
💬 最近在处理算法工具链相关问题时,我遇到了一个关于 InstanceBatchNorm 支持 的兼容性问题。
借这个机会,我也系统学习并梳理了各类 Normalization 算法 的原理、差异,以及在不同芯片(特别是地平线 BPU)上的支持情况。
本文算是一次总结与分享,也希望能为正在做模型部署、调优或量化的同学提供一个完整参考。
一、引论:为什么深度学习离不开 Normalization?
它的核心目标是——让特征分布更稳定、更容易被网络学习。
我们可以从两个层面理解它的重要性:
- 训练层面:
不同层输出的数值范围差异可能巨大,导致梯度消失或爆炸;
归一化后,网络在不同 batch 间分布更稳定,使得训练更快、收敛更稳。
- 推理层面:
保证特征在不同输入样本之间的可比性;
避免过度依赖特定输入分布,提高泛化能力。
简单一句话:Normalization 让网络“更好训练、更好泛化、更好部署”。
二、常见的几种 Normalization 算法
类型 | 归一化维度 | 是否依赖 Batch | 是否可学习参数 | 常见场景 |
|---|---|---|---|---|
BatchNorm | 跨样本、按通道 | ✅ 是 | ✅ γ, β | CNN 主干、分类任务 |
LayerNorm | 单样本、全通道 | ❌ 否 | ✅ γ, β | Transformer、NLP |
InstanceNorm | 单样本、单通道 | ❌ 否 | ✅ γ, β | 生成任务(GAN、风格迁移) |
GroupNorm | 单样本、分组通道 | ❌ 否 | ✅ γ, β | 小 batch CNN |
三、直观理解:它们到底在“归一化”什么?
操作 | 计算方式 | 特征 |
|---|---|---|
BatchNorm | 对整个 batch 内每个通道统计 mean/var | 稳定训练,加速收敛;但依赖 batch 大小 |
InstanceNorm | 每个样本、每个通道独立统计 | 去除样本风格差异,适合生成模型 |
LayerNorm | 每个样本的所有通道一起归一化 | 适合序列模型(Transformer) |
GroupNorm | 每个样本将通道分组后归一化 | 小 batch 时效果稳定 |
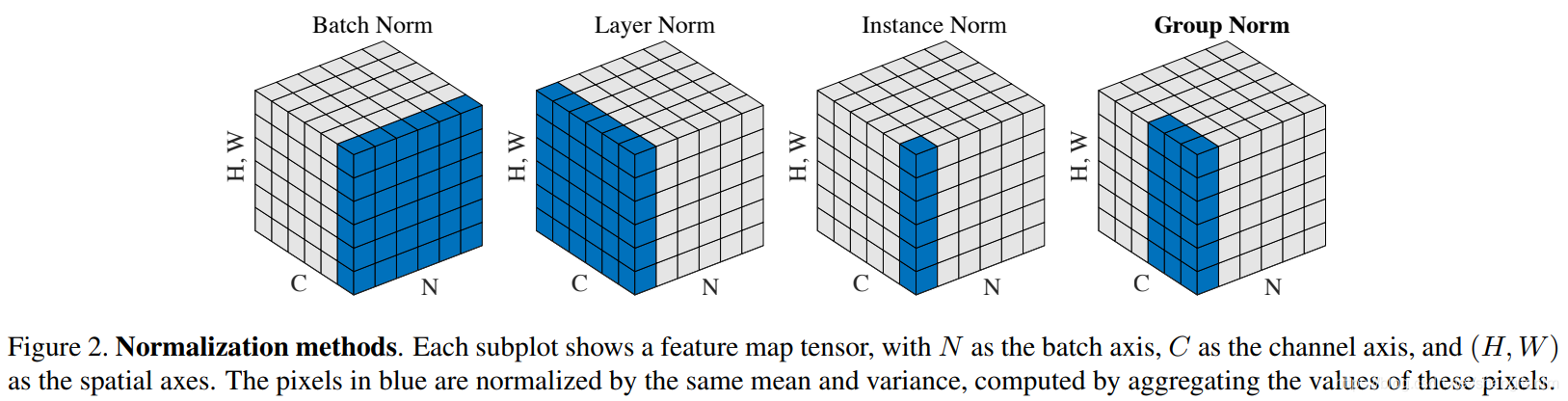 {{{width="800" height="auto"}}}
{{{width="800" height="auto"}}}这些图形让我们更清楚地看到:
- BatchNorm 在 batch 维度上求统计量;
- LayerNorm / InstanceNorm / GroupNorm 则在样本内部求统计量;
- 本质区别在于 “均值与方差的计算维度”。
用一场考试举例(一个班级有很多人,每个人有不同的科目,每个科目有期中、期末等多场考试):
四、核心数学公式
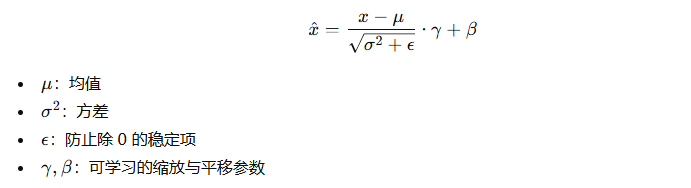
类型 | 均值方差的计算范围 |
|---|---|
BatchNorm | 全 batch 同通道 (N×H×W) |
LayerNorm | 单样本所有通道 (C×H×W) |
InstanceNorm | 单样本单通道 (H×W) |
GroupNorm | 单样本每 G 个通道一组 (G×H×W) |
五、差异分析与应用场景
维度 | BatchNorm | LayerNorm | InstanceNorm | GroupNorm |
|---|---|---|---|---|
归一化范围 | 跨 batch 的每通道 | 单样本所有通道 | 单样本单通道 | 单样本分组通道 |
依赖 batch size | ✅ 高度依赖 | ❌ 不依赖 | ❌ 不依赖 | ❌ 不依赖 |
