
今天分享2最新篇具身智能(Embodied AI)世界模型(World Model)和安全挑战的系统性综述



🌏 为什么你需要关心“世界模型”?
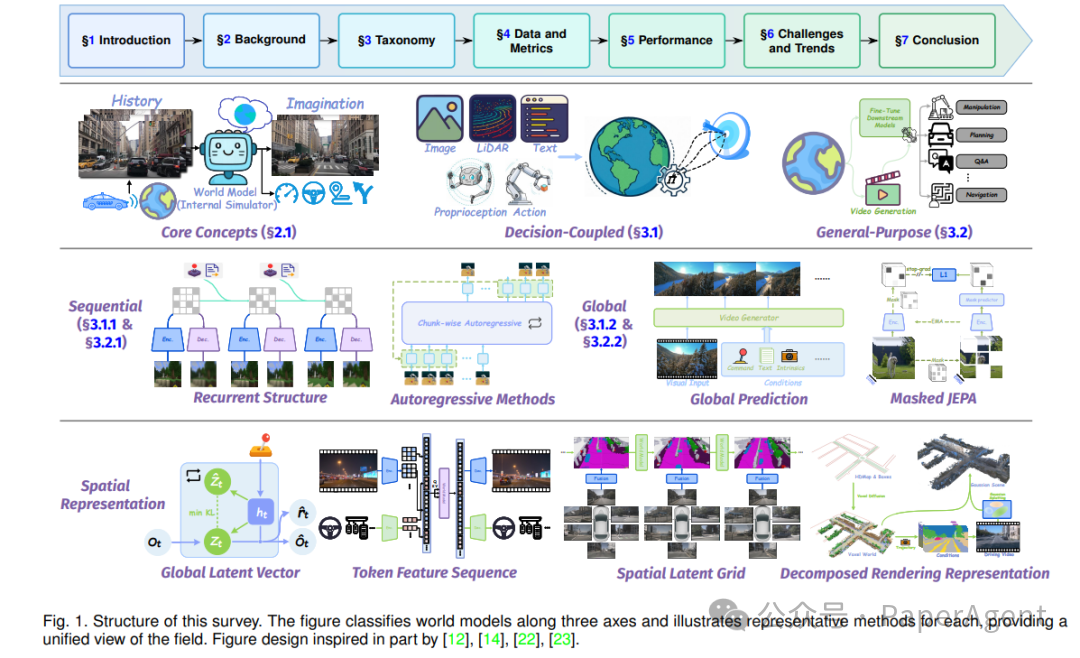
Fig-1 论文整体框架
图1:世界模型的三大分类轴——功能、时间、空间
🧩 三轴 taxonomy:给每篇论文贴「坐标」
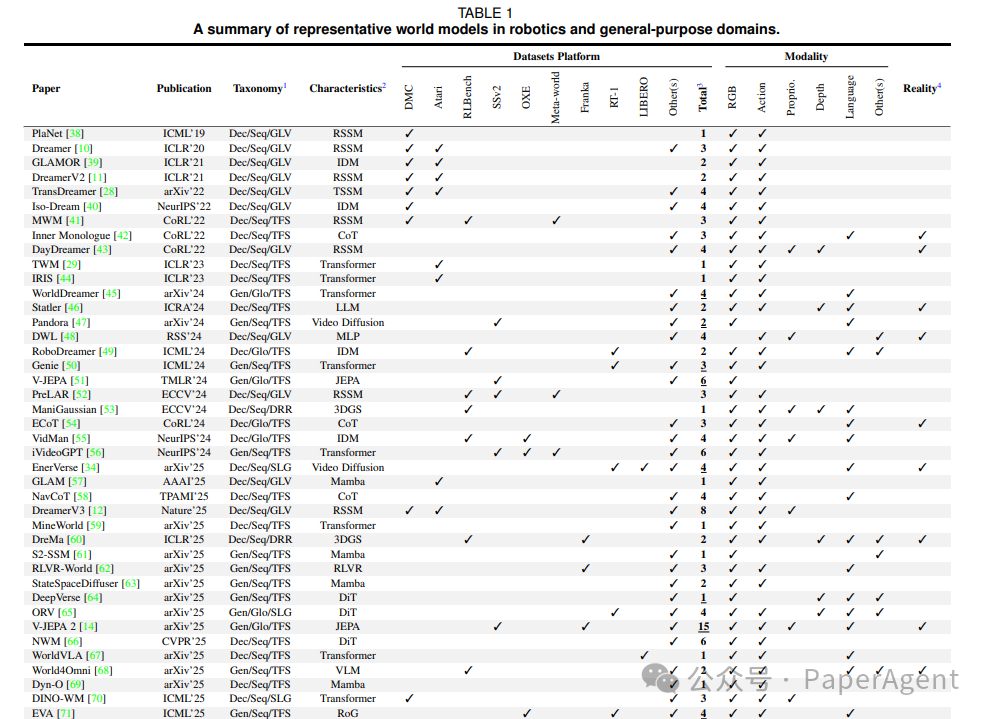
Table-I 机器人领域代表方法
表1:机器人/通用域代表方法「坐标」一览(对应论文 Table I)
维度 | 选项 | 一句话释义 |
|---|---|---|
功能 | Decision-Coupled | 为「决策」量身定做,强耦合策略 |
General-Purpose | 通用视频生成器,下游任务即插即用 | |
时间 | Sequential | 自回归,一步一帧,省显存但误差会累积 |
Global | 一次预测全序列,速度快但吃算力 | |
