
本文主要概述一下地平线一段式端到端方案(HSD)的两篇核心文章: DiffusionDrive + ResAD。
DiffusionDrive给读者们梳理了整体pipeline,ResAD则着重于性能提升的关键:轨迹残差设计。两篇文章都很精彩,也感谢地平线的分享,给从业者带来很多启发。
DiffusionDrive
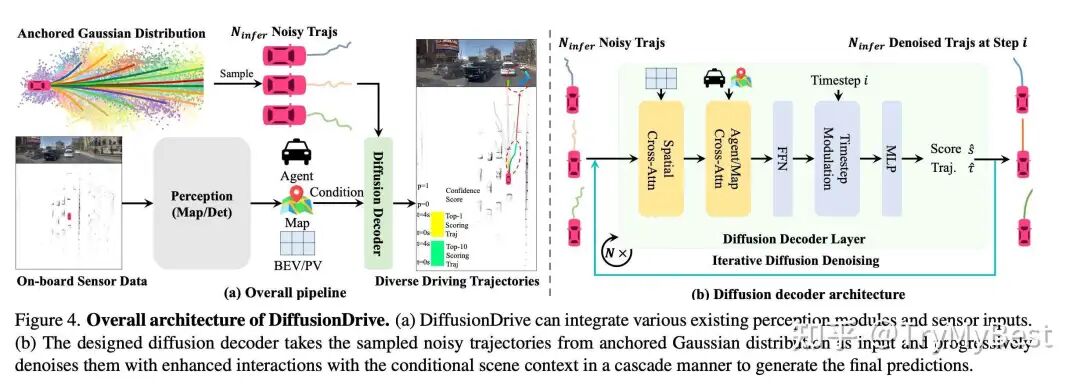
图1: diffisonDrive整体架构
DiffusionDrive的整体架构如图1,可以拆成三部分:1. 感知信息 2.导航信息 3.轨迹生成
感知信息
感知信息本文没有过多着墨,主要是障碍物(动态/静态)、红绿灯、地图元素(车道线/roadmarker/特殊车道信息如可变车道)、可行驶区域(freespace/occ)。从端到端的角度来说,核心就是将感知任务的信息表征传递给planner任务。二段式时,是结构化的障碍物、车道线、红绿灯、可行驶区域等等感知信息。一段式时,纯dense感知方案可以是感知的Bev feature map;纯sparse方案,可以是每个query的instance feature,玩法很多,一般都会结合公司现有的技术栈来适配。我挺推荐Sparse4D和VAD两个系列,对障碍物和map元素的建模我觉得很干净,也容易复现。
导航信息
从交付角度来说,不跟导航代价其实很大,比如高速不下匝道,几乎是不能被接受的。本文没有过多着墨,但实践过程中怎么让模型可以不走错路,是非常有挑战的工作。比如上海就是典型的导航难度大的城市,路口车道多且设计多样,高架上短时多次多匝道,可变和潮汐车道。根据导航信息的平台不同、导航信息丰富度不同、定位能力不同,算法的设计也千差万别,需要从实践过程中积累经验。
轨迹生成
本文核心想说的就是轨迹生成部分,所谓“Truncated Diffusion”。文章指出人类驾驶行为并不是随机分布的,具备fix patterns。从这个观察出发,文中
从训练集中K-Means出N个轨迹序列,描述常见的人类驾驶行为
训练过程中,对这N个轨迹的加噪比较弱,对应的你去噪的step也不用很多
训练时和真值轨迹最接近的anchor计算denoising轨迹的loss,每个anchor都预测存在性
这么做的好处很多,可以降低训练收敛的难度且推理时去噪的次数需求更少(指和没有这么做的那些算法,对DDIM的去噪次数的需求,现在也有很多生成算法在研究更少的推理去噪次数)。此外,上车时可以根据你的算法来设计anchor的个数,降低推理成本。
