
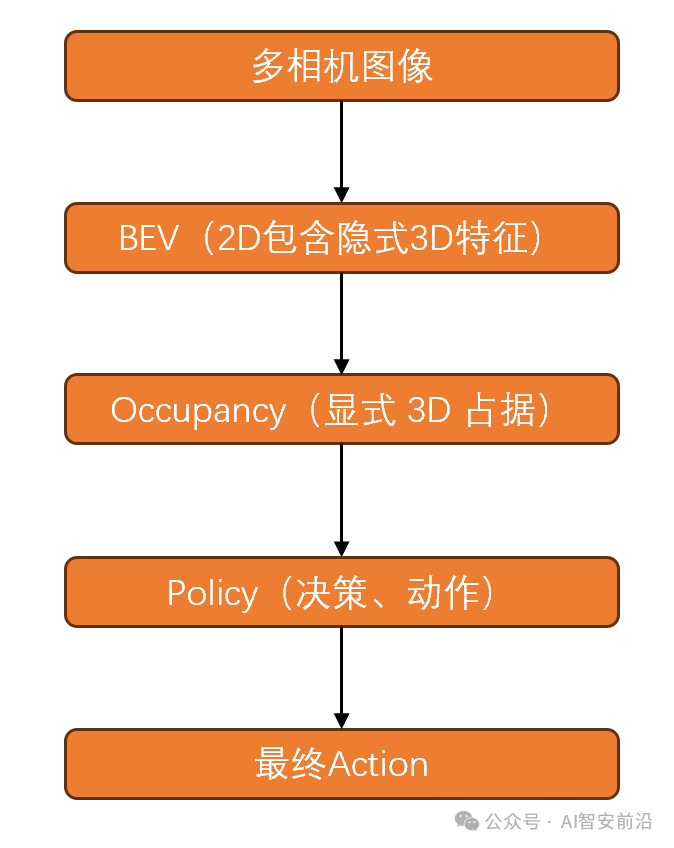
图 1 纯视觉处理全链条
BEV(Bird's Eye View:鸟瞰图)
(一)技术思想
我们还是找一篇相对比较新的BEV论文,该论文由南京大学、上海AI实验室以及香港大学的同学们共同完成,主要讲的就是BEV作为统一特征表示在自动驾驶的感知领域所起到的关键作用。

图 2 BEVFormer总体介绍
- 首次将时空Transformer引入BEV感知,同时融合空间多视角信息与时间序列信息。
- 提出了“BEV查询(BEV Queries)”的范式,通过预定义的网格状查询,直接从多摄像头图像中 “查找并聚合” 时空信息,生成统一的BEV特征图。
- 在nuScenes测试集上取得了56.9% NDS的成绩,超越了此前的纯视觉 SOTA,并与激光雷达基线性能相当,证明了纯视觉方案的巨大潜力。
空间注意力(Spatial Attention)
时间注意力(Temporal Attention)
空间查询包含多个维度的信息,因此采用cross attention用于空间信息的聚合,而时间查询更像是一个时序序列,因此采用了self attention以循环方式融合历史BEV信息。从技术选型上,也非常合理,符合业务实际的场景与特点。
需要强调的是,BEV表征虽然是一张2D的结构化网格图,但是里面保存的并不是像素!而是高维特征向量,这些特征向量里面编码了和自动驾驶相关的所有细节信息,例如这个位置有没有车,有没有障碍物,有车的话,车速多少,方向是什么等等。而且,2D里面还隐含了3D的信息(如图1),用于后续Occupancy的3D还原。
如图3所示,这个统一表征是基础中的基础,除了上面提到的时空统一之外,还包含多传感器统一(论文里纯视觉只有Camera,但是架构是支持雷达的),特别是支持多任务统一,这种“柔性架构”的设计才是最重要的,一个架构直接把3D目标检测和图像分割两大重要任务都完成了。