空间 | GLV / TFS / SLG / DRR | 从「一把向量」到「3D 高斯」,保真度递增、效率递减 |
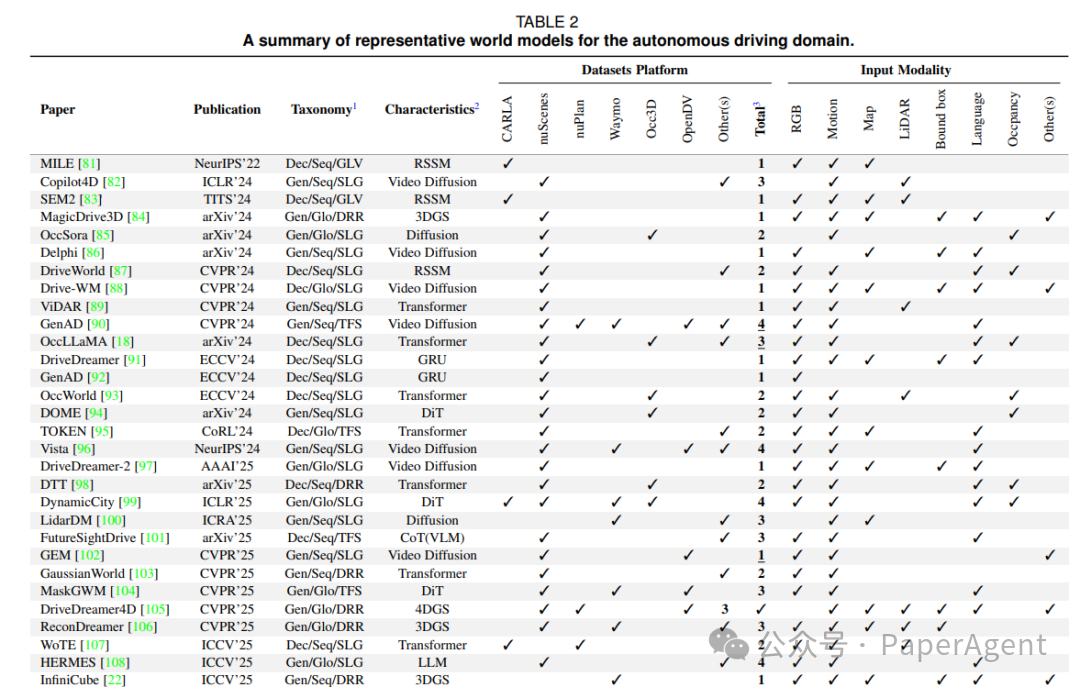
Table-II 自动驾驶代表方法
表2:自动驾驶域代表方法「坐标」一览(对应论文 Table II)
📊 性能擂台:像素生成、场景理解、控制任务
1️⃣ 像素生成 - nuScenes 视频
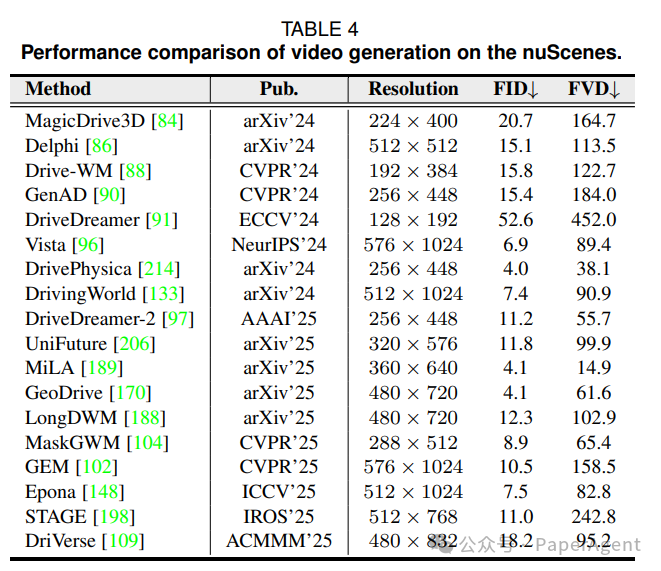 表4:nuScenes 视频生成排行榜
表4:nuScenes 视频生成排行榜2️⃣ 场景理解 - 4D Occupancy 预测
指标:mIoU↑
- COME(GT ego)平均 mIoU 34.23%,领先第二名 7 个点
结论:给「真值轨迹」当外挂,长期预测直接起飞
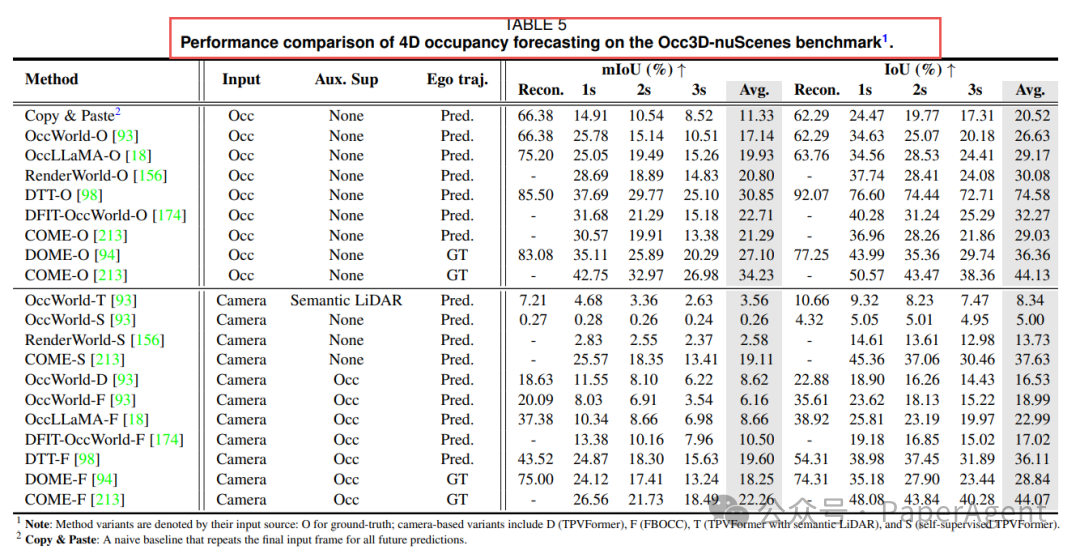 表5:Occ3D-nuScenes 4D Occupancy 预测(对应论文 Table V)
