
在地平线 J6 平台,当前模型在转换&编译过程中,会生成 quantized.bc 和 hbm 两种定点模型,其中:
hbm 用于板端部署,在 x86 端的指令仿真推理速度比较慢
quantized.bc 主要用于 x86 端的仿真,其数值输出在无 CPU 算子的前提下理论和 hbm 保持 bit 一致
为在服务器端加速量化模型的精度初测,本文分享了测试过程依赖、脚本、实施流程和参考测试结果,供小伙伴们参考~
如何使用GPU运行hbir
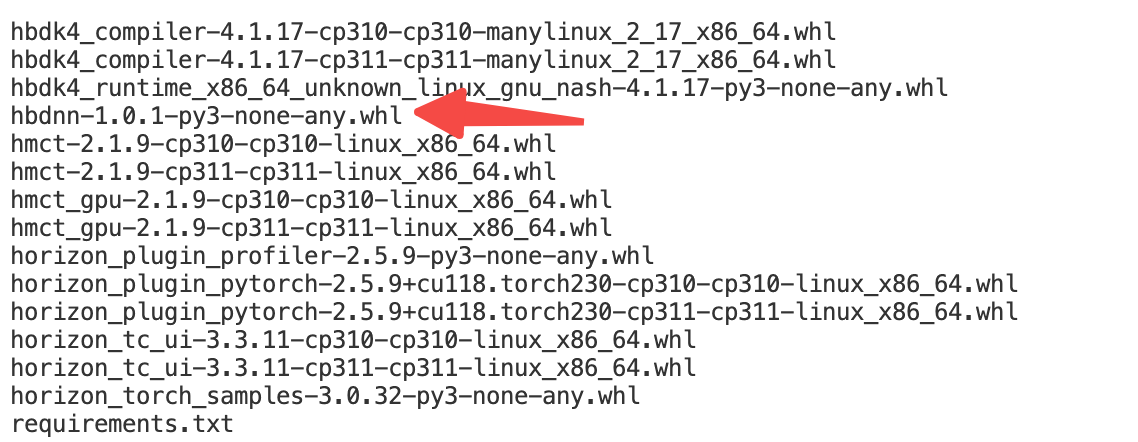
- 安装 libdnn(Docker默认不安装):whl 包位于 OE 包 package/host/ai_toolchain 路径下
- 修改 session 的执行后端:
如何使用CPU运行hbir
当前 hbir 默认 CPU 运行(对应session后端为ONEDNN),其中,每个算子默认使用 16 线程进行加速,也支持通过环境变量进行修改(通常用于限制CPU资源来控制成本):
用户还可以通过多进程的策略进一步提升仿真效率
测试数据获取和测试
测试脚本准备
模型下载 | 验证对比 |
download_model.sh fetch_model_list.sh resolve_ai_benchmark_qat.sh | batch_diff.sh infer_script.py |
测试过程:
下载BC文件(记得修改脚本中的版本信息)
fetch_model_list.sh -> download_models.sh
下载hbm文件
resolve_ai_benchmark_qat.sh
执行性能测试(修改脚本batch_diff.sh中的模型目录,然后执行,其中会自动调用infer_script.py)
- ./batch_diff.sh
func.session.backend设置项可以是:
"":禁用加速,普通的CPU计算。
"HBDNN":使用GPU加速
oneDNN使用cpu的avx512指令集,针对CPU推理过程进行了优化加速,如果CPU支持avx512指令集,应该会有较好的加速效果的。
检查CPU是否支持avx512指令集的方法:执行grep avx512 /proc/cpuinfo如果输出结果中包含avx512说明CPU支持avx512指令集;
注意事项
因版本差异,该测试流程和数据在J6_V3.0.31版本测试,测试结果仅供参考。v3.2.0和v3.2.5版本因策略调整,暂不提供加速功能; V3.7.0加速功能正常使用,用户可以自己测试性能。

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)