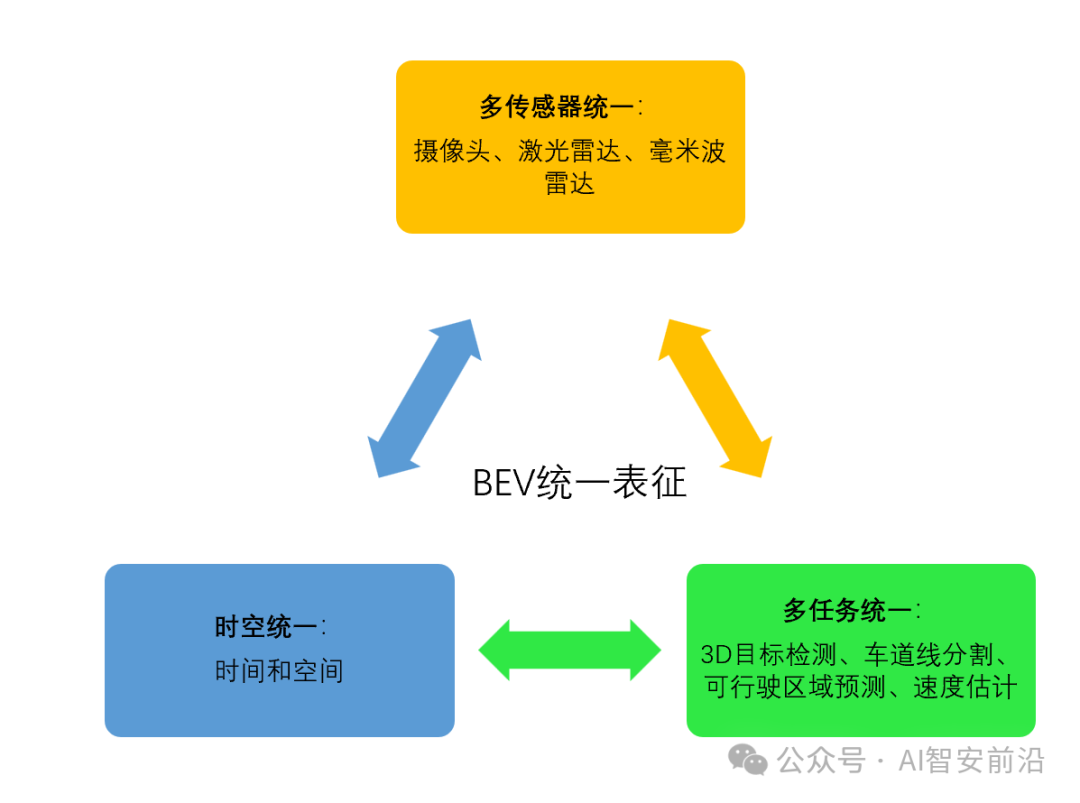
图 3 BEV统一表征
(二)技术架构
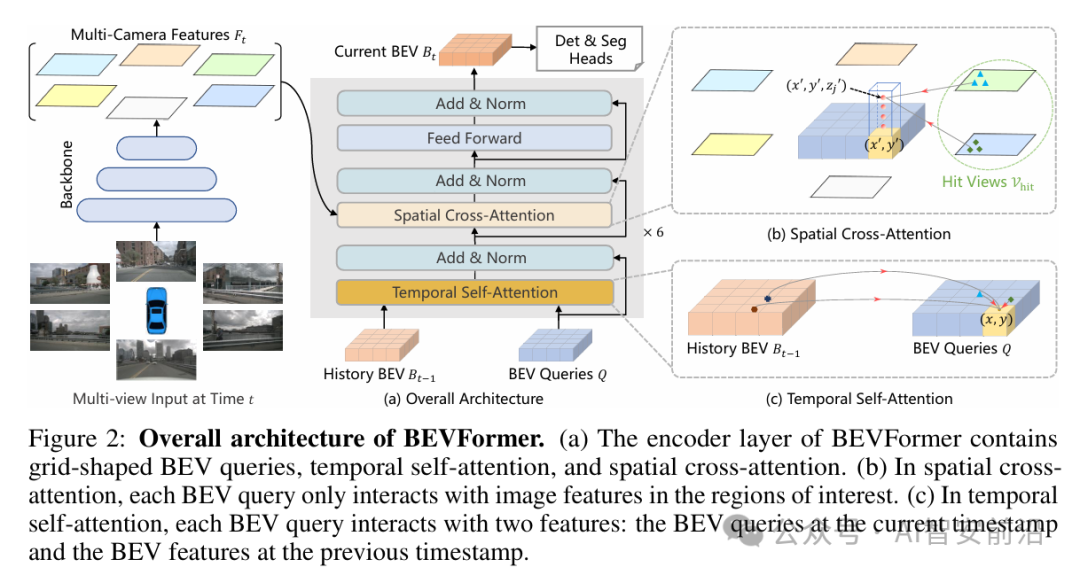
图 4 BEVFormer总体架构
如图4所示,BEVFormer的编码器Encoder层由6个相同的Transformer块堆叠而成,每个块包含两个核心注意力层。整体架构其实还是比较简单易懂的,核心就是利用Encoder学习特征。
输入部分:
多摄像头图像
在时间戳t输入的多视角图像,经Backbone提取为Multi-Camera Features F_t,直接输入到空间交叉注意力。BEV Queries Q
预定义的网格状查询,代表自车周围的BEV空间位置。
History BEV B_{t-1}
上一时刻的BEV特征图,用于时序融合。
编码器层:
除了时间和空间注意力之外,其他都是Transformer标准操作。
Temporal Self-Attention(时间自注意力)
当前BEV查询与上一时刻的BEV特征交互,融合历史信息。
Add & Norm
残差连接与层归一化。
Spatial Cross-Attention(空间交叉注意力)
BEV查询与多摄像头图像特征交互,聚合空间信息。
Add & Norm
残差连接与层归一化。
Feed Forward
前馈网络,进一步变换和学习特征。
Add & Norm
残差连接与层归一化。
输出部分:
- 经过6个编码器层后,输出当前时刻的BEV特征Current BEV B_t。
- 该特征图直接输入到Det & Seg Heads,用于3D检测、地图分割等下游任务。Det就是Detection,即3D检测,Seg就是Segmentation,即地图分割。
核心优化点就是,空间交叉注意力没有对整张图像做全局注意力,而是像 Deformable DETR一样,只在每个BEV查询对应的3D点反投影到图像上的局部区域(ROI)内采样特征,大幅提升效率。
