
Senna-2:对齐视觉语言模型与端到端驾驶策略以实现一致的决策与规划

论文卡片
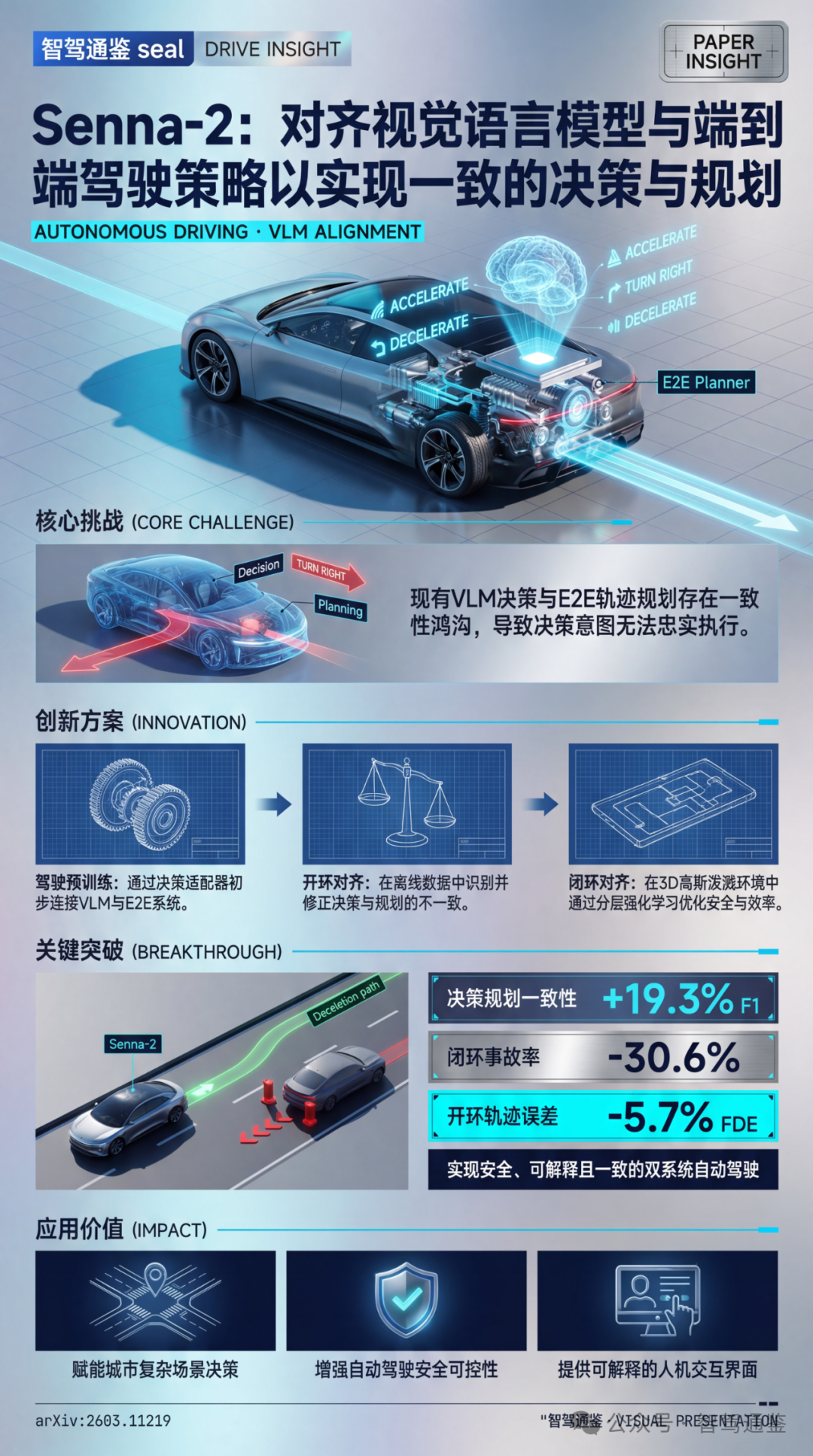
Senna-2通过三阶段训练范式显式对齐视觉语言模型(VLM)与端到端(E2E)驾驶策略,显著提升了决策与规划的一致性,实现了更安全高效的自动驾驶。
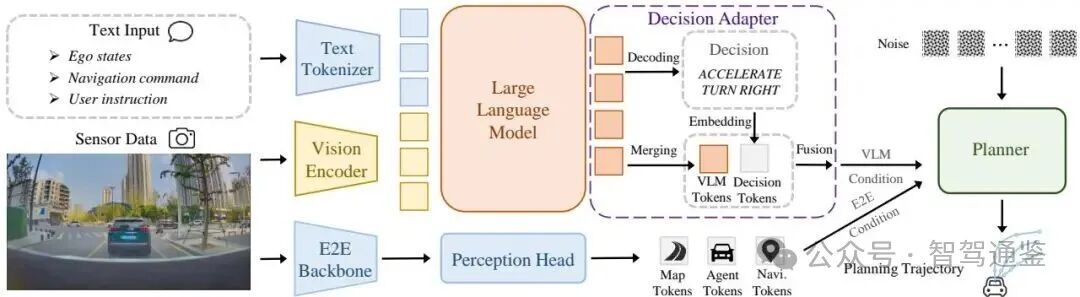
论文框架: Senna-2的整体模型架构。文本和视觉输入由VLM处理以生成高层驾驶决策,这些决策通过Decision Adapter转换为VLM条件嵌入。E2E规划器随后将VLM条件与其自身的端到端特征融合,以生成与高层决策一致的轨迹。

论文效果: Senna [19] 和 Senna-2 在闭环场景下的定性对比。Senna在停止场景中存在规划不一致问题,在切入场景中存在决策不一致问题。相比之下,Senna-2在这些具有挑战性的场景中保持了决策一致性和准确的轨迹规划,展示了改进的安全性和可靠性。
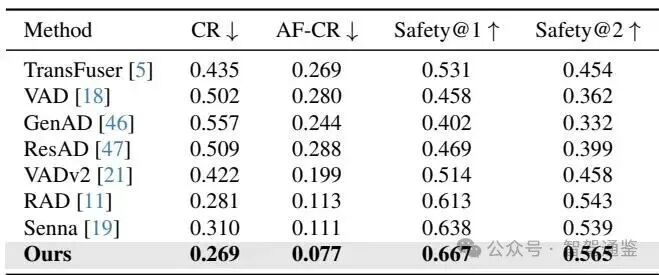
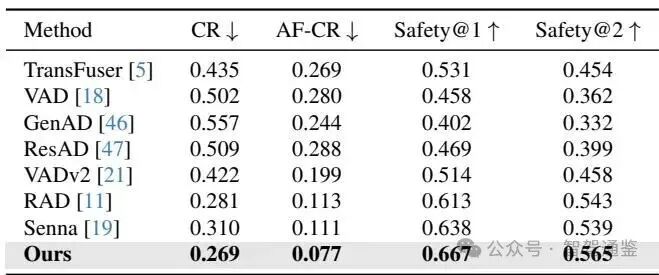
主要结果: Closed-loop quantitative comparisons with existing methods on the 3DGS evaluation benchmark. Our method significantly improves safety and reduces the collision rate.
论文信息
暂时无法在飞书文档外展示此内容
- • 标题: Senna-2: Aligning VLM and End-to-End Driving Policy for Consistent Decision Making and Planning
- • 附言: 15 pages, 8 figures. Project page: https://ambitious-idiot.github.io/senna2-project
- • 作者: Yuehao Song, Shaoyu Chen, Hao Gao, Yifan Zhu, Weixiang Yue, Jialv Zou, Bo Jiang, Zihao Lu, Yu Wang, Qian Zhang, Xinggang Wang
- • 单位: 华中科技大学, Horizon Robotics
- • 日期: 2026-03-11 18:33:49
- • 领域: Computer Vision and Pattern Recognition (cs.CV)
- • 页数: 15 pages, 8 figures, 11 tables
论文概述
研究背景与问题
当前研究领域的背景
- • 端到端(E2E)驾驶策略:现有方法通过统一的感知-预测-规划流程实现从传感器输入到驾驶计划的映射,但在复杂场景中缺乏高阶语义推理能力。
- • 视觉语言模型(VLM):VLM在场景理解和因果推理方面表现出色,但其高阶决策与E2E低级规划的对齐不足,导致轨迹与决策不一致。
现有方法存在的问题和局限性
- • 决策-规划一致性缺失:现有方法未显式对齐VLM的高阶决策与E2E的低级规划,导致轨迹偏离决策意图(如方向错误、速度变化不匹配)。
- • 弱化上层指导能力:VLM的决策无法有效引导E2E规划,降低系统的可解释性和安全性。
论文方法
技术实现细节
- \1. 双系统架构
- • VLM模块:采用Qwen2.5-VL-3B模型生成高阶决策(速度控制与方向控制)。
- • 决策****适配器:将VLM决策转换为嵌入特征(VLM tokens与决策tokens),通过MLP融合形成VLM条件特征。
