
Summary
一句话讲清楚YOLO26在NPU平台部署的差异: 基于v8后处理, 删完DFL计算, 删NMS计算, 剩下的就是YOLO26的后处理!
YOLO26后处理压力更小, v8系的解耦头后处理压力已经是v5的三分之一, 26更是删除了DFL和NMS的计算, 后处理压力进一步减小. 这种改变对密集目标更友好, 更能balance部署方案的BPU吞吐量和算上CPU后处理时间的算法端到端延迟. 这可能是CPU速度提升43%的数据的关键部分, 不过在NPU平台部署体现在了后处理的速度更快.
带NMS的后处理精度更高, 无论是ultralytics的GPU上还是端侧NPU上, 由于CPU后处理NMS逻辑为BBox分数预先筛选, 参与NMS的可能只有100个框, 其实NMS时间并不算太长.
在RDK S100P上, YOLO26在BPU部分的吞吐量与YOLO11持平, 优于纯Transformer结构的YOLO12, 这符合预期, 因为YOLO12本身就是堆Transformer计算量堆上来的.
在RDK S100P上, YOLO26精度好于YOLO11, 尤其是YOLO26小目标检测的定点精度保持断崖领先其他代YOLO. 虽然YOLO12精度比YOLO26略高, 但是纯Transformer的YOLO12计算代价确实太高了.
说明
本文类型为post, 技术报告类, 并非入门教程. 文中所有观点仅代表个人, 仅供YOLO爱好者交流.
本文所有输入采用HWC-RGB888的输入, 同时带非查表实现的除以255的BPU处理加速, 不使用nv12输入.
- 其他YOLO系列在BPU上的部署参考 RDK YOLO All-in-One: CSDN Link
- 请注意, Ultralytics YOLO采用AGPL-3.0协议, 请遵循相关协议约定使用, 更多请参考: https://www.ultralytics.com/license
Introduction to YOLO26

Ultralytics YOLO26 是 YOLO 系列实时对象检测器的最新演进,从头开始专为边缘和低功耗设备而设计。它引入了简化的设计,消除了不必要的复杂性,同时集成了有针对性的创新,以实现更快、更轻、更易于访问的部署.
YOLO26 的架构遵循的核心原则:
简洁性: YOLO26是一个原生的端到端模型,直接生成预测结果,无需非极大值抑制(NMS)。通过消除这一后处理步骤,推理变得更快、更轻量,并且更容易部署到实际系统中。这种突破性方法最初由清华大学的王傲在YOLOv10中开创,并在YOLO26中得到了进一步发展.
部署效率: 端到端设计消除了管道的整个阶段,从而大大简化了集成,减少了延迟,并使部署在各种环境中更加稳健.
训练创新:YOLO26 引入了MuSGD 优化器,它是 SGD 和 Muon 的混合体——灵感来源于 Moonshot AI 在 LLM 训练中 Kimi K2 的突破。该优化器带来了增强的稳定性和更快的收敛,将语言模型中的优化进展转移到计算机视觉领域.
任务特定优化:YOLO26 针对专业任务引入了有针对性的改进,包括用于 Segmentation 的语义分割损失和多尺度原型模块,用于高精度 姿势估计 的残差对数似然估计 (RLE),以及通过角度损失优化解码以解决 旋转框检测 中的边界问题.
这些创新共同提供了一个模型系列,该模型系列在小对象上实现了更高的精度,提供了无缝部署,并且在 CPU 上的运行速度提高了 43% — 使 YOLO26 成为迄今为止资源受限环境中最实用和可部署的 YOLO 模型之一.
