
1.后量化转换(PTQ)
暂无
2. 量化感知训练(QAT)
2.1 模型尾部conv+relu结构未正确开启高精度输出
对于模型尾部的 conv+relu 结构,若发现未能按配置正确开启 int32 高精度输出,可优先检查是否存在共享算子。若 relu 是共享,则不会和其上游的 conv 发生 fuse 融合行为,relu 会单独出现,此时 conv 就不会开启高精度。
2.2 如何定位scale为nan的代码位置
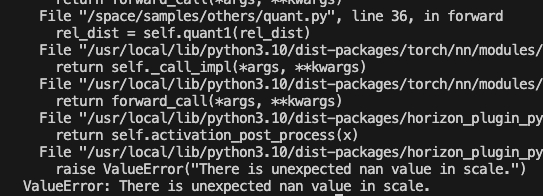
可以借助如下接口定位 scale 为 nan 的代码位置:
- "forward":会在第一次出现 nan 的位置报错:
- "save":默认值,会在 torch.save 时做检查:
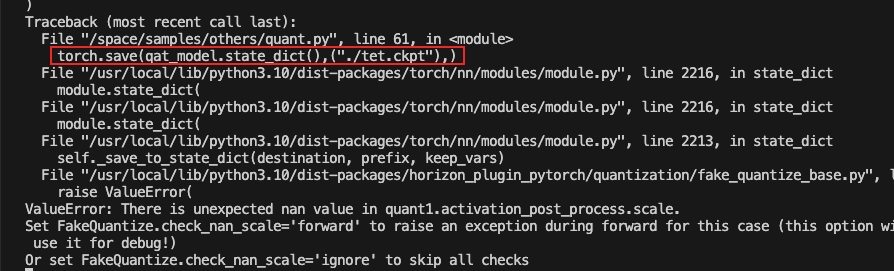
- "ignore":即不做检查。
2.3 如何关闭POT scale
J6B/P/H 相比于 J6E/M,新增了不同程度的浮点计算能力,所以当前默认的 scale 策略为 POT(Power of Two,即2的幂次),此时 BPU 硬件能直接支持 fp16int16 的量化/反量化节点。
但若模型未使用 fp16 精度,或基于 POT scale 发现量化精度调不上去,可尝试关闭 POT,即使用浮点 scale。
整体关闭:
针对个别算子关闭:
2.4 Plugin旧模板配置Gemm类算子双int16
J6 工具链自 v3.2.0 版本起支持 Gemm 类算子双 int16 量化,在旧 setter 模版上使用方式如下:
qconfig 配上双 int16
hbdk4_compiler 版本 ≥ v4.3.3
Conv2d/Linear 无需额外配置;Matmul 在 prepare 前需配置回退逻辑为 v2 版本
3. 模型部署
3.1 工具链与底软版本的兼容性
工具链在每轮大版本发布之前,都会在最新的底软版本上进行全量测试验证,因此我们优先建议使用对应的底软版本。在 OE-v3.2.0 版本及之后,理论上工具链和底软会尽量保持版本兼容,但由于工具链的模型推理与底软之间存在 firmware 共库开发的情况,因此有一定的耦合性。如果升级工具链(特别是UCP)后发生板上模型推理不兼容问题,可以尝试替换最新底软中的相关文件,主要涉及到的模块有:
模块 | 参考替换目录 |
Firmware | /usr/lib/firmware/*.bin |
libbpu.so (BPU驱动) | /usr/lib/aarch64-linux-gnu/libbpu.so.2.0.X (请注意此目录下的软连接) |
BPU ARM 侧驱动 ko 文件 | /usr/lib/modules/6.1.94-rt33/hobot-drivers/bpu/ |
libhbmem 库 | /usr/hobot/lib/libhbmem.so.1 (请注意此目录下的软连接) |
UCP 推理库系列 so |
|
3.2 查看bpu firmware版本号
bpu0 对于 J6 多核计算平台支持修改为不同的 BPU 核。
3.3 UCP侧如何降低CPU负载
关闭不需要的UCP调度线程
- BPU-LB-Schedule:该线程主要负责 BPU 负载均衡,对于 J6EMB 等单 BPU 芯片,还会复用这个线程去做 BPU 任务的生成和下发,所以其负载主要和 BPU 调用次数有关,即主要和对应时间内提交和完成的 BPU 任务的数量正相关
- CPU-OP-Process:该线程用于处理模型中的 CPU 算子
- DSP-Recv:该线程用于等待 DSP 任务处理完成并返回信息
- Sync-Scheduler:该线程负责 DSP/GDC/PYM 后端的调度
- Codec-Scheduler:该线程负责图像/视频编解码后端的调度
小模型复用 task handle
尝试使用内存LRU缓存
对于模型的输入输出不是实时申请和释放的,会在一开始就申请好并进行循环复用。所以如果在模型推理结束后就立刻执行内存释放操作,实际不会立刻释放,UCP 会等一段时间(默认至少1s)后才执行,所以可能会有内存泄漏的风险,建议是模型推理的内存块不要释放,且模型每次输入输出的虚拟地址是复用的;
单进程内 hbmem 的虚拟地址是不变的,可以直接复用,没有影响;跨进程场景暂不适用。
3.4 包含CPU算子模型的一致性未对齐
若 quantized.bc 和 hbm 均在 x86 平台推理也存在一致性误差,那么请提供相关模型文件给地平线进行进一步分析。
3.5 x86推理hbm报错Model march incompatible!

