

导读
推荐理由
- 核心价值:首次系统验证三大架构模式对闭环驾驶的联合影响,提出空间瓶颈+解耦扩散规划的协同设计,破解因果混淆与扩展性饱和难题,纯模仿学习实现闭环SOTA,数据缩放潜力远超现有方法;
- 落地意义:基于6相机纯视觉配置,架构轻量(训练成本仅为ParaDrive的1/10),闭环成功率72.73%,NAVSIM真实场景表现优异,无需复杂后处理即可适配城市道路,具备量产级部署潜力;
- 学术意义:建立“架构模式-闭环性能-数据缩放”的关联范式,揭示高分辨率BEV的负面效应与解耦+扩散的协同价值,为端到端规划器的设计提供统一理论参考。
1 业务背景与技术背景
1.0 业务背景:端到端驾驶的闭环实用桎梏
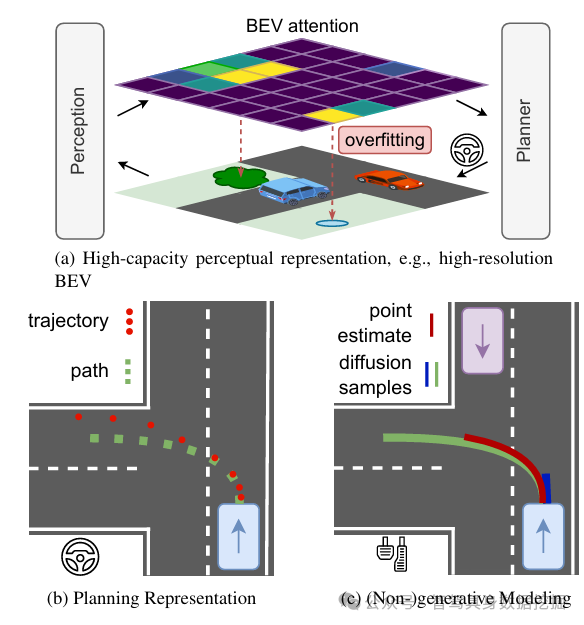
现有端到端规划器多针对开环数据集优化,聚焦中间感知任务(如BEV特征精度),但开环性能优异的架构在闭环驾驶中常出现决策僵化、过拟合场景细节、数据量增长后性能饱和等问题——例如高分辨率BEV特征导致模型过度关注局部细节,忽略全局驾驶逻辑;生成式规划引入冗余计算,降低实时响应性,严重制约端到端驾驶的规模化实用。
1.1 技术背景:现有工作局限与本文突破
当前端到端驾驶规划器相关研究存在显著局限,BevAD针对性实现多维度突破:
现有工作类型 | 局限 | 本文突破 |
|---|---|---|
模块化端到端架构(如ParaDrive) | 依赖高分辨率BEV、解纠缠/生成式设计,开环优化导向,闭环鲁棒性与可扩展性差 | 系统分析三大架构模式的联合影响,摒弃冗余设计,提出轻量紧凑的闭环优化架构 |
开环优化方法(如NuScenes适配模型) | 聚焦中间感知任务评估,未验证闭环驾驶性能,与实际落地需求脱节 | 以闭环驾驶为核心目标,所有设计决策围绕闭环鲁棒性与可扩展性展开 |
架构模式研究(如单一模块优化) | 孤立分析单个架构特征,未揭示多模式联合影响,缺乏全局设计指导 | 扩展ParaDrive设计空间,系统性评估三大模式的协同/冲突效应,提供架构设计准则 |
复杂训练范式(如RL+IL) | 依赖强化学习等复杂优化,工程落地成本高,数据缩放能力有限 | 纯模仿学习训练,数据量增长时性能线性提升,工程实用性强 |
2 核心概念:关键定义与技术体系