Introduction to RDK S100P

算法, 工具链, Runtime的权衡
DataFlows
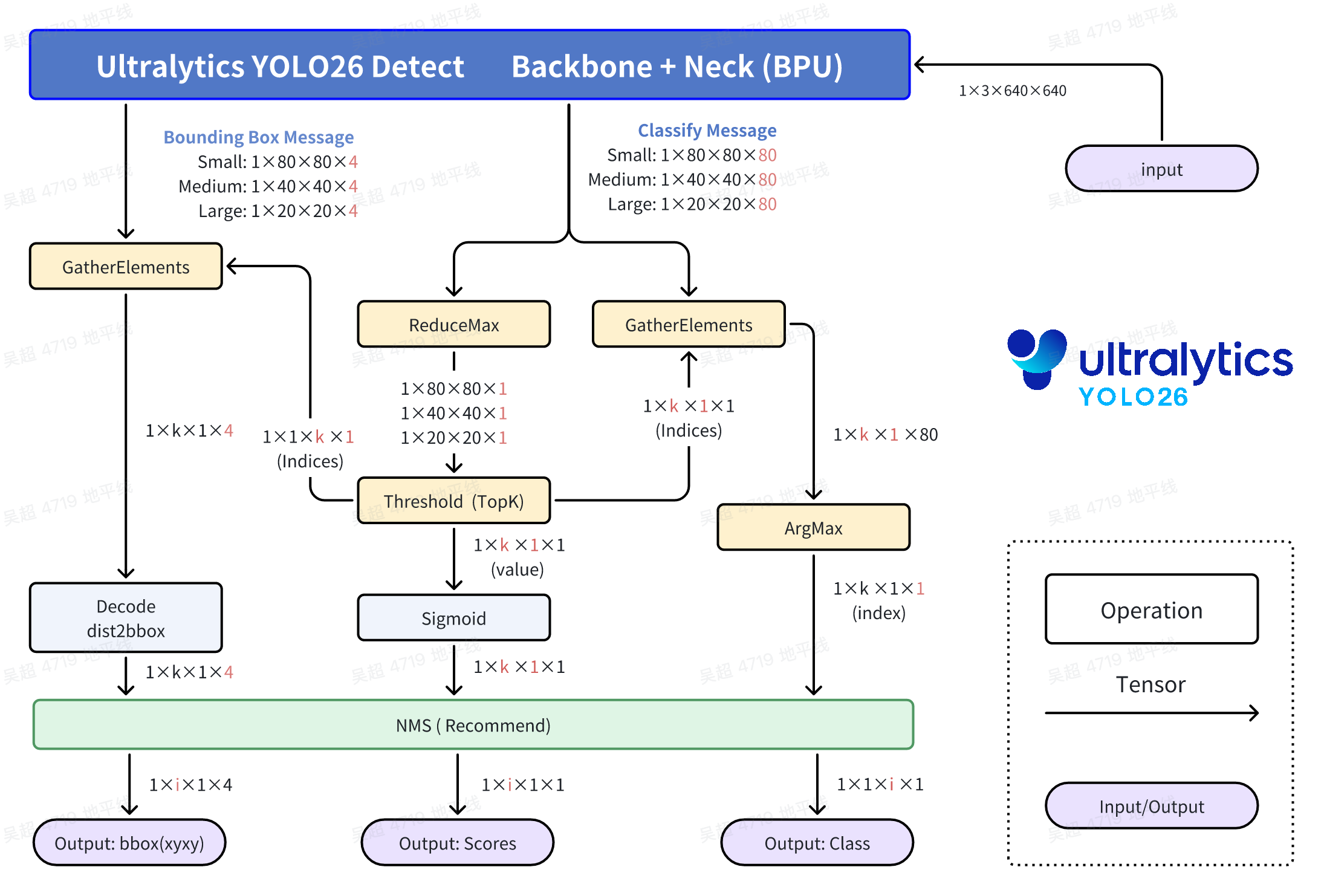
这里对输出头的修改依然是沿用v8系风格, 将bbox和cls的头分开输出, 同时加入NCHW2NHWC的Layout Transpose算子, 使得CPU在沿着C通道做后处理的时候, 每个Grid Cell的数据在内存中是连续的, 提高CPU计算Cache命中率.
classify头: 高性能计算的核心结构与v8系列一致, 首先是利用Sigmoid函数单调性找最大值和比较分数是否合格, 然后分数不合格的Bounding Box直接Contiue或不去Select, 节约Bounding Box的解码计算的计算量.