3.6 如何修改hbm文件中的model name
3.7 基于输入/输出名称移除节点
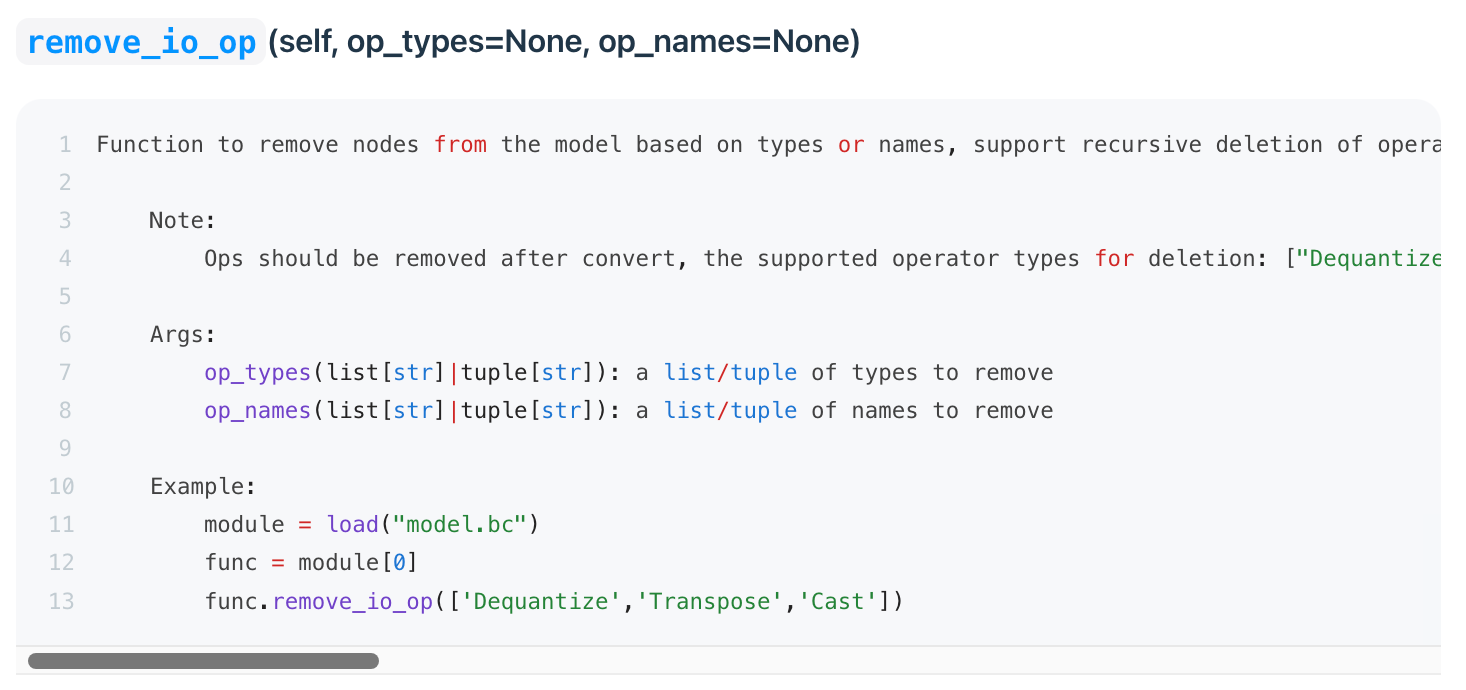
其中:
可移除算子类型包括:["Dequantize", "Quantize", "Transpose", "Cast", "Reshape", "Softmax"]
op_types:支持指定以上的算子类型进行模型首尾部的统一遍历和移除;
op_names:也支持指定算子名称进行移除,主要用于 PTQ 链路生成的模型,QAT 链路由于当前算子名称过长,所以实际并不实用。
- native_pytree=True(默认值):
- native_pytree=False:
4. 参考算法
暂无
5. DSP
5.1 自定义DSP算子后发现UCP VP接口未注册
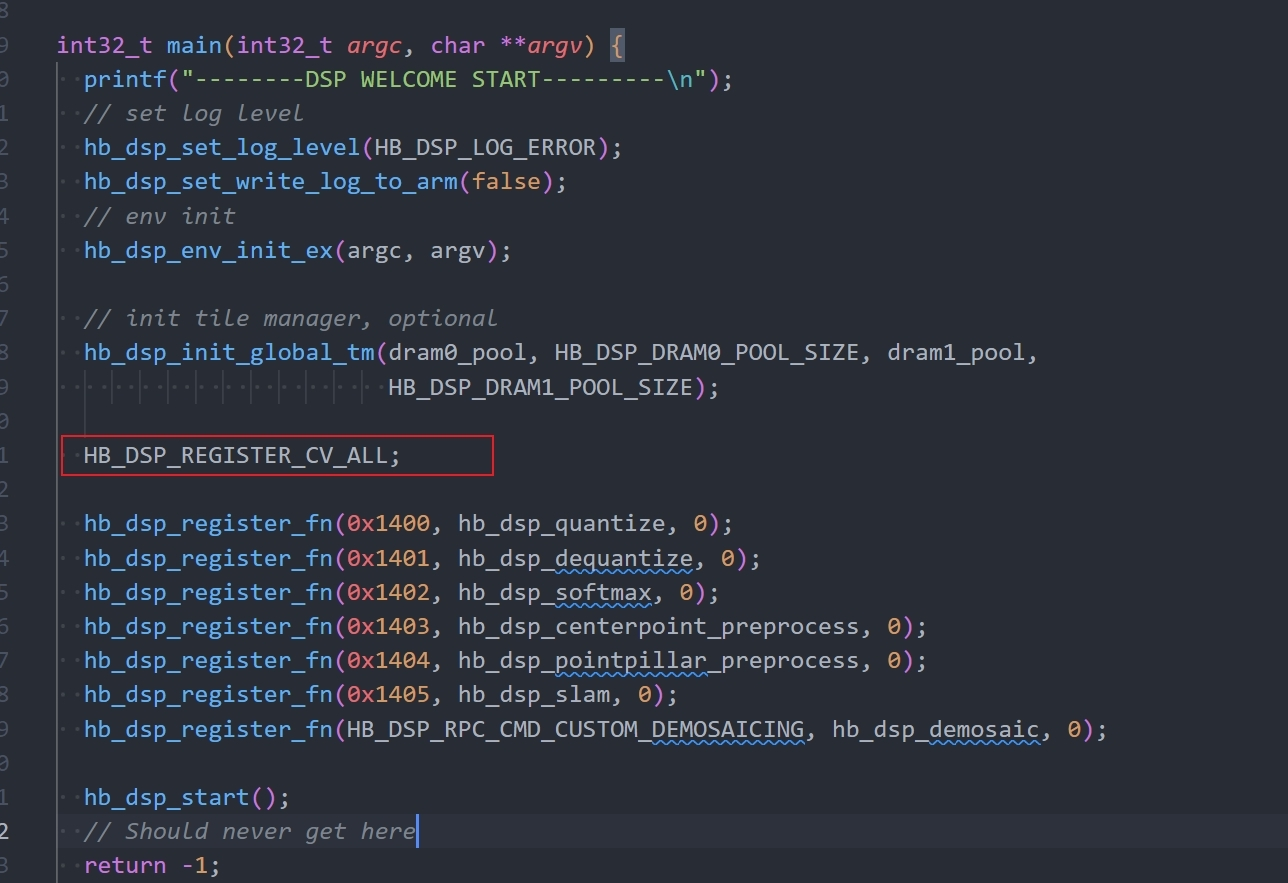
在自定义新的 DSP 算子后,需重新编译 DSP 镜像,若使用时调用 UCP 已实现的 VP 算子返回未注册错误,请优先从以下两处进行排查:
