
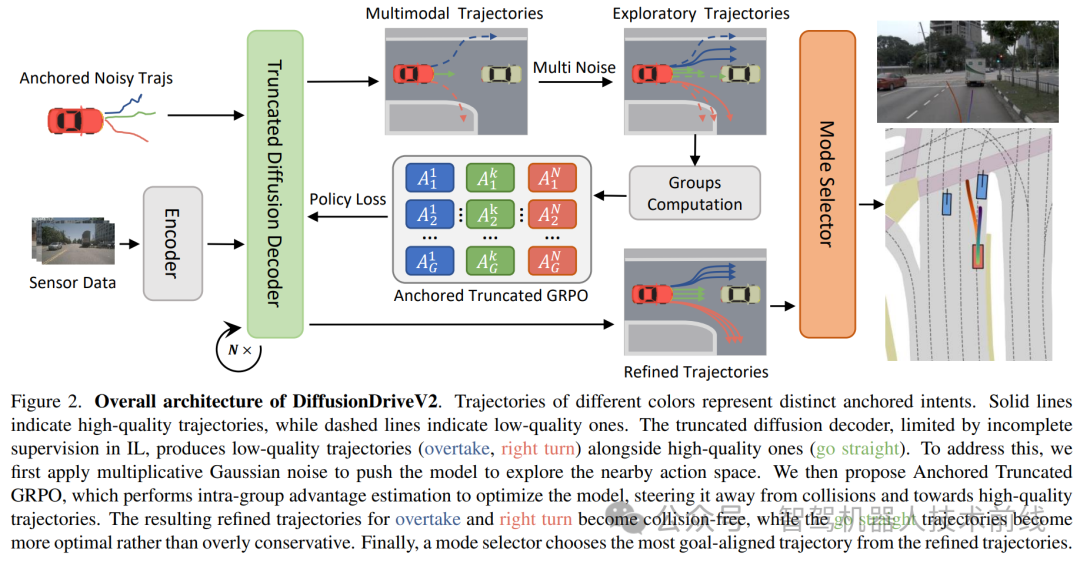
DiffusionDriveV2 结合强化学习与基于锚点的截断扩散模型,为端到端自动驾驶生成多样且高质量的轨迹。该方法在 NAVSIM v1 和 v2 基准测试中取得了最先进的性能,其中在 v1 上 PDMS 为 91.2,在 v2 上 EPDMS 为 85.5。
- 论文标题:DiffusionDriveV2: Reinforcement Learning-Constrained Truncated Diffusion Modeling in End-to-End Autonomous Driving
- 作者: Jialv Zou, Shaoyu Chen, Bencheng Liao, Zhiyu Zheng, Yuehao Song, Lefei Zhang, Qian Zhang, Wenyu Liu, Xinggang Wang
- 论文链接:https://arxiv.org/pdf/2512.07745
- 项目地址:https://github.com/hustvl/DiffusionDriveV2
端到端自动驾驶的生成扩散模型常面临模式崩溃问题,倾向于生成保守且同质的行为。尽管DiffusionDrive通过使用代表不同驾驶意图的预定义锚点来划分动作空间并生成多样化轨迹,但其对模仿学习的依赖缺乏足够的约束,导致多样性与持续高质量之间陷入两难困境。在本文中,我们提出了DiffusionDriveV2,它利用强化学习来同时约束低质量模式并探索更优的轨迹。这显著提升了整体输出质量,同时保留了其核心高斯混合模型(Gaussian Mixture Model)固有的多模态性。首先,我们采用尺度自适应乘性噪声(scale-adaptive multiplicative noise),这对于轨迹规划而言是理想的,以促进广泛探索。其次,我们采用锚点内GRPO(intra-anchor GRPO)来管理从单个锚点生成的样本之间的优势估计;并引入锚点间截断GRPO(inter-anchor truncated GRPO),以整合跨不同锚点的全局视角,从而防止不同意图(例如,转弯与直行)之间不当的优势比较,这可能导致进一步的模式崩溃。DiffusionDriveV2在与ResNet-34骨干网络对齐的闭环评估中,在NAVSIM v1数据集上达到了91.2 PDMS,在NAVSIM v2数据集上达到了85.5 EPDMS,创造了新纪录。进一步的实验验证了我们的方法解决了截断扩散模型(truncated diffusion models)在多样性与持续高质量之间的两难困境,实现了最佳权衡。