Bounding Box头: v8从最后一个带实权的卷积算子出来后, ltrb有16个数字, 按照DFL结构规则计算得到ltrb信息, 26从卷积算子出来的数据就直接是ltrb信息了, 这节约了一大部分计算量, 同时也避免了一大部分Vector计算, 是更加纯净的Tensor计算. 往下ltrb通过对应的Grid和stride, 计算得到最终的Bounding Box的xyxy坐标.
关于NMS: 这里可以不使用NMS, 并没有出现那么严重的检测框重复和重叠的现象. 但是从COCO2017数据集验证集的5000张照片的全量精度测试结果来看, 带NMS的计算精度更高.
BenchMark
Performance
Device | Model | Size(Pixels) | Classes | BPU Task Latency / BPU Throughput (Threads) | CPU Latency (Single Core) | params(M) | FLOPs(B) |
|---|---|---|---|---|---|---|---|
S100P | YOLO26n Detect | 640×640 | 80 | 1.31 ms / 727.37 FPS (1 thread ) 2.02 ms / 962.93 FPS (2 threads) | 0.5 ms | 2.4 M | 5.4 M |
S100P | YOLO26s Detect | 640×640 | 80 | 2.12 ms / 458.86 FPS (1 thread ) 3.58 ms / 549.12 FPS (2 threads) | 0.5 ms | 9.5 M | 20.7 M |
S100P | YOLO26m Detect | 640×640 | 80 | 4.16 ms / 236.86 FPS (1 thread ) 7.63 ms / 259.35 FPS (2 threads) | 0.5 ms | 20.4 M | 68.2 M |
S100P | YOLO26l Detect | 640×640 | 80 | 4.95 ms / 199.54 FPS (1 thread ) 9.20 ms / 215.27 FPS (2 threads) | 0.5 ms | 24.8 M | 86.4 M |
S100P | YOLO26x Detect | 640×640 | 80 | 8.98 ms / 110.47 FPS (1 thread ) 17.19 ms / 115.62 FPS (2 threads) | 0.5 ms | 55.7 M | 193.9 M |
S100P | YOLO12n Detect | 640×640 | 80 | 1.88 ms / 513.70 FPS (1 thread ) 3.07 ms / 634.97 FPS (2 threads) | 2.0 ms | 2.6 M | 7.7 M |
S100P | YOLO12s Detect | 640×640 | 80 | 3.10 ms / 315.83 FPS (1 thread ) 5.50 ms / 357.85 FPS (2 threads) | 2.0 ms | 9.3 M | 21.4 M |
S100P | YOLO12m Detect | 640×640 | 80 | 6.47 ms / 152.80 FPS (1 thread ) 12.18 ms / 162.62 FPS (2 threads) | 2.0 ms | 20.2 M | 67.5 M |
S100P | YOLO12l Detect | 640×640 | 80 | 10.23 ms / 97.01 FPS (1 thread ) 19.67 ms / 101.04 FPS (2 threads) | 2.0 ms | 26.4 M | 88.9 M |
S100P | YOLO12x Detect | 640×640 | 80 | 17.05 ms / 58.34 FPS (1 thread ) 33.21 ms / 59.92 FPS (2 threads) | 2.0 ms | 59.1 M | 199.0 M |
S100P | YOLO11n Detect | 640×640 | 80 | 1.16 ms / 816.50 FPS (1 thread ) 1.66 ms / 1155.65 FPS (2 threads) | 2.0 ms | 2.6 M | 6.5 M |
S100P | YOLO11s Detect | 640×640 | 80 | 1.81 ms / 533.50 FPS (1 thread ) 2.98 ms / 656.31 FPS (2 threads) | 2.0 ms | 9.4 M | 21.5 M |
S100P | YOLO11m Detect | 640×640 | 80 | 3.90 ms / 252.02 FPS (1 thread ) 7.10 ms / 278.36 FPS (2 threads) | 2.0 ms | 20.1 M | 68.0 M |
S100P | YOLO11l Detect | 640×640 | 80 | 4.73 ms / 208.61 FPS (1 thread ) 8.75 ms / 225.99 FPS (2 threads) | 2.0 ms | 25.3 M | 86.9 M |
S100P | YOLO11x Detect | 640×640 | 80 | 8.84 ms / 112.05 FPS (1 thread ) 16.92 ms / 117.39 FPS (2 threads) | 2.0 ms | 56.9 M | 194.9 M |
Performance Test Instructions
- Device列表示测试的平台, S100P表示RDK S100P, S100表示RDK S100, X5表示RDK X5 (Module).
