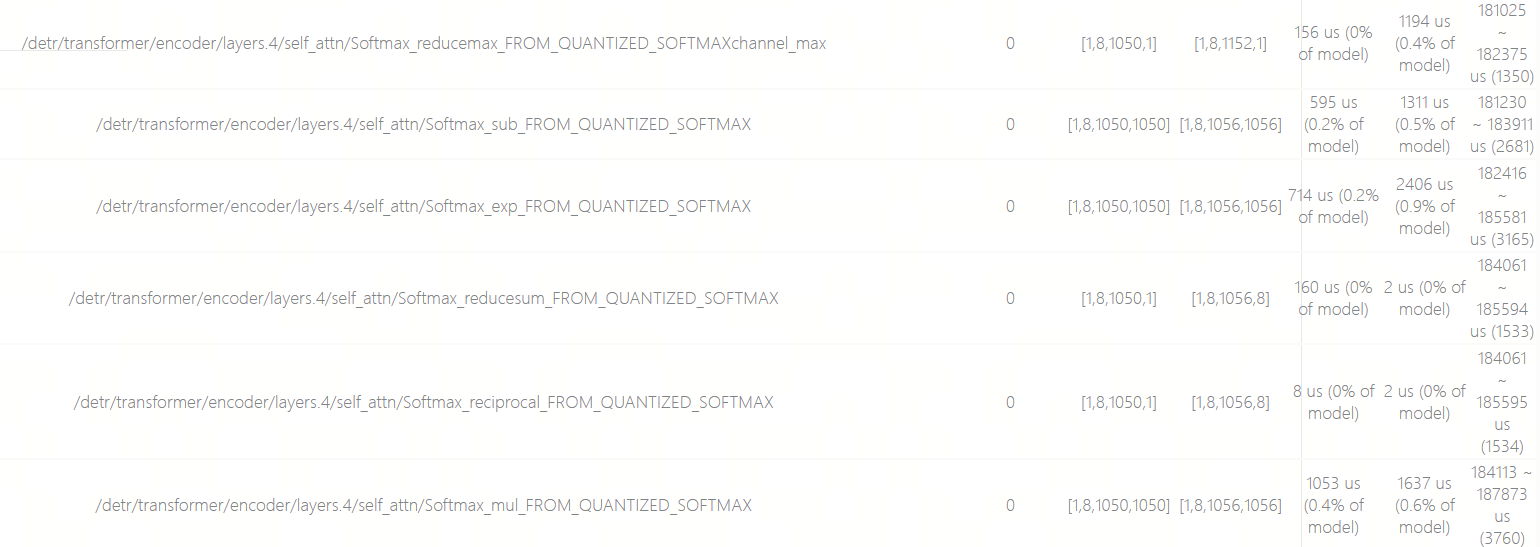
地平线优化算法Softmax(8x25x42x1)的静态耗时预估:

Softmax算子的量化策略为:将其替换为6个等效算子,再逐一对每个算子进行量化。
优化BPU硬件对齐耗时
这里还是以DETR算法为例,对于encoder中layers0的线性层计算,公版算法和地平线优化算法的耗时情况如下:
公版算法

地平线优化算法

可以看到,无论是公版算法还是优化算法,这两层结构的计算量都是相同的,均为1.1GOPs。但由于输入张量的Shape不同,导致耗时差异明显。公版算法的Shape是1x1050x1x2048和1x1050x256,受到BPU硬件对齐规则限制,第三维从1 Padding到8,大量计算资源消耗在无效数据上,造成了严重的算力浪费。而优化算法的Shape是1x25x42x2048和1x25x42x256,Padding规则仅仅将第二维的25变成26,第三维的42变成48,相比公版Shape节约了大量的BPU计算资源。仅这一处优化就可降低约3.6毫秒耗时,整个模型有多处相似结构,累计的性能提升非常明显。
优化数据搬运耗时
数据搬运特指Reshape/Transpose这类不做数值计算,只做搬运操作的算子。对于SwinT算法,公版和优化版本在Transformer核心算子(如Softmax,Layernorm,Matmul)的计算耗时方面表现相当,主要区别在于Reshape和Transpose的耗时差异,具体如下表所示:

这种优化手段需要用户通过算法设计,尽可能规避模型中出现耗时明显的Transpose和Reshape算子。但也不是所有的Transpose和Reshape都有大量耗时,需要结合html静态性能报告进一步分析排查。
如果用户选择使用QAT链路进行Transformer算法的量化部署,算法工具链还提供了更多了性能优化手段。
使用QAT算子避免数据搬运
在Transformer结构中,经常需要对Matmul的其中一个输入Transpose变换维度,这个Transpose往往会带来一定的性能开销。用户可以使用QAT封装的Matmul算子,该算子可以通过入参识别用户希望对哪个输入做维度变换,并在内部做高效处理,从而避免显式的Transpose操作。QAT封装的Matmul算子使用示例如下:
公版的Layernorm仅支持对最后若干维度做计算,如果要对中间维度做Layernorm,需要先Transpose。而使用QAT封装算子可以避免Transpose,直接对中间维度做Layernorm。具体使用方式如下:
使用四维算子代替三维算子
BPU的硬件特性决定了其对四维数据的支持更加高效,在优化版本的Transformer算法中,大量使用了四维算子替换三维算子,以充分发挥BPU的计算特性。QAT也提供了封装好的四维Transformer模块供用户使用,如MultiHeadAttention,PatchMerging等。
此处展示QAT四维算子HorizonMultiHeadAttention的部分定义,可在GPU Docker中访问/usr/local/lib/python3.10/dist-packageshat/models/base_modules/attention.py查看完整代码:
DETR算法的PatchMerging结构也可以使用四维算子做替换,示例如下:
使用Conv2d代替Vector计算
这里Vector并不是指std::vector或者一维向量,而是指模型中可以并行处理的一批数据元素,例如一个通道内的像素值。Vector计算通常指逐元素操作,如均值/求和/取最大值等,与之相对应的是Tensor计算。Transformer算法中比较典型的Vector计算有Elementwise、Reduce等,模型中如果Vector计算占比较多,会影响BPU利用率,导致部署性能下降。
在一些情况下,可以使用Conv2d等效替换Vector操作(如Mul/Reduce等)。像是Conv->ReduceSum->Conv串接的结构,其中ReduceSum就可以替换成Conv2d:比如reduce on C可以构建为input channel = C,output channel = 1的Conv2d;reduce on H/W 可以构建为kernel_h = H或kernel_w = W的Conv2d等。使用Conv2d代替Vector计算,会提升算法的部署性能,同时不影响计算精度。


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)