- • E2E策略:基于DiT架构的扩散规划器,结合VLM条件特征生成轨迹。
- \2. 三阶段训练****范式
- • 阶段1:驾驶预训练
- • VLM预训练:通过问答监督学习VLM的驾驶知识(公式(2))。
- • E2E预训练:将轨迹生成建模为扩散问题,预测残差轨迹(公式(3))。
- • 适配器****预训练:固定VLM参数,仅优化适配器与E2E策略。
- • 阶段2:开环对齐
- • 一致性指标:定义二元一致性指示函数(公式(4)),通过显式监督修正不一致样本(公式(5))。
- • 阶段3:闭环对齐(HRL)
- • 奖励设计:结合安全(TTC惩罚)与效率(速度惩罚)的复合奖励(公式(6)-(8))。
- • 分层优化:先优化低级规划器,再更新VLM决策(公式(9)-(10))。
算法流程
- • 输入:多视角图像、导航指令、自车状态。
- • 输出:与VLM决策一致的轨迹。
- • 关键步骤:VLM生成决策→决策适配器转换→E2E策略融合条件特征→HRL闭环优化。
核心创新点
- \1. 三阶段显式对齐****范式
- • 预训练→开环对齐→闭环对齐:逐步对齐VLM与E2E策略,解决决策与规划的动态一致性问题。
- • 对比现有方法:传统方法依赖隐式对齐,而Senna-2通过分阶段显式优化提升一致性。
- \2. 决策适配器设计
- • 双token融合:结合VLM tokens(保留语义上下文)与决策tokens(结构化决策),增强模型对决策的感知能力。
- • 技术突破:首次将VLM的语义推理与E2E的细粒度规划显式解耦并融合。
- \3. 闭环对齐的分层强化学习(HRL)
- • 安全与效率平衡:通过TTC与速度惩罚设计复合奖励,优化实际场景中的交互行为。
- • 分层优化策略:先优化低级规划器再更新VLM,确保双系统协同。
实验结果
实验设置和数据集
- • 数据集:10,000小时真实驾驶数据(含多视角视频、地图标注、交通参与者信息)。
- • 3DGS环境:1,300个高风险驾驶片段重建为闭环测试环境。
主要实验结果
- \1. 决策-规划一致性
- • F1分数****提升19.3%(表1),速度与方向决策对齐显著增强(图1(c))。
- \2. 开环性能
- • FDE****降低5.7%(表2),碰撞率(CR)降至0.288%。
- \3. 闭环性能
- • AF-CR降低30.6%(表3),Safety@1提升至66.7%。
- \4. 消融实验
- • 决策适配器有效性:移除VLM token或决策token均导致FDE增加10%以上(表4)。
- • 三阶段训练必要性:仅预训练时一致性较低(F1=0.701),引入闭环对齐后提升至0.760(表5)。
定性结果
- • 复杂场景表现:在变道、急刹车等场景中,Senna-2的轨迹规划更稳定且符合决策意图(图5)。
结论与影响
论文的主要贡献
- \1. 提出Senna-2:首个通过三阶段训练显式对齐VLM与E2E策略的自动驾驶系统,提升决策与规划一致性。
- \2. 验证有效性:在开放与闭环场景中均显著优于SOTA方法(如ResAD、RAD),AF-CR降低30.6%。
对领域的影响
- • 推动多模态融合:为自动驾驶提供可解释、可控的决策框架,促进VLM与E2E策略的深度融合。
- • 提升安全性与****鲁棒性:通过显式对齐减少规划偏差,增强复杂场景下的可靠性。
未来工作方向
- \1. 实时推理优化:当前VLM在边缘设备上无法实时运行(10Hz),需硬件加速与模型轻量化。
- \2. 同步协作机制:设计VLM与E2E策略的同步交互方案,减少异步缓存延迟。
- \3. 长尾场景泛化:进一步验证Senna-2在极端交通场景(如暴雨、夜间)中的适应性。
论文精读
摘要