至于Camera-based 3D Perception的BEV路线,核心思路就是先将图像特征转换为BEV特征,再从俯视视角预测3D框。这比直接基于2D图像检测基础上,直接预测3D框的效果要好很多,因为纯2D的检测结果,难以处理遮挡和深度模糊问题。

图 5 BEVFormer优化思想
空间交叉注意力(Spatial Cross-Attention, SCA)
具体公式如下,里面涉及到的核心就是先3D采样(pillar-like query,见图4的右上角图b,就是在柱子的不同高度进行采样),然后将采样点投影到2D去判断坐标是否命中Query区域,即是否hit views,是的话就参与计算。这样,每个BEV查询就只与这些 “命中视图” 交互,大幅减少计算量。
下面的公式的意思就是,对所有命中视图|Vhit|和所有3D参考点Nref的可变形注意力DeformAttn结果取平均,得到最终的SCA空间交叉注意力输出。其实就是一个二层循环,首先遍历所有命中的坐标点|Vhit|集合,然后基于某个坐标点Vi,再去遍历所有采样的参考点i。

BEVFormer设计了时间自注意力TSA,通过融合上一时刻的历史BEV特征,让当前的BEV表征更具时序鲁棒性。具体公式如下,TSA比SCA简单,这里就不再赘述了,感兴趣同学可以去论文里找细节。

有一点需要强调一下,无论是SCA还是TSA都离不开Query,特别是在模型训练的阶段,有了Query的指引(比如“车正前方5米”、“车左侧3米”等),模型才能快速的学习到BEV表征,而且会和Query(坐标)相关联。下图6是BEV表征生成的总流程,我们清晰地看到Query在其中的作用,这和Transformer其实是一样的。
图 6 BEV表征生成的总流程
(三)实验数据
按照惯例,直接贴出论文的实验结果,效果还是非常好的!