表5:Occ3D-nuScenes 4D Occupancy 预测(对应论文 Table V)3️⃣ 控制任务 - DMC/RLBench
- DreamerV3 在 5M step 内 20 任务平均 823 分,依旧能打
- VidMan 在 RLBench 18 任务平均成功率 67%,把「视频扩散+IDM」玩出花
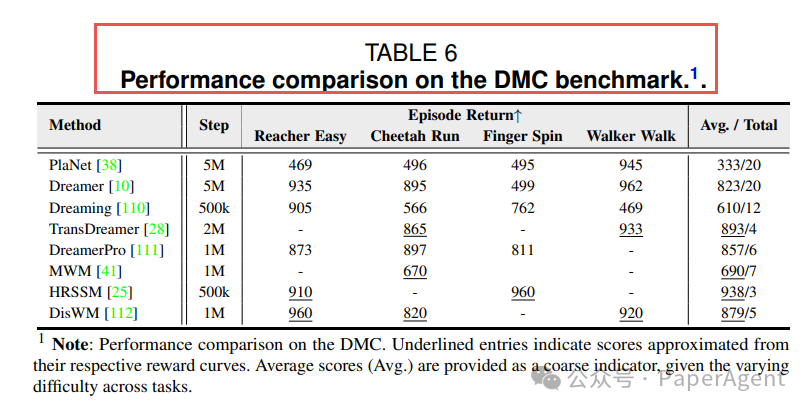
Table-VI DMC 控制得分
表6:DMC 控制任务得分
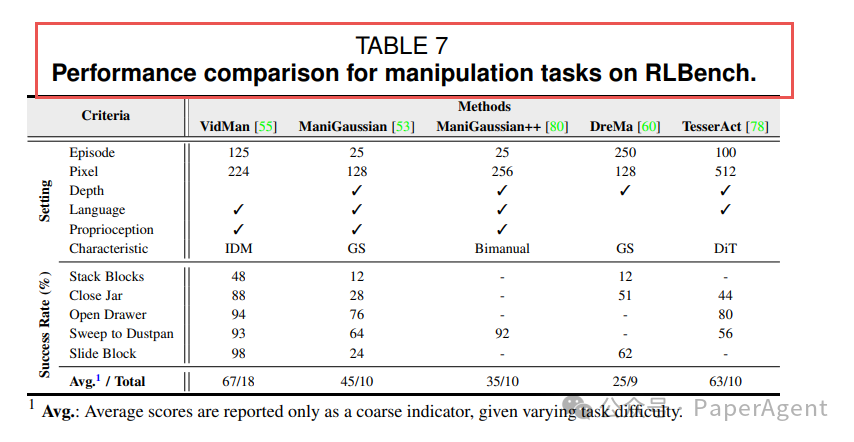
Table-VII RLBench 操作成功率
表7:RLBench 操作成功率

🚧 具身智能Agents安全挑战
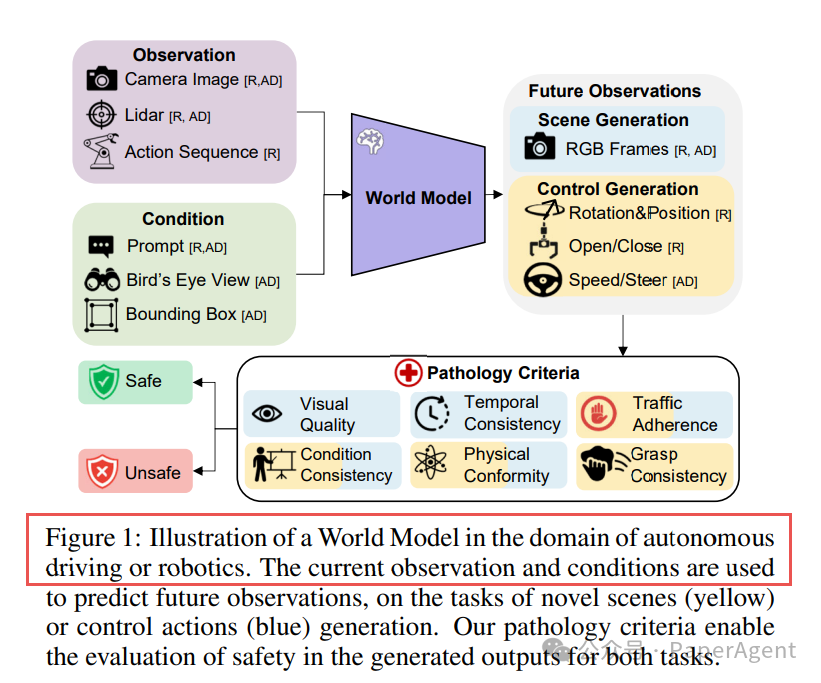
自动驾驶或机器人领域中世界模型的示意图。当前观测和条件被用于预测未来观测,任务包括新场景(黄色)或控制动作(蓝色)的生成。我们的病理标准使得能够对这两个任务生成的输出进行安全性评估。