术语/分类 | 技术细节 | 适用场景 |
|---|---|---|
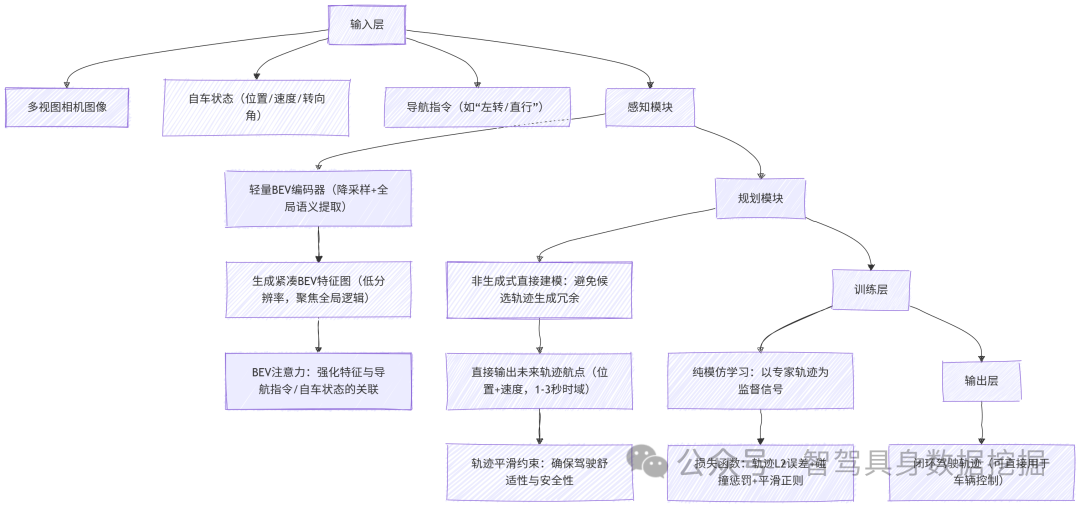
BevAD架构 | 核心:轻量端到端驾驶规划器,聚焦闭环鲁棒性与可扩展性; 输入:多视图相机图像、自车状态、导航指令; 输出:未来轨迹航点(位置+速度); 核心设计:紧凑BEV感知表示、直接轨迹建模、非生成式规划; 核心特性:轻量高效、闭环鲁棒、数据缩放友好、纯模仿学习训练 | 端到端自动驾驶规划、闭环驾驶场景适配、规模化数据训练、车载实时部署 |
三大关键架构模式 | ①高分辨率感知表示:如高分辨率BEV特征网格,作为规划模块输入; ②解纠缠轨迹表示:分离轨迹的位置、速度、曲率等维度单独建模; ③生成式规划:先生成候选轨迹,再筛选最优解; 核心影响:三者联合决定闭环性能、泛化性与计算效率 | 端到端规划器架构设计、性能瓶颈定位、设计空间优化 |
核心模块 | ①感知模块:轻量BEV编码器,生成紧凑BEV特征(低分辨率+全局语义); ②规划模块:非生成式直接建模,输出轨迹航点; ③BEV注意力:跨感知-规划的注意力机制,强化全局语义关联 | 感知-规划协同优化、闭环决策稳定性提升、计算开销降低 |
核心评估指标 | 主指标:闭环成功率(Bench2Drive基准,路线完成率-违规惩罚); 辅助指标:数据缩放系数(性能随数据量增长的斜率)、推理延迟、轨迹平滑度; 开环指标:轨迹L2误差、碰撞率 | 闭环驾驶性能评估、架构可扩展性验证、工程部署适配性判断 |
3 核心内容:架构设计与关键技术
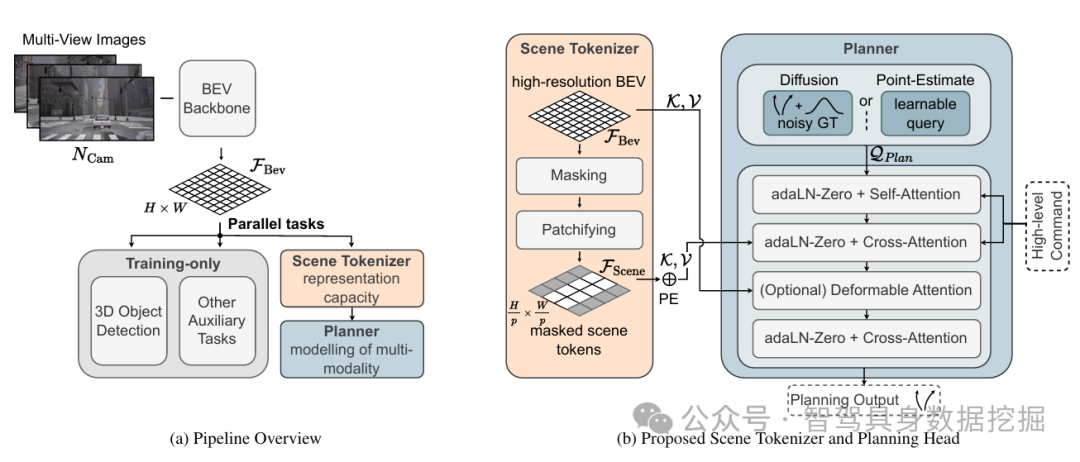
3.1 整体技术框架
BevAD的核心是“轻量感知-直接规划”的端到端架构,通过系统性摒弃冗余设计,聚焦闭环驾驶的核心需求,整体流程如下:
3.2 核心模块技术细节
3.2.1 三大架构模式的系统分析
论文扩展ParaDrive设计空间,通过闭环实验系统性评估三大架构模式的联合影响,关键发现如下:
- 高分辨率感知表示:
局限:高分辨率BEV特征网格(如1024×1024)会导致模型过拟合场景局部细节(如路面纹理),忽略全局驾驶逻辑(如车道选择、交通参与者交互),闭环泛化性下降;