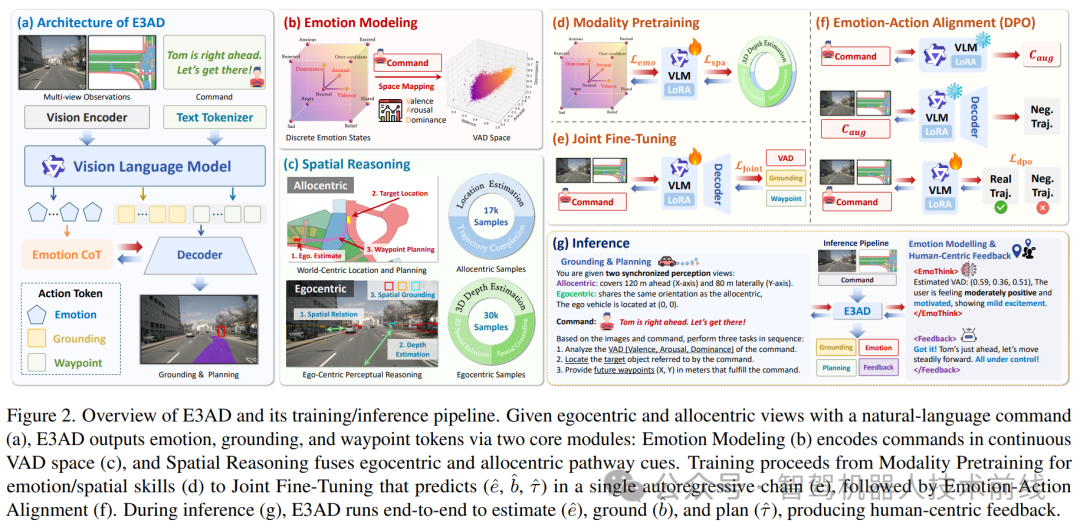
E3AD 引入了一种情感感知视觉-语言-动作模型,用于自动驾驶,该模型处理自然语言指令、视觉输入和乘客情绪状态,以生成以人为中心的驾驶轨迹。该框架在轨迹规划方面实现了最先进的性能,平均位移误差 (ADE) 降低了 17.01%,并在具有挑战性的指令上将视觉接地精度提高了高达 11.63% 的 IoU。
- 论文标题:E3AD: An Emotion-Aware Vision-Language-Action Model for Human-Centric End-to-End Autonomous Driving
- 作者:Yihong Tang, Haicheng Liao, Tong Nie, Junlin He, Ao Qu, Kehua Chen, Wei Ma, Zhenning Li, Lijun Sun, Chengzhong Xu
- 论文链接:https://arxiv.org/pdf/2512.04733
端到端自动驾驶(AD)系统日益采用视觉-语言-动作(VLA)模型,然而,它们通常忽略乘客的情绪状态,而这对于乘坐舒适度和自动驾驶的接受度至关重要。我们引入了开放域端到端(OD-E2E)自动驾驶,其中自动驾驶车辆(AV)必须理解自由形式的自然语言指令,推断情绪,并规划出物理上可行的轨迹。我们提出了E3AD,这是一个情感感知的VLA框架,它通过以下两个受认知启发的组件增强了语义理解:一个连续的价性-唤醒度-主导性(VAD)情绪模型,该模型从语言中捕捉语气和紧迫感;以及一个双路径空间推理模块,该模块融合了自我中心和异他中心视角以实现类人空间认知。一种以一致性为导向的训练方案,结合了模态预训练和基于偏好的对齐,进一步确保了情绪意图与驾驶行为之间的一致性。在真实世界数据集中,E3AD改进了视觉基础(grounding)和路径点规划,并在情绪估计方面实现了最先进(SOTA)的VAD相关性。这些结果表明,将情绪注入VLA风格的驾驶中,可以产生更符合人类习惯的视觉基础、规划以及以人为中心的反馈。