轨迹生成和感知信息以及导航信息的交互文中也没展开说,diffusion中加入条件控制的文章很多,比如Classifier-Free Guidance就蛮好的,比较干净,更多的玩法读者可以自行探究。
Comment
本文的核心贡献就在其anchor based的轨迹生成,训练难度降低,推理实时性高,是很好的idea。但是我在读的时候就有一个困惑,时序上轨迹的稳定性怎么保证?文章也没有谈到system的时序模块(这显然是需要的)。
ResAD
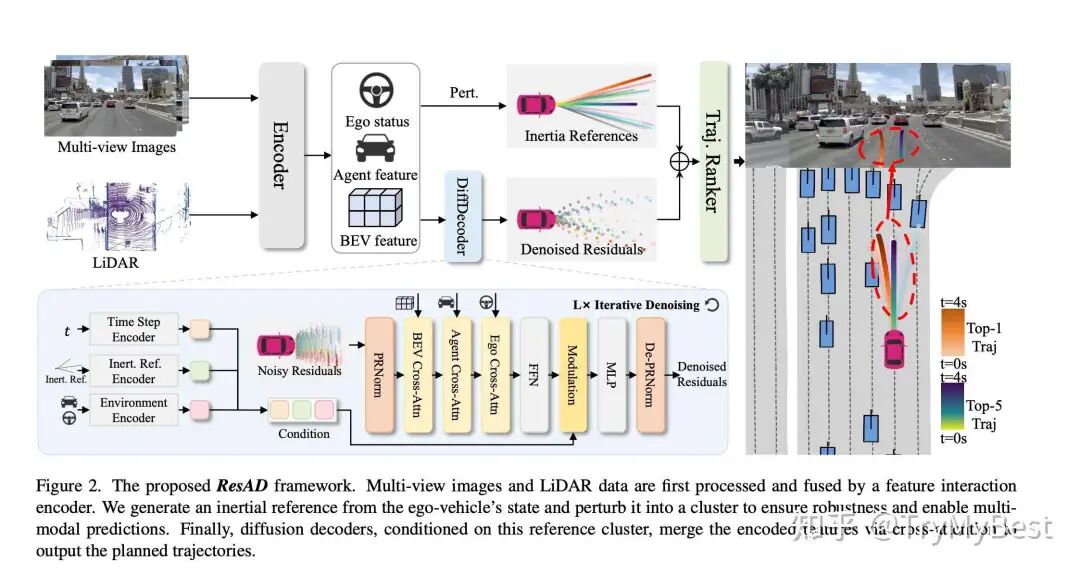
图2:ResAD整体架构
残差监督
我觉得本文最有意思的部分就是这个残差设计,本文没有直接去生成未来轨迹,而是预测未来轨迹和惯性外推下的惯性未来轨迹的残差。
残差正则
但显然距离当前时刻的间隔越远,残差会越大,所以需要正则化。对于时序上的残差们,对其进行正则化得到:
其中用来压缩区间
文中这张图对残差的作用表述的非常清楚:
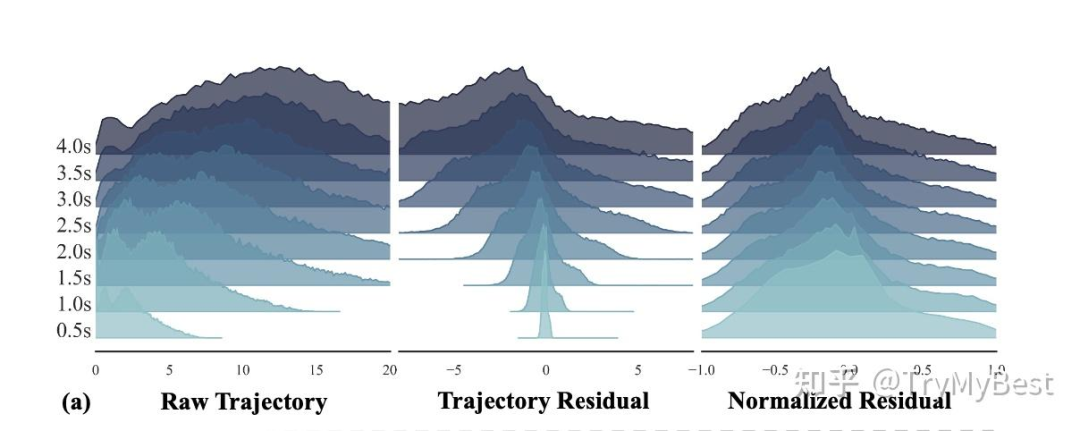
图3:轨迹和轨迹残差的分布对比
可以看到不管未来不同时刻的轨迹分布一致的多,而这种一致性是非常有好处的。Loss上,轨迹的预测误差不会再被距离自车比较远的点给拉住;学习难度上,不平衡的分布下模型更容易偷懒。
惯性参考扰动
考虑到其残差的设计,其生成过程中噪声的扰动也有所不同,其噪声直接作用在了初始速度上,通过控制噪声在lat和lon方向上的不同大小,调整横纵向不同的学习难度和关注程度。所以有
会设置K种噪声,infer时可以根据需求(算力大小,下游对多模的依赖程度)设置不同的。
轨迹Ranker
ResAD提到了他们的轨迹selector,将topk的轨迹预测编码当作Q,环境信息(同diffusionDrive中感知和导航信息)当作K,V,过transformer;额外的将ego status的embedding也加进来,去预测metric scores。预测多少metric可以自己设计。
Comment
轨迹Ranker算是部分解答了我DiffusionDrive轨迹稳定性的疑惑,引入多个metric scores,也给了下游更多发挥的空间,但我觉得可以进一步设计成时序的,提升选择的稳定性。
小结
总的来说,地平线的这两篇文章都非常出色,也给从业者带来了很多思考和引导,期待更多更好的文章,也期待更优秀的产品。
作者 | TryMyBest 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1983151280315716691

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)