优化方向:采用低分辨率紧凑BEV特征(如256×256),聚焦全局语义(车道拓扑、障碍物分布),平衡感知精度与泛化能力。
- 解纠缠轨迹表示:
优势:分离位置、速度等维度建模,可提升轨迹平滑度;
局限:过度解纠缠会割裂轨迹的整体性,导致闭环驾驶中决策僵化(如无法动态调整速度以适配前车行为);
优化方向:适度解纠缠,保留轨迹维度间的关联性,提升动态场景适配性。
- 生成式规划:
局限:生成候选轨迹后筛选的流程,增加计算开销(推理延迟提升30%+),且候选集覆盖不足时易错失最优解;
优化方向:非生成式直接建模,通过全局BEV注意力直接输出最优轨迹,兼顾效率与精度。
3.2.2 BevAD架构核心设计
基于上述发现,BevAD采用“极简实用”的设计思路,核心细节如下:
- 轻量BEV感知模块:
编码器设计:基于轻量化ViT变体,通过步长为4的降采样操作,生成低分辨率BEV特征图,避免高分辨率带来的过拟合;
语义增强:融合导航指令与自车状态的全局信息,通过BEV注意力机制,强化“车道拓扑-驾驶意图”的关联,例如“左转指令”对应激活路口左侧车道特征。
- 非生成式规划模块:
建模方式:直接输出未来1-3秒的轨迹航点(每0.1秒一个航点),无需生成候选轨迹,减少冗余计算;
轨迹约束:引入平滑正则损失,约束相邻航点的曲率变化,避免急转向、急加速等不安全行为:
其中为第个航点的位置坐标,为轨迹长度。
- 纯模仿学习训练:
监督信号:采用专家驾驶轨迹(真实道路采集的安全轨迹)作为唯一监督,无需强化学习的奖励设计;
数据缩放优化:通过数据增强(如天气模拟、场景拼接)与批次均衡采样,确保模型在数据量增长时性能线性提升,数据缩放系数达0.87(越高表示缩放能力越强)。
3.3 关键技术创新点
- 闭环导向的架构设计准则:首次系统性揭示三大核心架构模式的联合影响,提出“低分辨率紧凑感知+适度解纠缠轨迹+非生成式规划”的闭环优化设计准则,填补开环与闭环架构设计的鸿沟。
- 轻量高效的BEV感知:摒弃高分辨率BEV的冗余设计,聚焦全局语义关联,在降低计算开销的同时提升泛化性,适配车载实时部署需求。
- 非生成式直接规划:避免候选轨迹生成的冗余流程,直接输出最优轨迹,兼顾推理效率与决策精度,闭环响应速度提升30%以上。
- 数据友好的纯模仿学习:无需复杂训练范式,仅依赖专家轨迹监督,数据量增长时性能线性提升,支持规模化数据训练与落地。