Visual Quality:MagicDrive-DiT 生成的帧出现模糊与失真
Temporal Consistency:Open-Sora 的时序不一致导致物体“闪现”
Traffic Adherence:Comsos 违反交通规则(红灯通行)
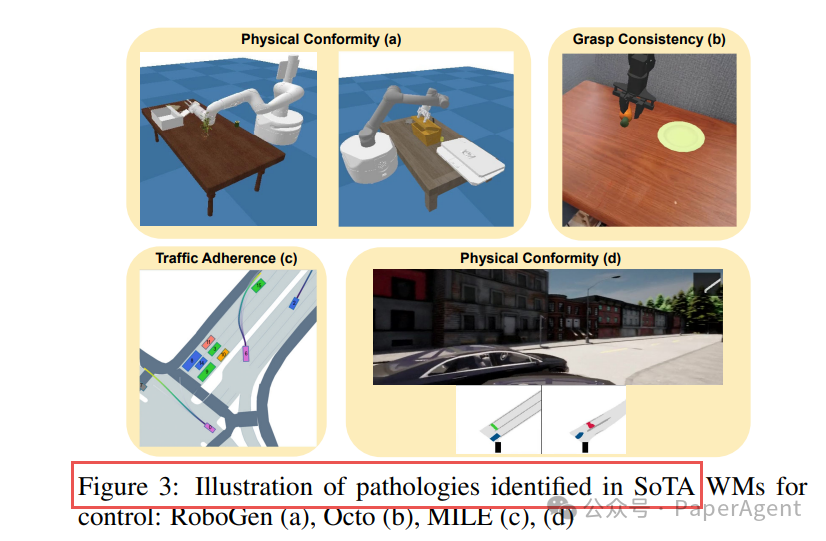
Physical Conformity:Vista 出现车辆漂浮的物理违规
Condition Consistency:This&That 输出与文本提示不符

(a) RoboGen 抓取姿态异常
(b) Octo 轨迹与指令条件不一致 (c)(d) MILE 产生碰撞与物理违规
文章转载自公众号:PaperAgent
原文链接:https://mp.weixin.qq.com/s/hhR01dJ0MdoevlqaGptfBg

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)