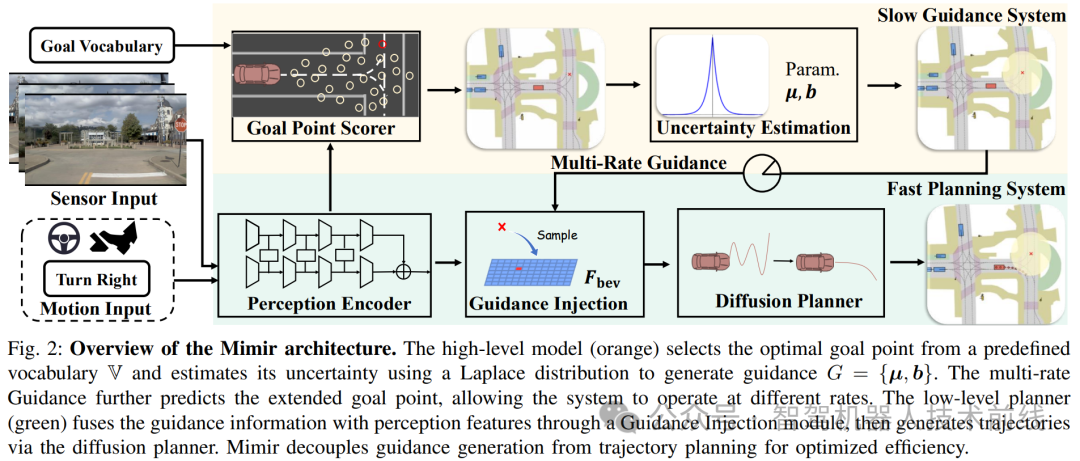
Mimir 引入了一种用于端到端自动驾驶的分层双系统,该系统融合了基于拉普拉斯分布的目标点不确定性传播和多速率引导机制。该框架在 Navhard 基准测试中使 EPDMS 驾驶分数提高了 20%,并使其高层引导模块的速度提升了 1.6 倍。
- 论文标题:Mimir: Hierarchical Goal-Driven Diffusion with Uncertainty Propagation for End-to-End Autonomous Driving
- 作者:Zebin Xing, Yupeng Zheng, Qichao Zhang, Zhixing Ding, Pengxuan Yang, Songen Gu, Zhongpu Xia, Dongbin Zhao
- 论文链接:https://arxiv.org/pdf/2512.07130
- 项目地址:https://github.com/ZebinX/Mimir-Uncertainty-Driving
端到端自动驾驶已成为自动系统领域的关键方向。近期研究通过整合高层引导信号来引导低层轨迹规划器,展示了卓越的性能。然而,其潜力常受限于不准确的高层引导和复杂引导模块的计算开销。为解决这些局限性,我们提出了Mimir,一种新颖的层次化双系统框架,能够依赖带有不确定性估计的目标点生成鲁棒轨迹:(1) 不同于以往的确定性建模方法,我们使用拉普拉斯分布估计目标点不确定性,以增强鲁棒性;(2) 为克服引导系统推理速度慢的瓶颈,我们引入了一种多速率引导机制,能够提前预测扩展目标点。在挑战性的Navhard和Navtest基准测试中,Mimir在EPDMS驾驶分数上实现了20%的提升,超越了先前的最先进方法,同时在高层模块推理速度上提升了1.6倍,且不影响精度。代码和模型将很快发布,以促进可复现性和进一步开发。
文章转载自公众号:智驾机器人技术前线
作者:智驾前线
原文链接:https://mp.weixin.qq.com/s/aPihSEeDMSl9t9cRZN7TKg

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)