
目录:
一、Tesla FSD V14的发布
二、三大要点:自回归transformer,音频感知,内存优化
三、FSD和Robotaxi 网络的关系
四、总结

一、Tesla FSD V14 的发布
2025 年 10 月 7 日深夜(美国时间),特斯拉正式向北美地区搭载 HW4.0 硬件的车主推送 FSD(完全自动驾驶)V14 版本(具体是14.1版本),这场被业内视为 “近一年来最重大的系统升级”,比原计划推迟近一个月 —— 据官方披露,延期原因是发布前发现关键安全漏洞,需通过多轮测试修复。作为特斯拉自动驾驶技术的年度旗舰更新,V14 的发布承载着双重意义:既是对消费者端 FSD 功能的全面强化,更是 Robotaxi 项目技术成果向量产车下放的关键一步。
从推送策略看,特斯拉延续了 “硬件适配优先” 的原则:首批更新仅限搭载 HW4.0 芯片的 Model 3、Model Y 及 Cybertruck 车型,HW3.0 用户需等待后续优化版本 —— 这一安排源于 V14 对计算能力的更高需求,其模型参数量较 V13 提升 4.5 至 10 倍,需更强硬件支撑实时运算。截至发布后 48 小时,北美已有超 2 万名用户收到推送,实测反馈集中在自动泊车流畅度、复杂路口决策等场景的显著提升,有车主评价 “泊车精度优于人工操作”,但也存在挡风玻璃污渍提示机制被调侃 “推卸责任” 等争议。

图 FSD V14自动离开地下车库,图片来自网络
从网络资料看,没有大张旗鼓的发布会,就是直接推送,“润物细无声”。
值得注意的是,特斯拉在更新说明中反复强调 “FSD 仍属 Supervised 模式”:驾驶员需全程保持注意力,系统默认关闭 “刹车确认” 功能,仅提供手动启用选项。这一表述与马斯克此前 “无人监督驾驶即将实现” 的宣传还是有一点落差的,表现出技术理想与安全现实的平衡。所以说即便 V14 实现很多突破,至少目前并不等于真正意义上的 L4 级自动驾驶。
二、三大要点:自回归transformer,音频感知,内存优化
作为业界大事,FSD V14发布自然已经有很多长篇报道,但本文本着“少就是多,less is more”的原则,聚焦其三大要点如下:
(一)自回归 Transformer
自回归 Transformer 是 FSD V14 最核心的技术革新,它彻底改变了系统处理环境信息的底层逻辑。传统自动驾驶系统仅能基于当前帧数据 “被动响应” 路况,而 V14 通过这一技术实现了 “主动预测”—— 如同人类写句子时根据前文推断下文,系统可分析连续摄像头图像序列,结合历史数据预判道路参与者的未来行为。这种预测背后的第一性原理当然是人类的一个基本认知---物质世界是连续的,是渐变的,所以可以根据前面数据预测后面数据。
所谓自回归self-regression,做大数据和AI算法的同仁们一眼就知道一定和某种时间序列相关,自回归是参考自己来时路的意思,一般是越近权重越大,越远权重越小。
所以自回归transformer的技术原理可拆解为两层:“自回归” 特性确保系统按时间顺序处理数据,每一步决策都依赖前序信息积累。例如在十字路口,系统会跟踪行人的步态变化、身体转向等连续信号,而非孤立分析单帧图像;“Transformer” 的注意力机制则负责筛选关键信息,比如判断车辆转向灯状态比车身颜色更重要,优先聚焦影响决策的核心要素。这种组合让 FSD V14 具备了 “类人直觉”:据报道在实测中,面对横穿马路的行人,系统能提前 1.2 秒预判其折返意图并减速,较 V13 的响应速度提升 40%;在无保护左转场景,对向车辆 “抢行概率” 的预测准确率突破 92%。
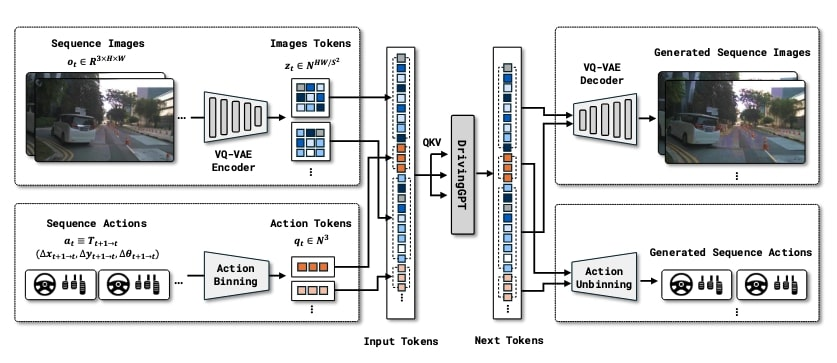
图 自回归总是和连续序列联系在一起,来自网络
特斯拉自动驾驶总监 Ashok Elluswamy 在内部邮件中透露,该模型整合了奥斯汀 Robotaxi 测试积累的 1200 万小时路测数据,通过仿真场景强化训练,已能覆盖施工区域、临时封路等 80% 的非常规路况。这意味着 FSD 不再局限于 “识别已知场景”,而是开始具备 “理解未知场景” 的某种程度的泛化能力。
(二)音频感知:多模态融合的 “听觉补盲”
FSD V14 首次将音频感知纳入核心感知体系,与视觉、雷达形成 “三位一体” 的多模态融合架构,解决了纯视觉方案在复杂环境下的局限性。系统通过车顶嵌入式麦克风阵列采集环境声音,经 VocalCore 3.0 算法处理,在 90dB 噪音(约等于高速行驶时的车内噪音)环境下仍能保持 98.2% 的识别准确率。
其核心应用集中在两大场景:一是紧急车辆识别,当检测到救护车、消防车的警笛声时,系统可结合声音方位、强度变化判断车辆行驶方向,即便视觉被货车遮挡,仍能提前 200 米启动减速靠边程序,较纯视觉方案的响应距离提升 60%;二是驾驶交互优化,驾驶员可通过语音指令切换 “速度模式”“停车偏好” 等设置,无需手动操作中控屏,指令识别延迟控制在 150ms 以内。