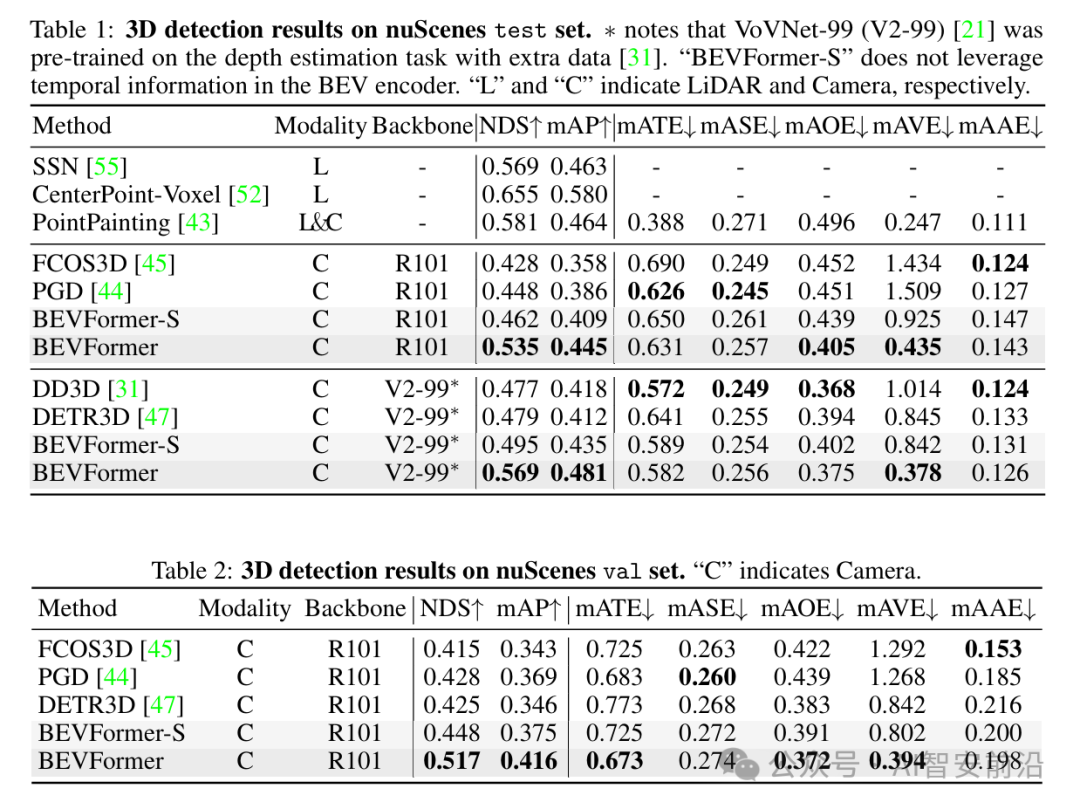
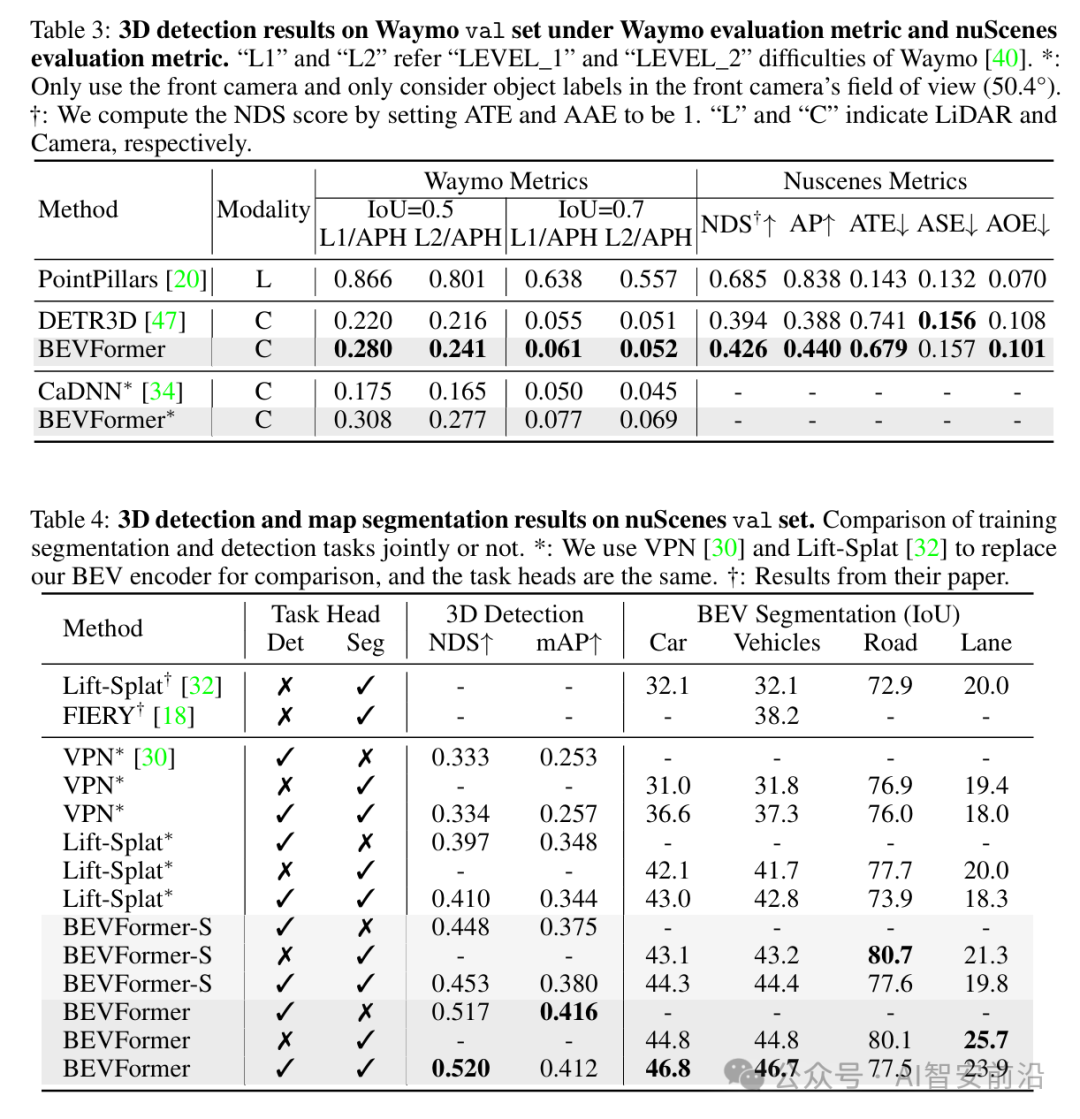
其实我们仔细想想,为什么BEV叫鸟瞰视图,就是它把三维信息通过“俯视”压缩成二维了(类似机械制图的俯视图),也就是把深度信息给融合到2D图片里面了,这为接下来Occupancy占据网络恢复3D空间,提供了丰富的信息来源。
