
1. 引言
在使用地平线算法工具链进行量化部署时,遇到两种FuseMode:OnlyBN、BNAddReLu。

引起思考,融合的目的是什么?融合怎么做到的?是等效的吗?
神经网络在推理端(inference)经常通过运算符融合(operator fusion)来降低计算量、减少访存开销、加速执行。典型融合模式包括:
Conv + BatchNorm
Conv + BatchNorm + Add(残差) + ReLU
2. Conv + BN 融合原理
在推理阶段(evaluation mode),BatchNorm2d 的计算本质为:
其中:
mean、var 为均值和方差
gamma、beta 为可学习参数
下面来看BN与卷积合并的数学推导,常规卷积输出:
BN 作用于 z:
展开后可等效为新的卷积:
因此,Conv+BN 可以直接替换为一个新的 Conv,BN 不再需要执行。
这样的融合能带来什么收益呢?
减少一次 BN 访存,降低内存带宽压力
减少一次算子调用,加速推理调度
便于量化,避免 BN 对数值范围的影响
3. Conv+BN+Add+ReLU 融合原理
如上节所述:Conv+BN融合为 Conv'。
在量化部署时,Add(通常来自残差)需要保证两个输入具有一致量化 scale,因此框架在 FX 层面会识别以下模式:
并可能重调 scale 以便后续融合(具体依赖量化模式 QATMode),例如在 INT8 量化时:
若 Conv' 输出 scale = S1
Add 需要输入两个 scale 对齐(S1 与 S2)
框架会插入或调整 scale,使整个链路在同一量化域中执行。这样才能在同一个硬件 kernel 内完成 Add 和 ReLU(见后文)。
ReLU 可以直接作用在 Add 的输出上而不改变数值关系,因此 Add+ReLU 也可以合并为一个 fused activation:
在量化推理中,这意味着 Add 的输出可直接进入 ReLU 的裁剪范围,减少中间量化/反量化开销。
举个例子:
输出为:
部署框架会识别其中:Conv+BN 融合,Add 与 ReLU 形成连续子图,可进一步融合。
看到这儿,不知大家是否有这样的疑问,conv+bn可根据等效公式融合为一个算子,但后续的add/relu,明显不能再这样了,那怎么操作的呢?目的又是什么呢?
4. 拓展解读
“Conv+BN+Add+ReLU 融合”其实不是把所有算子物理上变成一个算子,而是:
Conv+BN → 融合为 Conv'(数学等价)
Conv' + Add → 融合为一个更高效的“卷积+残差加法”算子(计算图优化)
Add + ReLU → 融合为“带激活的残差”算子(计算图优化)
真正“从数学上消失”的只有 BN;Add 和 ReLU 只是算子合并(operator folding)。
4.1 conv+add“融合”
conv+add的“融合”不是代数消去,而是 操作符流水线融合(Operator Fusion)
典型残差块:
Add 这一步本身是逐元素加法,不涉及权重或参数,它的数学形式:Add(a, b) = a + b,并不会改变 Conv' 的结构,也不能被代数合并成一个新的卷积。但是在推理框架(TensorRT、ONNXRuntime,OpenExplorer)中:Conv' 的输出内存可以作为 Add 的输入,直接在同一 Kernel 中累加,不需要创建新的中间张量。硬件中可以这样执行:
这样可以节省:
一次内存写回(Conv 输出)
一次内存读出(Add 输入 a-tmp)
一次内存写回(Add 输出)
因此虽然数学类型上没法合并,但计算图优化上能“内联到一个 kernel 中”。(前端可不做,可以量化结束放到编译时做)
4.2 add+ReLu“融合”
Add 和 ReLU 的数学形式:y = relu(a + b),ReLU 只是对加法结果做逐元素裁剪:relu(z) = max(z, 0),ReLu不改变 Add 算式的结构,也不能让 Add 消失。但在硬件执行中:在执行加法后的同一个寄存器中直接进行 ReLU,而不需要将 Add 的输出再写回内存。融合后的过程:
节省了:
Add 的输出写回
Add 输出再次读回执行 ReLU
总而言之,BN 可以数学融合到 Conv;Add 和 ReLU 不能数学融合,但可以在硬件执行层面融合到同一个 kernel,避免中间 tensor 读写,从而提升性能。
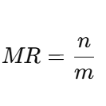
'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)