图 FSD V14听声辨车,来自网络
不过当前音频感知仍有局限:暂不支持识别行人呼喊(所以不是说V14能听懂人话)、车辆异响等非标准声音信号,且依赖预设的警笛音频模板库,对改装车辆的特殊警笛识别率不足 70%。特斯拉在更新日志中明确,后续版本将通过用户众包数据扩充音频样本库,提升系统的环境适应性。
(三)内存优化
随着模型规模扩大,FSD V14 面临 “计算延迟” 与 “硬件兼容” 的双重挑战。
V14版本将神经网络模型参数量提升至4.5-10倍(从55万增至5500万),增强数据处理能力和决策精度,使系统在复杂路口、恶劣天气等场景下具备更接近人类的判断力。又将相机帧率从36Hz提升至48Hz,配合视频压缩算法优化,显著提升交通信号、行人动作及车道细节的捕捉能力。就这还想运行在HW4.0甚至HW3.0上。自然会遇到塞不下的问题。
可以说,内存优化是一个被逼的改进。
特斯拉通过三层优化实现突破:首先改进数据缓存机制,对摄像头帧率从 36Hz 提升至 48Hz 产生的高频数据,采用 “增量式键值对缓存”—— 仅更新新帧的特征信息,复用历史计算结果,内存占用降低 35%;其次重构任务调度逻辑,将感知、决策、规划模块的计算资源动态分配,避免单一模块占用过多带宽;最后为 HW5 芯片预留接口,其算力较 HW4.0 提升 40 倍,可支撑未来无监督驾驶模型的部署。
这些优化带来了显著的实际效果:在 HW4.0 硬件上,V14 的平均决策延迟从 V13 的 180ms 降至 95ms,满足高速场景下的实时响应需求;更关键的是实现了 HW3.0 兼容 —— 通过模型压缩技术,老硬件用户虽无法启用全部功能,但核心的紧急避让、自动泊车模块仍能正常运行。特斯拉同步宣布,为已购 FSD 套件的 HW3.0 车主免费升级 HW4.0,预计 2026 年初完成全部更换。
三、FSD和Robotaxi 网络的关系
细心的读者可能注意到,每次FSD新版本,都会或多或少提到Robotaxi网络,二者什么关系呢?首先需要说明Robotaxi网络的网络不是指某种神经网络,就是指Robotaxi车群(每一辆叫做Cybercab)互联组成的网络。

图 金黄色的Cybercab,难道马斯克也受了中国文化影响,金色为贵
FSD V14以及以前版本的本质是特斯拉 Robotaxi 技术的 “消费级转译”,有点我们国内说军转民的味道—— 诸多核心功能直接源自奥斯汀 Robotaxi 内测项目的实践积累,这种 “技术反哺” 既加速了量产车体验升级,也为 Robotaxi 网络的商业化铺路。
从技术关联看,V14 的三大功能模块均服务于 Robotaxi 的落地需求:“到达选项” 功能允许用户指定停车场、路边等停车类型,实则是 Robotaxi “乘客上下车点精准定位” 技术的简化版,在奥斯汀测试中,该功能已实现对商场入口、写字楼大堂等场景的厘米级定位;紧急车辆避让机制则来自 Robotaxi 对运营安全性的核心要求 —— 在 10 辆内测车的路测中,该功能成功处理 127 次紧急车辆交汇场景,无一次碰撞风险;而自回归 Transformer 的预测能力,更是 Robotaxi 实现 “无安全员运营” 的基础,目前内测车已能通过该技术预判 85% 的突发路况,远程接管率较去年下降 62%。
特斯拉 Robotaxi 网络的商业化路径已逐渐清晰:2025 年 6 月启动的奥斯汀内测,投入 10 辆 Cybercab 车型,面向内部员工提供短途出行服务,采用 “远程接管 + 安全员随车” 的双重保障模式。V14 的发布则是在消费端验证关键技术 —— 当数百万辆量产车积累的路况数据反哺模型,Robotaxi 的泛化能力将进一步提升。马斯克在内部会议中透露,计划 2026 年将 FSD V14.5 版本部署至 Robotaxi fleet,取消随车安全员,仅保留远程接管团队。
四、小结
V14 虽整合了 Robotaxi 的技术成果,但还没有实现 “无人监督” 的核心目标;虽能处理多数常规场景,却仍需驾驶员应对极端情况;虽在北美市场落地,却因法规、路况差异,难以快速复制到欧洲、中国(国内的朋友要等一等了)等市场。
对于普通用户而言,V14 带来的是更安全和更省力的驾驶辅助体验;对于特斯拉而言,它是 Robotaxi 商业化的 “技术前哨”;对于整个行业而言,它可以算作一个mile stone节点。未来随着 HW5 芯片的量产、无监督学习的突破及监管政策的完善,FSD 与 Robotaxi 将形成更深度的协同,而 V14是其中的一个跳板。
文章转载自公众号:焉知汽车
作者:咖啡鱼
原文链接:https://mp.weixin.qq.com/s/r1MCr6kfWn-98DRaSOm2UQ

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)