
本篇论文出发点:
本篇论文的motivation也比较简单,想让端到端轨迹生成模型学习不同的驾驶风格。
比如有些用户就喜欢让自动驾驶更加激进些,有些可能就想让驾驶风格更加保守些,之前的端到端方案只使用了模仿学习,学习专家轨迹,虽然能开,但没有可选的风格。本篇论文就是将大语言模型上比较火的RLHF搬到了自动驾驶领域,来微调轨迹分布,实现输出不同驾驶风格的轨迹。
本文主要贡献:
分析了当前基于模仿学习的端到端轨迹生成方案,只能学习到专家轨迹的平均策略,甚至会受到高频行为引导,一些低频更好的行为没有被关注;同时也指出,当前轨迹的ADE、FDE指标无法评估驾驶风格,本文也提出了一种新的评估方法BOE
提出TrajHF,一种基于人类反馈的生成式轨迹模型微调框架
设计了一套人类偏好建模与评估方式,并做了比较全面的论证
知识点介绍:
- RLHF:RLHF 的全称是 Reinforcement Learning from Human Feedback,即基于人类反馈的强化学习
BOE:Better Or Equal Rate,专门用来评估生成轨迹在驾驶风格层面是否符合人类偏好。不是几何误差。
本文方法介绍:
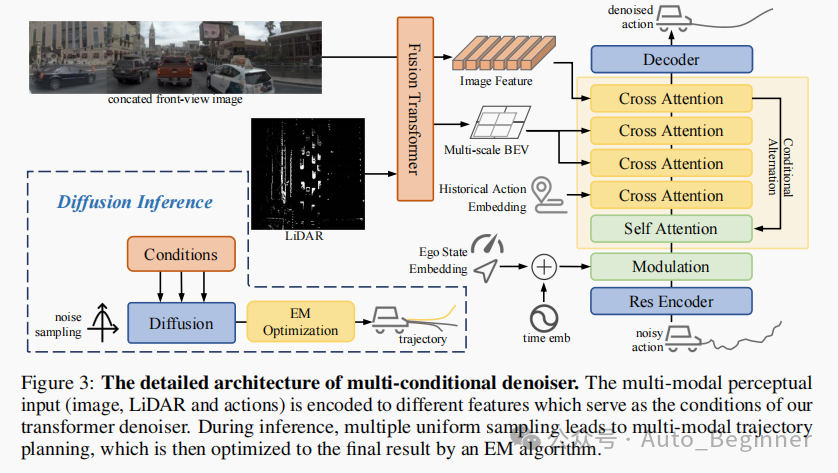
使用扩散模型DDPM为基础的端到端自车轨迹预测(文中好像有说,基于生成式的方案,在多模态上比较有优势,所以使用扩散模型),图像lidar等信息作为条件,预测K条轨迹。模型结构件如Figure3
构造奖励模型学习人类偏好。输入一个场景和一条完整轨迹,输出一个标量分数,表示有多符合人类偏好。训练数据有接管数据标注和端到端模型输出的轨迹构造而成,标注的为正样本,端到端模型输出的为负样本(不符合驾驶风格的)。模型训练loss为Bradley–Terry 排序损失。
驾驶风格对齐(微调),这里有列出算法流程。1)首先对同一观测状态采样k条轨迹,计算奖励值r,通过grpo策略计算组内优势(通过公式8),计算RL loss(通过公式9),选一个参考轨迹,计算BC loss,更新策略。重复以上步骤,直到模型收敛(论文附录中有说,微调20个Epoch,或者刊奖励指标的收敛情况)

总结:
文章中提出的方法还是很不错的,弥补了基于模仿学习的端到端模型在风格控制方面的空白。
但本文方法只使用在生成模型上做RLHF,基于归回的模型就不能使用这种微调策略了吗?应该也是可以的。 不过本文方法文中有提叫DPGRPO,强调了策略模型就是diffusion范式的,可能也是本文的创新点之一吧。
整体方案复杂度还是比较高的,需要用DDPM范式训练端到端轨迹模型,多条件去噪,然后标注奖励模型训练集,训练奖励模型,使用GRPO去做微调,微调的时候需要增加BC模块防止训崩。
文章转载自公众号:自动驾驶新视界

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)