- Model列表示测试的模型, 与本文Support Models章节所列模型是对应关系.
- Size(Pixels)列表示的是模型的算法分辨率, 是导出ONNX模型的输入分辨率, 其他分辨率的图像一般是经过前处理缩放到此分辨率, 再送入网络推理.
- Classes列表示的是模型的检测目标数量, 这里使用的都是Ultralytics YOLO基于COCO2017数据集或者ImageNet-1k数据集训练出来的权重, 类别数量与对应的数据集的类别数量是一致的.
- BPU Task Latency / BPU Throughput (Threads)列列举了BPU延迟与BPU吞吐量的情况.
单线程延迟为单帧,单线程,单BPU核心的延迟,BPU推理一个任务最理想的情况.
多线程帧率为多个线程同时向BPU塞任务, 每个BPU核心可以处理多个线程的任务, 一般工程中2个线程可以控制单帧延迟较小,同时吃满所有BPU到100%,在吞吐量(FPS)和帧延迟间得到一个较好的平衡.
表格中一般记录到吞吐量不再随线程数明显增加的数据.
BPU延迟和BPU吞吐量使用以下命令在板端实验, hrt_model_exec工具由OE包提供, 其源码在OE包的package/board/hrt_model_exec/src目录下.由于实验的条件不同, 复现的的结果可能不同, 这里统一参照本文的Platform Details中的设备状态, 在平台状态最佳时进行实验.
hrt_model_exec工具的性能实验中, 充分考虑了缓存预热, 多线程程序设计等性能测试的内容, 测量的时间为用户程序向BPU提交BPU任务到等待BPU任务结束的时间。
在流式数据推理时, 输入输出内存可以开辟一次, 反复使用, 请不要将开辟和回收内存的时间纳入推理时间, 也不要在流式数据推理中反复开辟和回收内存, 这是不科学的程序设计方法. - CPU Latency (Single Core)指的是后处理时间, 目前对后处理有做性能优化, 后处理时间与有效目标的个数正相关, 这里的后处理时间一般是目标图片中有效目标的个数小于100时的性能数据. Python和C/C++的后处理时间会有一点差距, 但是由于Python后处理程序基本也是numpy深度优化了, 所以两者差距并不是很大.
- params(M)和FLOPs(B)是原始浮点模型的参数量和计算量, 使用Ultralytics YOLO软件包在加载完pt模型后, 使用YOLO.export方法时日志中打印的浮点模型参数量和计算量信息. 由于最终生成的BPU定点模型的参数量和计算量与模型结构优化, 图优化, 编译器优化有关系, 与浮点模型的参数量和计算量正相关但是不一定成正比例, 所以这里统一记录浮点计算量为参考.