视觉-语言模型(VLMs)通过利用高层语义推理能力,增强了端到端(E2E)驾驶策略的规划能力。然而,现有方法通常忽略了VLM的高层决策与E2E的底层规划之间的双系统一致性。因此,生成的轨迹可能与预期的驾驶决策不一致,导致系统的自上而下指导能力和决策跟随能力减弱。为了解决这一问题,本文提出了Senna-2,这是一种先进的VLM-E2E驾驶策略,能够显式地对齐两个系统以实现一致的决策和规划。本文的方法遵循一种以一致性为导向的三阶段训练范式。在第一阶段,进行驾驶预训练以实现初步的决策和规划,并通过一个决策适配器将VLM的决策以隐式嵌入的形式传递给E2E策略。在第二阶段,在开环设置中对齐VLM和E2E策略。在第三阶段,通过3DGS环境中的自底向上的分层强化学习(Hierarchical Reinforcement Learning)执行闭环对齐,以增强安全性和效率。大量实验表明,Senna-2实现了优越的双系统一致性(FI分数提升),并在开环(FDE降低)和闭环设置(AF-CR降低)中显著提升了驾驶安全性。
1.引言
可靠的自动驾驶系统应将高层决策作为低层轨迹规划的指导。确保这种决策-规划一致性可以生成忠实反映驾驶意图的轨迹。最近的端到端(E2E)驾驶框架[5, 13, 18, 21, 27, 42, 46]通过统一的感知-预测-规划流水线,展示了将感官输入映射为驾驶计划的强大能力。然而,它们在高层推理和决策方面仍存在不足,而这些对于复杂驾驶场景中的安全性和效率至关重要。同时,视觉-语言模型(VLMs)[1, 2, 4, 36, 40]在场景理解和因果推理方面表现出强大的能力。最近的研究[19, 48]已将VLM集成到E2E策略中,以有效弥补这一认知缺陷。
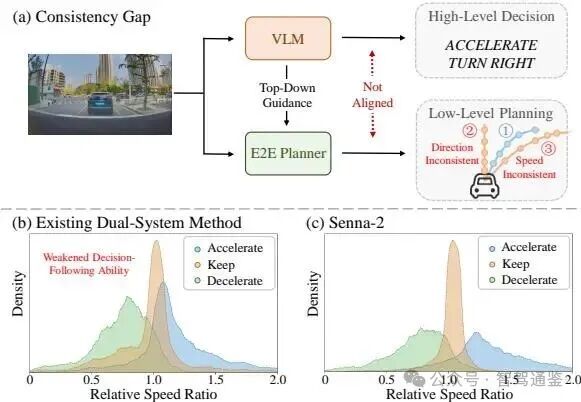
▲ 图1. VLM与E2E规划器之间的一致性差距。(a)E2E规划器可能与VLM决策 不一致,例如 错误的方向或 速度变化不匹配。(b)现有方法[19]显示出分散的速度分布,与速度决策不一致。(c)通过一致性导向训练,Senna-2产生更明显且与决策对齐的速度分布,反映了双系统一致性和决策跟随能力的提升。相对速度比:第3秒的计划速度与初始速度的比率,反映规划轨迹的速度变化趋势。
尽管VLM-E2E驾驶策略[10, 17, 29]取得了最新进展,但高层决策与低层轨迹规划之间仍存在显著的一致性差距。如图1(a)所示,现有方法通常使用VLM决策来指导E2E策略的规划。然而,在没有明确对齐的情况下,生成的轨迹往往偏离驾驶意图,导致错误的驾驶方向或速度变化不匹配。这种不一致性削弱了VLM的自上而下指导能力和可解释性,最终导致次优甚至不安全的驾驶行为。
本文将根本原因确定为高层决策与低层规划之间缺乏显式对齐。为了解决这一问题,本文开发了一个三阶段的以一致性为导向的训练框架,该框架将VLM的高层决策与端到端(E2E)规划器的低层规划对齐,从而确保两个系统在决策和规划上的一致性:
驾驶预训练:VLM和E2E策略在大规模驾驶数据上进行训练,以实现初步的决策和规划能力,同时优化决策适配器来弥合这两个系统之间的差距。
开环对齐:通过分析规划轨迹与相应VLM决策之间的运动学差异,识别出VLM和E2E策略之间不一致的地方,并选择性地优化这些案例,以增强双系统的协同一致性。
基于分层强化学习(HRL)的闭环对齐:本文进一步通过在线HRL在闭环3DGS环境中[11]优化系统。为了平衡安全性和效率,设计了综合奖励函数,同时考虑这两个方面。基于这些奖励函数,策略被分层优化:首先通过纵向缩放惩罚优化E2E规划器,然后相应地更新VLM。
基于此训练流程,本文引入了Senna-2,这是一个统一的VLM–E2E驾驶系统,能够确保决策和规划的一致性。Senna-2结合了VLM的语义推理能力和E2E策略的细粒度规划能力,从而实现了更安全、更连贯的驾驶行为。这种设计提供了两个关键优势:(1) VLM充当一个可解释的人机接口,既能调节驾驶行为,又能解释高层决策。(2) VLM的强大泛化能力与E2E策略的适应性相结合,增强了对长尾场景的鲁棒性,相比现有方法[19],实现了更一致且可控的规划(图)。