- 是否调用 HB_DSP_REGISTER_CV_ALL 宏注册官方已实现的 VP 算子,该宏定义位于 samples/ucp_tutorial/deps_xxx/ucp/plugin/dsp_plugin/hobot/include/cv/core.h
确保 CMake 中是否链接了算子库
5.2 DSP代码unmap、writeback接口的调用顺序是否有影响
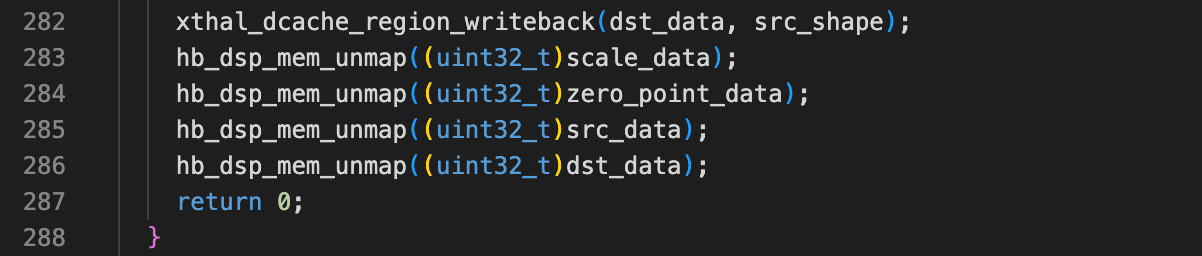
- 板端运行时:需要调用 ucp 的 map 接口和 xthal 的 invalid 和 writeback 接口,无需调用 ucp 的 unmap 接口;
- 仿真运行时:因为使用的都是 Acore 内存,无需做不同核间的 ddr 同步,所以仅需使用 ucp 的 map/unmap 接口,无需调用 xthal 的 invalid 和 writeback 接口。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)