Accuracy
Device | Model | Accuracy bbox-all mAP@.50:.95 FP32 / BPU Python | Accuracy bbox-small mAP@.50:.95 FP32 / BPU Python | Accuracy bbox-medium mAP@.50:.95 FP32 / BPU Python | Accuracy bbox-large mAP@.50:.95 FP32 / BPU Python |
|---|---|---|---|---|---|
S100P | YOLO26n Detect(e2e) | 0.319 / 0.289 (90.6 %) | 0.107 / 0.087 (81.7 %) | 0.349 / 0.313 (89.6 %) | 0.508 / 0.460 (90.7 %) |
S100P | YOLO26s Detect(e2e) | 0.395 / 0.363 (92.0 %) | 0.183 / 0.172 (94.1 %) | 0.440 / 0.403 (91.6 %) | 0.583 / 0.525 (90.2 %) |
S100P | YOLO26m Detect(e2e) | 0.442 / 0.406 (91.8 %) | 0.242 / 0.216 (89.4 %) | 0.489 / 0.442 (90.4 %) | 0.629 / 0.584 (92.8 %) |
S100P | YOLO26l Detect(e2e) | 0.456 / 0.396 (87.0 %) | 0.260 / 0.225 (86.6 %) | 0.499 / 0.430 (86.3 %) | 0.627 / 0.560 (89.3 %) |
S100P | YOLO26x Detect(e2e) | 0.484 / 0.441 (91.0 %) | 0.292 / 0.269 (92.2 %) | 0.528 / 0.470 (89.0 %) | 0.669 / 0.630 (94.2 %) |
S100P | YOLO26n Detect(nms) | 0.319 / 0.290 (91.0 %) | 0.107 / 0.087 (81.7 %) | 0.349 / 0.313 (89.8 %) | 0.508 / 0.463 (91.1 %) |
S100P | YOLO26s Detect(nms) | 0.395 / 0.367 (93.0 %) | 0.183 / 0.174 (94.8 %) | 0.440 / 0.410 (93.1 %) | 0.583 / 0.530 (91.0 %) |
S100P | YOLO26m Detect(nms) | 0.442 / 0.421 (95.2 %) | 0.242 / 0.224 (92.6 %) | 0.489 / 0.460 (94.0 %) | 0.629 / 0.603 (95.8 %) |
S100P | YOLO26l Detect(nms) | 0.456 / 0.437 (96.0 %) | 0.260 / 0.234 (89.8 %) | 0.499 / 0.484 (97.1 %) | 0.627 / 0.609 (97.0 %) |
S100P | YOLO26x Detect(nms) | 0.484 / 0.466 (96.2 %) | 0.292 / 0.271 (92.8 %) | 0.528 / 0.502 (95.1 %) | 0.669 / 0.654 (97.8 %) |
S100P | YOLO12n Detect(nv12) | 0.338 / 0.313 (92.4 %) | 0.128 / 0.095 (74.0 %) | 0.374 / 0.342 (91.4 %) | 0.524 / 0.515 (98.3 %) |
S100P | YOLO12s Detect(nv12) | 0.403 / 0.380 (94.2 %) | 0.201 / 0.152 (75.5 %) | 0.450 / 0.432 (95.9 %) | 0.602 / 0.581 (96.5 %) |
S100P | YOLO12m Detect(nv12) | 0.452 / 0.423 (93.7 %) | 0.251 / 0.204 (81.3 %) | 0.509 / 0.489 (96.0 %) | 0.638 / 0.616 (96.5 %) |
S100P | YOLO12l Detect(nv12) | 0.463 / 0.429 (92.8 %) | 0.268 / 0.211 (78.6 %) | 0.522 / 0.492 (94.3 %) | 0.646 / 0.630 (97.7 %) |
S100P | YOLO12x Detect(nv12) | 0.475 / 0.440 (92.7 %) | 0.276 / 0.222 (80.3 %) | 0.536 / 0.509 (94.9 %) | 0.659 / 0.627 (95.1 %) |
S100P | YOLO11n Detect(nv12) | 0.327 / 0.306 (93.9 %) | 0.130 / 0.104 (80.0 %) | 0.357 / 0.340 (95.2 %) | 0.511 / 0.500 (97.8 %) |
S100P | YOLO11s Detect(nv12) | 0.400 / 0.380 (95.0 %) | 0.198 / 0.166 (83.9 %) | 0.445 / 0.427 (96.1 %) | 0.587 / 0.579 (98.6 %) |
S100P | YOLO11m Detect(nv12) | 0.444 / 0.417 (94.0 %) | 0.247 / 0.214 (87.0 %) | 0.497 / 0.478 (96.1 %) | 0.627 / 0.599 (95.6 %) |
S100P | YOLO11l Detect(nv12) | 0.460 / 0.434 (94.5 %) | 0.267 / 0.227 (85.2 %) | 0.520 / 0.498 (95.9 %) | 0.638 / 0.611 (95.8 %) |
S100P | YOLO11x Detect(nv12) | 0.474 / 0.446 (94.0 %) | 0.283 / 0.240 (84.7 %) | 0.529 / 0.506 (95.6 %) | 0.652 / 0.627 (96.1 %) |
Accuracy Test Instructions
- Device列和Model列含义与Performance Test Instructions章节的含义相同.