本文从多个维度评估了Senna-2,包括决策-规划一致性、开环规划性能以及闭环驾驶稳定性。实验结果表明,Senna-2在决策和规划之间实现了更高的一致性(相比Senna [19],F1分数提高了19.3%),同时在开环基准测试中保持了具有竞争力的准确性和鲁棒性(最终位移误差减少)。
和闭环基准测试(故障时碰撞率降低 )。
本文的贡献总结如下:
• 本文提出了 Senna-2,这是一种统一的 VLM-E2E 驾驶策略,能够实现一致的决策和规划。
• 本文提出了一种以一致性为导向的三阶段训练范式,通过大规模预训练、开环对齐和基于 HRL 的闭环对齐,逐步对齐高层决策和低层规划。
• 在大规模驾驶基准上的实验验证了 Senna-2 显著提高了双系统一致性、规划准确性和闭环鲁棒性。
2.相关工作
2.1. 端到端自动驾驶
端到端自动驾驶策略从统一的感知–规划框架发展为概率性、生成性和闭环一致性的策略。UniAD [13] 和 VAD [18] 开创了统一的架构,将感知、预测和规划集成在一起,直接从传感器输入中实现轨迹推理。SparseDrive [35] 进一步探索稀疏表示,在不牺牲全局上下文的情况下提高效率。VADv2 [21] 和 Hydra-MDP 系列 [24, 26] 通过多模态规划扩展了这一范式,以增强行为多样性和鲁棒性。生成方法 [22, 27, 42, 46, 52] 将轨迹分布建模为一个生成任务,并产生比确定性回归更具有表现力的驾驶策略。同时,RAD [11] 利用闭环优化来缩小开环训练与实际部署之间的差距。尽管取得了这些进展,大多数端到端框架缺乏高层推理,这促使了视觉–语言模型的整合,以实现更可控和可解释的决策。
2.2. 自动驾驶中的 VLM
视觉-语言模型(VLMs)的最新进展为自动驾驶引入了一种新范式。早期的工作 [7, 31, 44, 49] 将驾驶问题表述为以语言为中心的问题,并通过问答方式利用 VLM 进行场景理解。另一条研究路线 [15, 25, 34, 37, 39, 41, 48] 通过直接将规划集成到 VLM 架构中,使 VLM 具备轨迹生成能力。然而,由于语义空间和动作空间本质上是异构的[16],这种紧密耦合通常会导致优化不稳定。为了解决这个问题,Senna [19] 将高层决策与底层规划解耦,并利用 VLM 的决策来指导端到端策略。后续工作通过引入显式的推理过程 [20, 50] 或分层指令 [29] 进一步增强了这一范式。更近期的方法则结合了生成式规划器 [10, 17],以根据高层决策合成多样且上下文感知的轨迹。尽管如此,当前基于 VLM 的驾驶系统仍然缺乏两个系统之间的显式一致性约束,这可能导致决策与规划之间出现潜在的不一致。
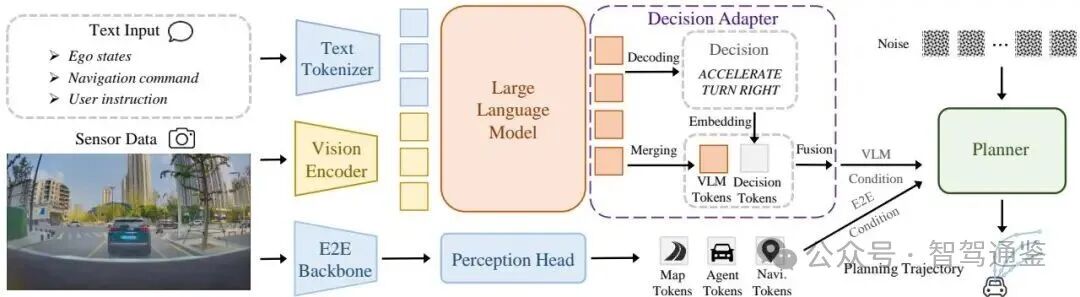
▲ 图 2. Senna-2 的整体模型架构。文本和视觉输入由 VLM 处理,以产生高层驾驶决策,这些决策通过决策适配器转换为 VLM 条件嵌入。然后,端到端规划器将 VLM 条件与其自身的端到端特征融合,以生成与高层决策一致的轨迹。
2.3. 驾驶中的跨系统一致性
虽然基于 VLM 的框架将高层决策引入驾驶系统,但保持决策与规划之间的一致性仍然是一个挑战。Sim-Lingo [33] 提出了一项动作梦想任务,用于评估指令与规划之间的一致性。VLM-AD [43] 和 ALN-P3 [30] 提出了 VLM 与端到端策略在感知、预测和规划特征之间的特征对齐。RDADriver[14] 提出了成对 CoTs 与规划结果之间的推理-决策对齐约束。然而,这些方法主要关注数据级或表示级的对齐,缺乏决策与规划之间的显式一致性约束。