训练收敛速度 | 🚀 极快 | ⚙️ 稳定 | 🧘 稳定 | 🚀 稳定快速 |
推理阶段一致性 | ❌(需移动平均) | ✅ 一致 | ✅ 一致 | ✅ 一致 |
量化友好性 | ⚠️ 一般(需特殊融合) | ✅ 友好 | ✅ 友好 | ✅ 友好 |
硬件加速可行性(BPU/NPU) | ✅ 优化良好 | ✅ 良好 | ⚙️ 中等 | ✅ 良好 |
典型任务 | 图像分类、检测 | Transformer、LLM | 风格迁移、GAN | 小 batch CNN |
PyTorch 模块 | nn.BatchNorm2d | nn.LayerNorm | nn.InstanceNorm2d | nn.GroupNorm |
六、BPU支持情况、应用场景 和 部署建议
🧠 支持情况
在模型部署到地平线芯片(如 J5/J6/NASH 系列)时,部分 Normalization 算子可直接在 BPU 上执行,部分需要由 CPU 代跑或替换。
Operator | BPU | CPU | 量化友好性 | 备注 |
|---|---|---|---|---|
BatchNormalization | ✅ | ✅ | 推荐 | 支持融合到 Conv,可减少额外计算, 性能最佳 |
GroupNormalization | ✅ | ✅ | 中等 | 原生支持,对 batch 小的网络量化友好 |
InstanceNormalization | ✅ | ✅ | 一般 | 支持良好,适合生成模型 |
LayerNormalization | ✅ | ✅ | 稳定 | 支持常见形式(Transformer中常见) |
LpNormalization | ❌ | ❌ | 不支持 | 暂不支持 |
MeanVarianceNormalization | ❌ | ❌ | 不支持 | 暂不支持 |
RandomNormal / NormalLike | ❌ | ❌ | 不支持 | 属于随机张量生成,非推理阶段算子 |
StringNormalizer | ❌ | ❌ | 不支持 | 文本预处理相关,CPU侧处理 |
🔧 部署建议
场景 | 推荐归一化方式 | 理由 |
|---|---|---|
图像分类、检测(大 batch) | BatchNorm | 稳定、成熟、融合好 |
小 batch 训练 | GroupNorm | 不依赖 batch 统计 |
Transformer / NLP / LLM | LayerNorm | 适合序列特征 |
图像生成(GAN/风格迁移) | InstanceNorm | 去除个体风格差异 |
BPU 量化部署 | Conv+BatchNorm 融合 | 性能最优、量化友好 |
🏁 应用总结
七、PyTorch 代码示例
这些算子在 地平线工具链 中均能正确识别,部分可自动融合。
八、常见注意事项
BatchNorm 推理模式需固定统计量
- InstanceNorm 在小 batch 下稳定性好(不依赖 batch)
LayerNorm 在序列模型(Transformer)中最常见
GroupNorm 在小 batch 的 CNN 中常替代 BatchNorm
- 量化部署前会融合或替换 BN,否则量化后 scale 不一致会带来偏差
- inplace 运算注意:Norm 层一般不应 inplace 操作,否则反向传播会报错。
九、结语
它是一块性能与稳定性的基石,理解它不仅能优化模型训练的稳定性,更能在 地平线 BPU 平台 上充分发挥算力潜力。
🌟 一句话总结:
让每一次归一化,都为模型的性能与稳定性加分。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)