- 精度数据使用微软官方的无修改的pycocotools库进行计算, 目标检测(Obeject Detection)任务的测评模式为iouType="bbox", 和实例分割(Instance Segmentation)任务的测评模式为iouType="bbox"和iouType="segm", 人体关键点估计的测评模式为iouType="keypoints".
Accuracy bbox-all mAP@.50:.95 取自 Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ].
Accuracy bbox-small mAP@.50:.95 取自 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ].
Accuracy bbox-medium mAP@.50:.95 取自 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ].
Accuracy bbox-large mAP@.50:.95 取自 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ]. AP 更关注“质量”:既要找到目标(recall), 又要框得准, 类别对(precision), AR 更关注“数量”: 只要框住就算,不惩罚误检. 一个模型可以有高 AR 但低 AP, 比如疯狂输出大量低质量框, 找得全但不准. 也可以有高 AP 但低 AR, 比如只输出高置信度结果, 很准但漏很多. 这里取的均为AP指标来衡量模型的精度.
- 测试数据均使用COCO2017数据集的val验证集的5000张照片, 在板端直接推理, dump保存为json文件, 送入第三方测试工具pycocotools库进行计算, 分数的阈值为0.25, nms的阈值为0.7.
pycocotools计算的精度比ultralytics计算的精度会低一些是正常现象, 主要原因是在计算AP曲线下面积时, pycocotools是取矩形面积, ultralytics是取梯形面积, 我们主要是关注同样的一套计算方式去测试定点模型和浮点模型的精度, 从而来评估量化过程中的精度损失.
- 分类任务使用的数据集为ImageNet-1k, 使用TOP1和TOP5两个指标来评估量化过程中的精度损失.
BPU模型在量化NCHW-RGB888输入转换为YUV420SP(nv12)输入后, 也会有一部分精度损失, 这是由于色彩空间转化导致的, 在训练时加入这种色彩空间转化的损失可以避免这种精度损失.
- Python接口和C/C接口的精度结果有细微差异, 主要在于Python和C/C的一些数据结构进行memcpy和转化的过程中, 对浮点数的处理方式不同, 导致的细微差异.
本表格是使用PTQ(训练后量化)使用50张图片进行校准和编译的结果, 用于模拟普通开发者第一次直接编译的精度情况, 并没有进行精度调优或者QAT(量化感知训练), 满足常规使用验证需求, 不代表精度上限.
算法层修改参考
Export程序参考
OpenExplore步骤参考
Runtime程序参考
注: 这是参考程序, 不承诺一键运行, 如果您发现有可以改进的地方欢迎在文末评论.
CPP (CmakeLists.txt)
CPP (with NMS)
CPP (without NMS)
Python (with NMS)
Python (without NMS)
Runtime依赖编译参考
创建Python 3.12的环境
源码编译pyCauchyKesai接口
注: 您可以使用任何您喜欢的接口, 但是我喜欢用这个接口.
安装


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)