3.方法
3.1. 双系统架构
本文模型架构由三个组件组成:VLM模块、决策适配器和端到端驾驶策略,如图2所示。VLM模块生成高层决策,决策适配器将其转换为条件特征,而端到端策略则在这些特征的指导下生成最终的驾驶规划。
VLM。本文采用Qwen2.5-VL-3B [2] 作为高层驾驶决策的基础模型,以在性能与效率之间取得良好平衡。输入包括单帧前视图像和文本输入,包括系统提示、导航指令和自身速度。经过分词后,视觉和文本标记被联合输入语言模型中以预测驾驶决策。驾驶决策由速度控制和方向控制组成。速度控制包括加速、减速、保持速度和停止。方向控制包括直行、左转、右转、左变道和右变道。这些结构化的元动作作为可解释的决策,指导轨迹规划。
决策适配器。本文设计了一个决策适配器,将VLM生成的高层决策转换为与端到端驾驶模型兼容的表示形式。具体而言,适配器输出两种互补类型的标记:VLM标记和决策标记。本文从VLM中提取最终隐藏状态,并通过MLP进行投影以获得VLM标记 ,从而保留来自VLM的推理上下文。同时,为了增强模型对VLM决策的感知能力,本文引入了可学习的速度和方向控制类别嵌入。根据解码后的元动作,分别选择速度嵌入 和方向嵌入 作为决策标记。然后将VLM标记和两个决策标记融合,形成VLM条件特征:
这种融合设计结合了VLM标记在捕捉全局语义方面的表现力与VLM决策的结构化可解释性。
端到端驾驶策略。本文的端到端驾驶策略(E2E策略)由一个E2E骨干网络、多个感知头和基于扩散的规划器组成。E2E骨干网络从多视角图像序列中提取时空特征。然后,感知头根据时空特征和导航指令预测静态地图元素、动态代理和导航提示的特征。这些特征被连接起来形成整体的E2E条件。规划器采用DiT架构[32],并通过交叉注意力[38]将E2E条件纳入其中。为了引入高层决策指导,本文使用AdaLN[32]将VLM条件注入规划网络。这种机制使VLM条件能够全局调节规划过程,引导生成的轨迹与高层决策保持一致。

▲ 图3. 一致性导向的训练方案。本文执行三个训练阶段,包括驾驶预训练、开环对齐和闭环对齐(结合分层强化学习*HRL)。*
3.2. 训练方案
本文采用三阶段训练范式:驾驶预训练、开环对齐和结合HRL的闭环对齐,如图3所示。
3.2.1. 驾驶预训练
首先进行驾驶预训练,以赋予VLM基本的驾驶知识并使其与E2E策略对齐。
VLM预训练。本文定义了一个运动学映射函数 ,该函数按照Senna[19]的设计,将真值轨迹转换为由速度和方向分量组成的元动作 。此元动作文本在问答(QA)公式中作为答案。同时,前视图像、导航文本和自车状态用于构建问题。通过基于QA的监督训练VLM:
其中 表示问题输入,表示第 个元动作标记。
端到端预训练。本文将轨迹生成建模为一个基于扩散的规划问题 [27]。本文将预测目标设为残差轨迹 [47],即专家轨迹与从初始速度外推得到的参考轨迹之间的差异。规划器以感知标记作为条件,并通过扩散去噪过程预测该残差轨迹。在训练过程中,本文采用预测噪声和真值噪声之间的标准扩散损失:
其中 是真值残差轨迹,是时间步处的噪声样本,表示端到端条件标记,是真值噪声,是由参数化为的端到端模型产生的预测噪声。
适配器预训练。在独立训练之后,本文引入决策适配器。本文冻结 VLM 参数,并仅使用端到端规划损失 同时优化决策适配器和端到端策略。这确保了适配器可以在不影晌 VLM 决策能力的情况下连接各个模块。
3.2.2 开环对齐
在第二阶段,本文采用开环对齐训练方案。其核心思想是利用 VLM 决策和端到端规划之间的一致性作为显式的优化信号。当两个系统一致时,模型会强化相应的行为;否则,它会在外部监督下更新策略以纠正差距。
具体来说,本文采用一个运动学映射函数 将预测轨迹 投影到其对应的决策类别中,然后将其与 VLM 决策 进行比较,以评估它们的行为一致性。为了形式化这一点,本文定义了一个简单而有效的二元一致性指标:
当两者属于同一类别时,认为它们是一致的;否则认为不一致。
对于不一致的样本,高层决策与低层规划之间的不匹配会导致不可靠的行为。为了在保持规划合理性的同时减少一致性差距,本文应用专家轨迹和相应的决策标签进行显式监督。相比之下,对于一致的样本,模型将其预测视为内部连贯的行为。受负样本强化 [51] 的启发,本文跳过这些样本的外部监督,并将预测本身视为提供自强化反馈的隐式专家信号。
基于这一机制,损失函数定义为:
其中 是一个平衡权重。这种自适应训练策略使模型能够通过动态监督实现更高的一致性。
3.2.3. 带有HRL的闭环对齐
虽然开环对齐确保了常规场景中的策略一致性,但其依赖离线监督限制了在分布外情况下的性能 [8]。为了解决这个问题,本文引入了一种通过在线分层强化学习(HRL)的闭环对齐方法,该方法能更好地对齐决策与规划,从而提升真实场景中的安全性和效率。
为了实现闭环训练,本文首先从驾驶演示中收集大量高风险、交通密集的片段。每个片段通过3D高斯点绘(3DGS)[11]转换为一个独立的数字驾驶环境。在训练过程中,VLM–E2E策略部署在一部分环境中以控制自车并生成轨迹。这些轨迹随后用于计算奖励并优化策略。优化遵循自下而上的分层方案:首先使用安全性和效率奖励优化低级规划器,然后将改进结果传播到更新高级决策,从而确保两个系统之间的一致性对齐。
低级规划器奖励设计。对于低级规划器,本文基于自车和周围车辆的位置和运动状态设计了两种互补的奖励。安全性奖励由时间至碰撞(TTC)计算得出,当检测到碰撞风险(TTC 3s)时,纵向方向的轨迹会受到惩罚,以避免不安全行为。效率奖励则在自车速度明显低于导航限速和参考演示速度时应用。这些轨迹被视为低效率样本,并通过纵向延伸进行鼓励,以促进更平滑和更快的驾驶。这些奖励共同引导低级规划器在闭环训练中平衡谨慎与效率。上述机制可以表述如下:
其中 表示由参数化的驾驶策略,表示长度为的规划轨迹,表示的第个轨迹点,和分别表示 TTC 和速度指标,和是它们各自对应的阈值,是停止梯度操作符,是指示函数。
高阶决策对齐。对于高层级,本文将VLM决策与优化后的低层级规划对齐。通过运动学映射函数 ,将优化后的轨迹映射到其对应的高层级决策。假设VLM决策与轨迹对应的决策不一致,在这种情况下,本文进一步惩罚VLM决策的概率分布,以确保双系统的一致性:
其中 表示VLM决策,表示问题输入。最终的损失函数可以表示为:
其中 是高低层级损失之间的平衡权重。
4.实验
4.1. 实验设置
数据集。本文在真实环境中收集了约10,000小时(360M帧)的专家人类驾驶演示。每个演示包括同步的多视角视频、带有地图、交通代理和导航信息详细标注的里程计数据。基于里程计数据,生成第一阶段和第二阶段训练的高层级决策标签。在第三阶段,选择1,300个高风险驾驶片段,长度从15秒到40秒不等,并将其重建为3DGS环境。将1044个片段用于训练,256个片段用于闭环评估。
▼ 表1. 决策-规划一致性比较。Senna-2相比Senna [19] 在VLM决策与端到端规划之间表现出更高的一致性。

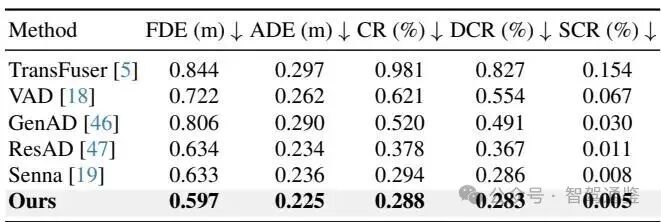
▼ 表2. 与现有方法的开环定量比较。本文的方法在位移误差和碰撞率指标上均优于现有方法。
评估指标。本文全面评估了Senna-2的性能,涵盖三个方面:决策-规划一致性、开环指标和闭环指标。决策-规划一致性和开环指标是在100小时驾驶数据的一个子集上进行评估的。闭环指标则在3DGS环境中进行评估。
为了评估决策-规划一致性,本文计算VLM决策与通过运动学映射从端到端轨迹中获得的决策之间的F1分数。