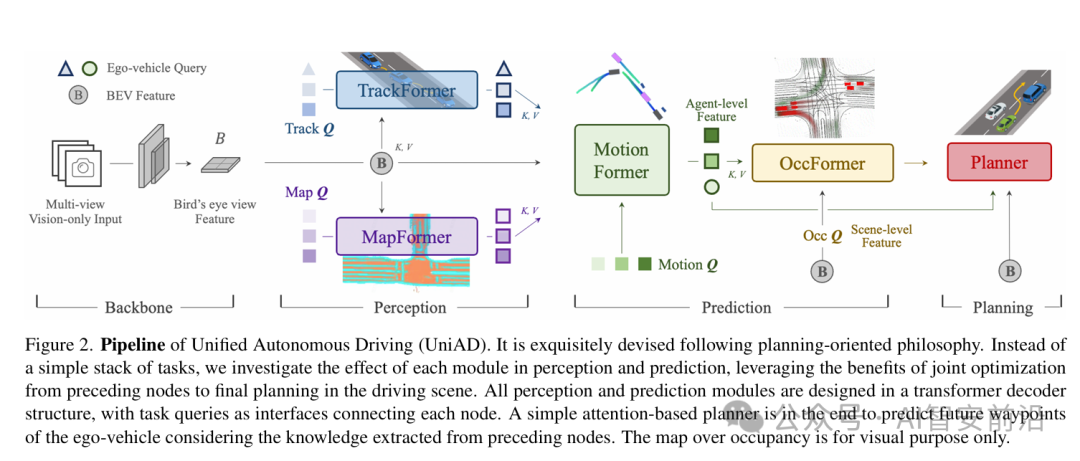
图 7 uniAD:统一自动驾驶全流程
我们今天介绍了BEV,下一次,我们介绍occupancy占据网格。
文章转载自公众号:AI 智安前沿
作者:Michael Yan

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)