
✍️ 写在前面的
比如:
- 用 torch.save(model, "xxx.pth") 给客户交付,结果对方一加载就报错,版本不兼容;
- 用 np.savez 保存大特征库,结果客户一解压,内存直接爆掉;
ONNX 导出的模型,跑到客户的推理环境里发现一堆自定义算子不支持……
整理完之后,发现不仅对自己有用,分享出来也许能帮到其他同样在踩坑的同学。
1. 为什么要关注文件格式?
做算法开发/工具链支持的同学应该都有类似经历:
数据集预处理好了,怎么存才又快又不占空间?
模型训练完了,权重怎么保存,交给同事或客户还能安全加载?
网络结构要跨框架部署和导出,格式怎么选才稳?
配置文件怎么写,既能让程序读懂,又能让人类看懂?
如果选错了格式,你可能会遇到:OOM、兼容性差、加载慢、甚至安全问题。
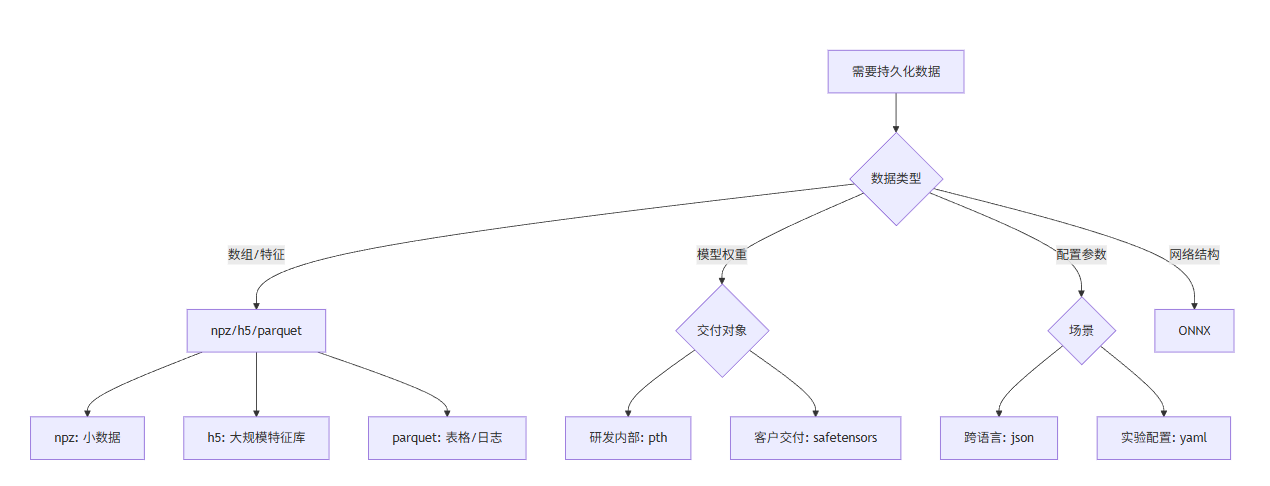
2. 算法工具链常见的持久化需求
结合日常工作,我把需求分成 4 大类:
- 数组/张量类数据:特征、中间结果、预处理样本
- 模型权重:checkpoint、部署文件
- 网络结构:跨框架交换、部署落地
- 配置/超参数:实验参数、任务描述
3. 常用文件格式对比
格式 | 常用库 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|---|
npy/npz | numpy | 读写飞快,shape+dtype 信息全 | 只能存数组,元数据弱 | 小规模特征缓存 |
h5 (HDF5) | h5py | 层级结构、压缩、局部加载 | 并发写复杂,依赖大 | 大规模特征库 |
parquet | pandas/pyarrow | 列式存储,压缩比高,跨语言 | 需要 pyarrow | 表格/日志/数据湖 |
pth/pt | torch | PyTorch 官方标配,灵活 | 反序列化可执行,不安全 | 内部研发快照 |
safetensors | safetensors | 零执行反序列化,安全快 | 只存 tensor,无结构 | 模型权重交付 |
onnx | onnx | 跨框架通用,部署生态好 | 自定义算子兼容差 | 模型推理部署 |
json | json | 简单、跨语言 | 不支持注释,可读性一般 | 跨平台配置 |
yaml | pyyaml | 支持注释,结构清晰 | 要注意用 safe_load | 实验配置 |
👉 一句话总结:
- npz/h5/parquet → 数据
- pth/safetensors → 权重
- onnx → 网络结构
yaml/json → 配置
4. 典型使用示例
存储特征:npz
模型权重(安全交付版):safetensors
网络结构:ONNX
配置文件:YAML
大规模特征库:HDF5
5. 我踩过的坑
1. pickle/pth 安全问题
torch.load 底层是 pickle,会执行对象构造 → 别加载不可信文件。
客户交付时一定用 safetensors。
2. npz 一次性加载
大文件直接 np.load,内存爆掉。
建议:大规模数据用 HDF5 或 Parquet。