开环评估指标包括:最终位移误差(FDE):预测轨迹终点与真值终点之间的欧几里得距离;平均位移误差(ADE):在整个时间范围内预测轨迹与真值轨迹之间的平均距离误差;碰撞率(CR):预测轨迹与其他交通参与者或场景中静态障碍物发生碰撞的比例;动态碰撞率(DCR):仅涉及动态对象(例如车辆或行人)的碰撞比例;以及静态碰撞率(SCR):仅涉及静态对象(例如路缘石)的碰撞比例。
闭环评估指标包括:责任碰撞率(AF-CR):由于自动驾驶车辆不当决策而导致碰撞的驾驶片段比例;碰撞率(CR):整个运行过程中发生碰撞的驾驶片段总体比例;以及安全性/ 安全性:在运行过程中与周围智能体的最小碰撞时间(TTC)超过1秒或2秒的安全驾驶片段比例。
▼ 表3. 在3DGS评估基准上与现有方法的闭环定量比较。本文的方法显著提高了安全性并降低了碰撞率。
4.2. 主要结果
4.2.1. 与现有方法的比较
本文在开环和闭环设置中评估Senna-2与最先进的方法,所有模型均在相同数据集上训练以进行公平比较。如表2所示,Senna-2在开环评估中将FDE减少了。表3中的闭环结果进一步证实了其有效性,AF-CR减少了。值得注意的是,在闭环评估中,Senna-2优于基于强化学习的基线,例如RAD [11],尽管两者都采用了闭环强化训练。这表明收益来自于本文的对齐策略,而不仅仅是闭环强化本身。总体而言,这些结果表明本文的方法在现实场景中一致地提高了预测准确性和驾驶安全性。
4.2.2. 决策-规划一致性
本文进行了定量和定性分析,以评估VLM决策与端到端规划之间的双系统一致性。
定量结果。如表1所示,本文比较了本文方法与Senna [19]之间的决策-规划一致性。本文方法在平均F1分数上实现了的改进,表明它显著提高了VLM与端到端策略之间的对齐程度。为了直观说明开环可控性,本文在图1中可视化了固定速度控制动作下的相对速度分布。如图1(b)所示,Senna在三种控制模式之间表现出有限的可分性,表明控制区分度较弱。相比之下,Senna-2(图1(c))产生了明显分离的分布,展示了更一致的自上而下指导。
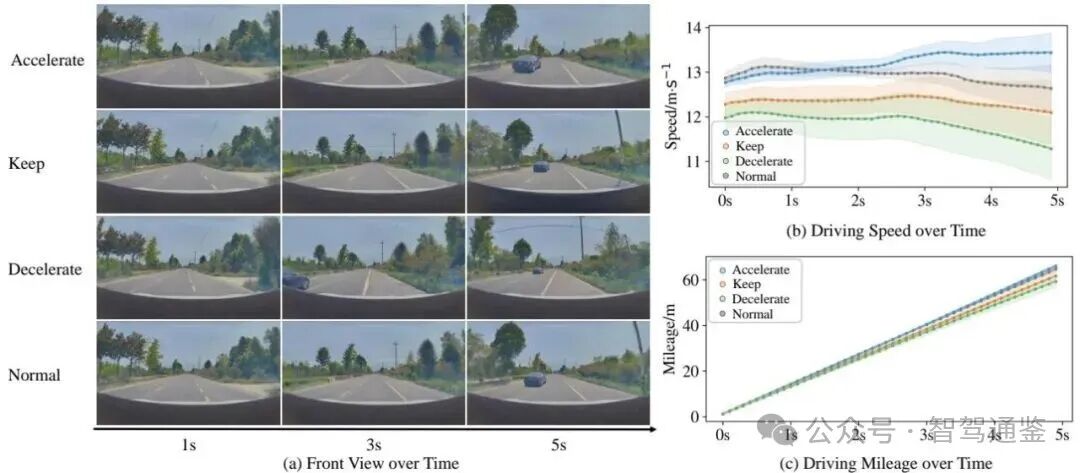
▲ 图4. 空旷道路场景中的闭环速度控制。本文可视化了(a)驾驶轨迹、(b)速度曲线和(c)里程曲线在不同VLM决策下的表现。本文方法表现出强大的决策跟随能力。低级规划遵循高级决策进行速度控制。Normal表示使用VLM预测的决策,而accelerate、keep和decelerate表示在整个rollout过程中使用固定的决策。
▼ 表4. 模型架构的消融研究。Dual system:是否集成VLM;VLM token / Dec. token:是否在决策适配器中使用VLM token/决策token。
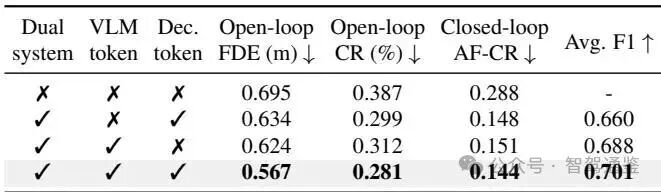
▼ 表5. 训练阶段的消融研究。本文提出的三阶段训练流程在开环和闭环性能之间取得了平衡,同时增强了高层决策与低层规划之间的一致性。
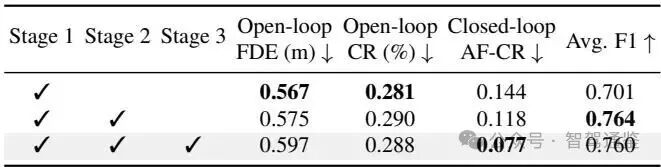
定性分析。本文展示了一个闭环案例研究,从定性角度考察在不同固定决策下的行为表现。本文在同一3DGS环境中进行了多次具有不同决策的运行。前视场景及其对应的速度和里程曲线的可视化结果如图4所示。本文的方法为每个动作生成稳定且明显区分的控制剖面,展示了在真实驾驶场景中有效且可解释的规划一致性。
4.3. 消融研究
模型架构。如表4所示,本文对模型架构进行了一项消融研究,以进一步验证VLM和决策适配器的贡献。该表中的所有实验仅使用第1阶段进行训练,以确保公平且独立的比较。
为了评估双系统设计的有效性,本文将不带VLM引导的纯端到端基线(第1行)与所提出的双系统模型(第4行)进行了比较。Senna-2持续提升了安全性和规划精度,碰撞率降低了 ,最终位移误差(FDE)减少了0.128米。这证实了由VLM提供的高层决策能够提供可靠的引导,从而增强端到端规划器的稳定性和安全性。
