
前言
同时,考虑到大模型部署中 KV 缓存对显存和吞吐量的影响(如 LLaMA-65B 模型权重需 65G GPU 内存,KV 缓存可达数十 GB),研究首次将 KV 缓存纳入量化范围,与权重、激活一同量化,旨在突破长序列生成的吞吐量瓶颈。最终,团队在 LLaMA-7B/13B/30B 模型上实现了低至 4 比特的精准量化,且相较于无训练(training-free)方法,在低比特场景下模型效果提升显著。
LLM-QAT技术方案介绍
QAT是基于浮点训练数据学习量化误差的技术,因为需要在大规模数据集上做训练,因此LLM-QAT具有以下两个应用难点:
一方面,大模型训练技术复杂、算力需求集中;
另一方面,QAT 依赖大量训练数据,但大模型预训练数据规模庞大、预处理困难,且受法律限制部分数据无法使用,多阶段训练(如指令微调、RLHF)的普及也进一步增加了 QAT 复现难度。
研究采用无数据知识蒸馏方法规避对训练数据的依赖,该方法利用预训练模型自行生成数据,无需原始训练集就能完成量化。仅 100k 规模的采样数据便能保证量化模型性能,大幅降低计算成本(所有实验在单个 8 - GPU 节点完成)。此思路首次将 QAT 应用于大模型,实现 4 比特精准量化,还通过 KV 缓存量化解决了长序列吞吐量瓶颈问题。
下面将对核心技术方案进行介绍。
无数据(data-free)蒸馏:数据生成与采样策略
为让微调数据贴近预训练数据分布,研究设计了 “逐 Token 生成” 的数据构建方式,流程如下:
- 数据生成逻辑:从词汇表中随机选取起始 Token(),由预训练模型生成下一个 Token(),再将作为新的输入生成,迭代此过程直至达到句子结尾或最大长度。
- 采样策略优化:
- Top-1 确定性采样:直接选择概率最高的 Token,但生成句子多样性不足,易出现循环重复。
- 全随机采样:基于 SoftMax 输出的概率分布随机选 Token,提升句子多样性,显著改善学生模型微调精度。
- 混合采样(最终采用):前 3-5 个 Token 采用 Top-1 确定性采样(保证初始预测置信度),后续 Token 采用随机采样(平衡多样性与稳定性)。
LLM-QAT方案详解
LLM-QAT 的创新点在于:通过无数据蒸馏突破训练数据依赖,首次实现大模型 4 比特精准量化,并将 KV 缓存纳入量化范围解决部署瓶颈。其应用价值体现在:
- 部署成本降低:4 比特量化大幅减少显存占用与算力需求,适配更多硬件环境;
- 通用性强:可应用于多阶段训练模型(如指令微调、RLHF 后的模型),不受原始训练数据限制;
- 技术兼容性:与 SmoothQuant 等现有技术部分兼容,可进一步拓展优化空间。
下面将对其方案进行详细介绍。
量化基础:线性量化分类
研究聚焦线性量化(均匀量化),根据是否截断数据分为两类:
- MinMax 量化:保留所有数据范围,量化公式为:
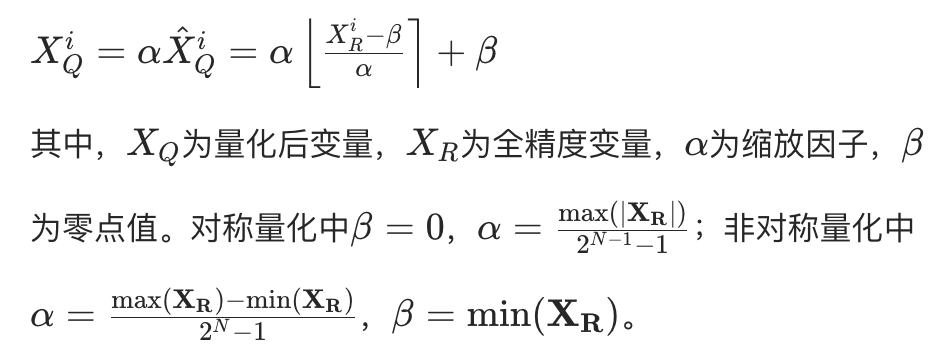
- 基于裁剪的量化:截断异常值以提升中间值精度,公式为:
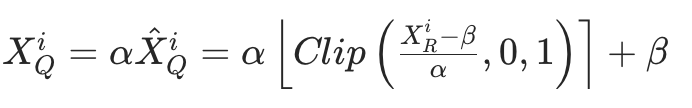
大模型专属量化适配
- 异常值处理:大模型权重与激活存在大量异常值,若采用裁剪方法会导致训练初期困惑度骤升(>10000),信息丢失严重且难以恢复。因此,研究选择保留异常值,采用对称 MinMax 量化,公式简化为:

- 量化粒度选择:采用 “逐 Token 激活量化 + 逐通道权重量化”,确保量化效率与精度平衡;对于带门控线性单元(GLU)的模型,因激活权重呈对称分布,对称量化适配性更佳。
KV 缓存的量化感知训练
借鉴激活量化的思路,对 KV 缓存采用逐 Token 量化:生成过程中,当前 key 和 value 会被量化并存储对应缩放因子;训练时对 key 和 value 的整个激活张量量化,并将量化函数融入梯度计算,确保训练有效性,最终缓解长序列生成的显存与吞吐量压力。
知识蒸馏:Logit 蒸馏的优势
采用基于交叉熵的 Logit 蒸馏训练量化学生模型,公式为:
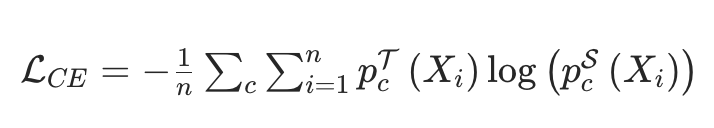
相较于 “仅用下一个 Token 作为标签” 的训练方式,Logit 蒸馏能利用教师模型的完整分布信息,规避采样噪声影响;而组合注意力蒸馏或隐藏层蒸馏会降低性能,因此未被采用。
伪代码实现
LLM-QAT与其他量化方法对比
方法 | 核心思想 | 是否需要训练 | 适用场景 |
GPTQ | 最小化每层的权重量化误差(通过 Hessian 近似),仅作用于线性层的权重。 | 否 | 只想快速推理加速,无训练资源 |
AWQ | 激活通道重要性分析 + 激活缩放,使得重要通道保留更多精度。 | 否 | 只想快速推理加速,无训练资源 |
SmoothQuant | 将激活的动态范围“转移”到权重中,从而让激活分布更平滑、可量化。 | 否 | 有少量样本做校准,追求高精度 |
ZeroQuant2 | 分层激活校准 + 知识蒸馏微调,结合量化参数优化。 | 是 | 有少量数据、但无大规模训练资源,对精度要求较高的下游任务 |
LLM-QAT | 使用 Teacher 模型自生成伪数据,在无数据条件下蒸馏 Student,并进行全量 FakeQuant 感知训练。 | 是 | 无任何数据但希望高精度压缩模型,想统一压缩推理系统(包括 KV cache) |
LLM-QAT使用示例
本示例使用 GPT-2 模型做示范,原理与 LLaMA 一致,只是规模小很多:
参考链接
LLM-QAT: Data-Free Quantization Aware Training for Large Language Models
https://zhuanlan.zhihu.com/p/647589650


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)