3. HDF5 并发写
多进程写入经常锁冲突。
方案:单进程写,多进程读。
4. ONNX 自定义算子
导出的模型算子部署端不一定支持。
导出前一定确认 opset 与部署环境兼容。
6. 不同场景下的推荐方案
数据集/特征缓存
小规模:npz
大规模:h5 / parquet
模型权重
内部研发:pth (state_dict)
外部交付:safetensors
跨框架推理部署
标配:onnx
配置文件
实验调参:yaml(可加注释)
产品/跨平台:json
日志/指标
parquet → 后续用 Spark/Hive 分析很方便
7. 图表总结:一眼看懂
(1) 文件格式选择流程图
(2)文件格式对比打分表
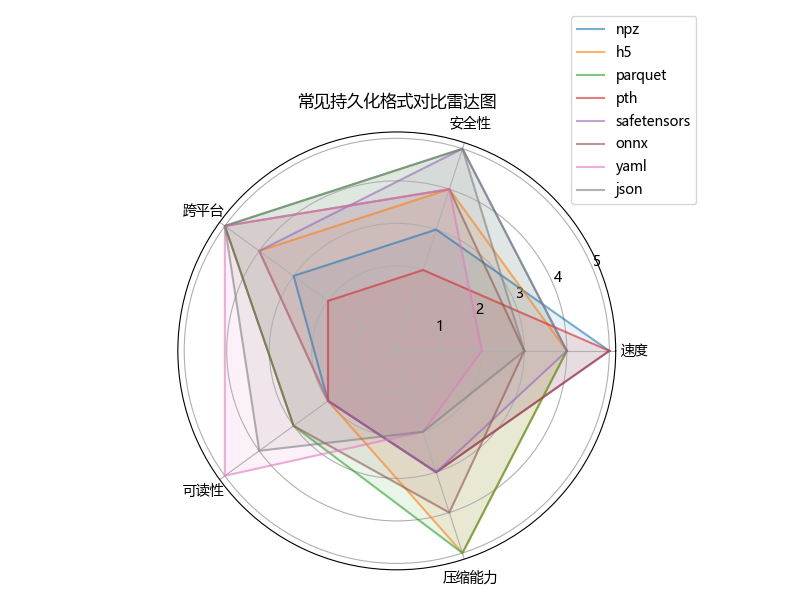
格式 | 速度 | 安全性 | 跨平台 | 可读性 | 适用场景 |
|---|---|---|---|---|---|
npz | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐ | 小规模特征 |
h5 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 大规模特征库 |
parquet | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 日志/表格 |
pth | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ | ⭐⭐ | 内部训练快照 |
safetensors | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 权重交付 |
onnx | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 模型部署 |
yaml | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 实验配置 |
json | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 跨语言配置 |
(3)雷达图(Python 生成)
8.案例分享
场景:客户交付模型权重
当时我们要把一个训练好的模型交付给客户,最初图省事,直接用 PyTorch 的方式保存:
客户拿到之后一加载就报错:
对方环境的 PyTorch 版本和我们不同,序列化对象不兼容;
更严重的是,torch.load 底层依赖 pickle,理论上存在执行任意代码的风险。
改进方案
1. 只保存 state_dict
2. 客户交付用 safetensors
同时在交付包里附带 README.md 使用说明,写清楚如何加载。
9. 最佳实践:交付目录结构
10. 最后的总结:
npz/h5/parquet 管数据,pth/safetensors 管权重,onnx 管网络,yaml/json 管配置。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)