本文进一步通过移除VLM token(第2行)和决策token(第3行)来对决策适配器进行消融。移除VLM token会导致明显的性能下降(FDE增加 ,CR增加 ),而移除决策token同样会损害性能(FDE增加 ,CR增加 )。这些结果表明,VLM语义信息和对决策类别的显式感知对于实现准确且一致的规划都是必不可少的。
训练阶段。本文进一步在表5中展示了一个消融研究,验证了所提出的训练方法的有效性。仅使用第1阶段进行训练可获得最低的开环FDE,因为模型纯粹针对轨迹回归进行优化,而没有考虑双系统交互。然而,这也导致了一致性较低和闭环性能较弱。引入第2阶段显著增强了双系统一致性,F1分数提高了9.0%,这表明显式对齐的重要性。结合完整的第3阶段直接改善了闭环行为,AF-CR减少了34.7%,从而在开放世界驾驶场景中实现了更好的泛化能力。这些结果表明,这三个阶段起到了互补的作用,完整的流程在开环准确性、闭环鲁棒性和决策-规划一致性之间达到了平衡。
▼ 表6. 在NAVSIM v2 navtest基准上的性能。

▲ 图5. Senna [19] 和 Senna-2 之间的闭环定性比较。Senna 在 (a) 停车场景中的规划不一致和 (b) 插入场景中的决策不一致。相比之下,Senna-2 在这些具有挑战性的场景中保持了决策的一致性和轨迹规划的准确性,展示了在闭环驾驶中更高的安全性和可靠性。
4.4. 在开源NAVSIM v2基准上的性能
本文进一步在NAVSIM训练集[6]上对模型进行了微调,并在NAVSIM v2基准[3]上评估了Senna-2的规划性能。如表6所示,本文的方法获得了86.6的EPDMS,比之前表现最好的模型高出1.1 EPDMS。这一结果突显了Senna-2的鲁棒性及其掌握复杂驾驶场景的能力。
4.5. 定性结果
暂时无法在飞书文档外展示此内容
论文在图5中进一步展示了Senna-2与Senna [19]之间的闭环定性比较。在图5(a)中,Senna表现出明显的规划不一致:尽管VLM发出了正确的减速命令,但规划器未能及时响应,最终导致与前方车辆发生追尾碰撞。相比之下,Senna-2保持了决策-规划的一致性,并实现了安全停车。在图5(b)中,Senna在一个切入场景中出现了决策错误。它首先输出了一个错误的加速命令,导致规划器错过了适当的制动窗口并与汇入车辆发生碰撞。到7.5秒时,它在碰撞后进一步发出了一条不合理的右转动作。然而,Senna-2始终提供正确的减速决策以安全处理汇入,并生成一条合理的左变道命令以完成避让操作。这些结果表明,Senna-2在具有挑战性的情况下确保了更可靠的双系统一致性以及更安全的闭环行为。
5.结论与局限
在本文中,论文提出了Senna-2,这是一种将视觉语言模型(VLM)与端到端(E2E)驾驶策略对齐的双系统驾驶策略,用于一致的决策和规划。通过引入包含驾驶预训练、开环对齐和基于分层强化学习(HRL)的闭环对齐的三阶段训练策略,Senna-2有效地弥合了VLM决策与E2E模型规划之间的差距。在开环和闭环基准上的大量实验表明,Senna-2在驾驶安全性和可解释性方面显著优于最先进的基线方法。本文强调了将多模态推理集成到端到端驾驶系统中的潜力,为实现更可靠、可解释且符合人类偏好的自动驾驶铺平了道路。
一个局限是当前的VLM无法在车载边缘设备上实现实时推理(10 Hz)。VLM和E2E策略异步运行,内存库缓存VLM特征以进行双系统交互。实现完全同步协作需要进一步的硬件优化。
转载公众号:智驾通鉴
原链接:https://mp.weixin.qq.com/s/hOkPMQf0pwdrLbygClSYPg

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)