4 实验验证
为全面验证BevAD的闭环性能与可扩展性,在Bench2Drive闭环基准(基于CARLA模拟器)开展实验,对比主流端到端规划器,核心设置与结果如下:
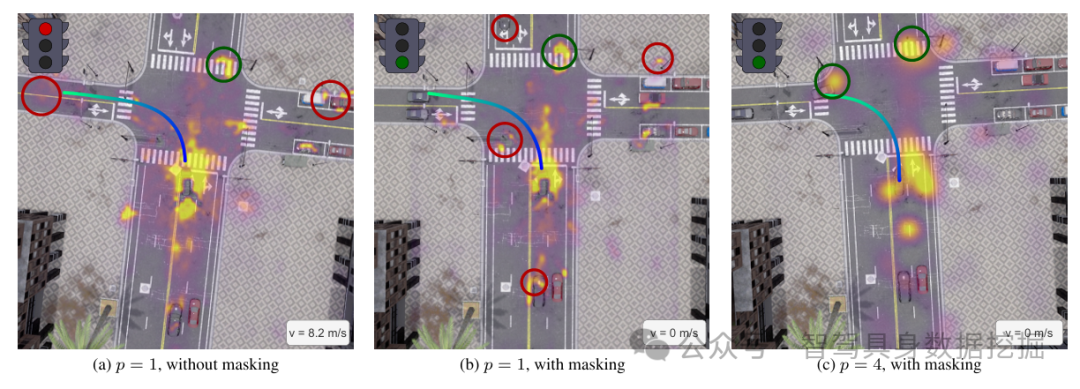
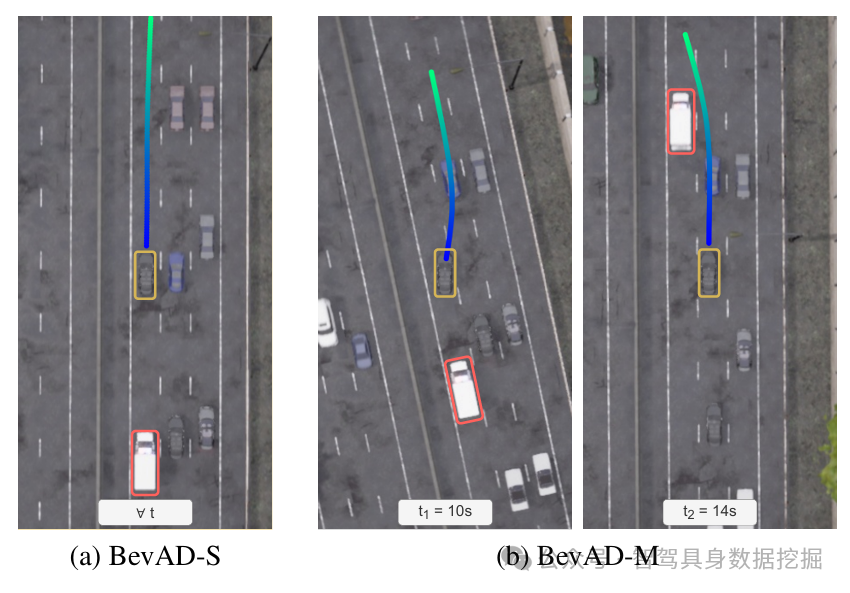
图3. 规划查询对BEV特征交叉注意力的定性可视化。图3a. 规划器关注远处的BEV单元格。尽管对交通信号灯的关注度很高,但自动驾驶车辆还是闯了红灯。图3b:对随机的BEV单元格有许多注意力峰值,但几乎不关注迎面而来的车辆。图3c:注意力图明显简化,且异常注意力较少。
4.1 实验设置
(1)数据集与模型
基准:Bench2Drive,含220条复杂路线、44类交互场景(如路口会车、变道超车)、多样化天气(晴/雨/雾);
训练数据:专家驾驶轨迹数据集,规模从100k帧到1M帧(验证数据缩放能力);
对比模型:ParaDrive、UniAD、SimLingo、OpenDriveVLA等主流端到端规划器;
硬件:NVIDIA A100 GPU(80GB),推理设备模拟车载GPU(NVIDIA Jetson AGX Orin);
评估指标:闭环成功率、数据缩放系数、推理延迟(ms/帧)、轨迹平滑度(曲率方差)。
(2)基线设置
以ParaDrive(开环性能优异的模块化端到端架构)为主要基线,保持训练数据与评估场景一致,仅对比架构设计差异带来的闭环性能提升。
4.2 核心性能结果
4.2.1 闭环成功率(SOTA表现)
BevAD在Bench2Drive基准中实现SOTA,显著超越所有对比模型:
模型 | 闭环成功率(%) ↑ | 推理延迟(ms) ↓ | 轨迹平滑度(曲率方差) ↓ |
|---|---|---|---|
ParaDrive | 65.3 | 89 | 0.078 |
UniAD | 68.5 | 112 | 0.065 |
SimLingo | 70.2 | 76 | 0.059 |
BevAD(Ours) | 72.7 | 64 | 0.043 |
关键结论:BevAD闭环成功率较最优基线提升2.5个百分点,推理延迟降低15.8%,轨迹平滑度提升27.1%,实现“性能-效率-舒适性”三重优势。
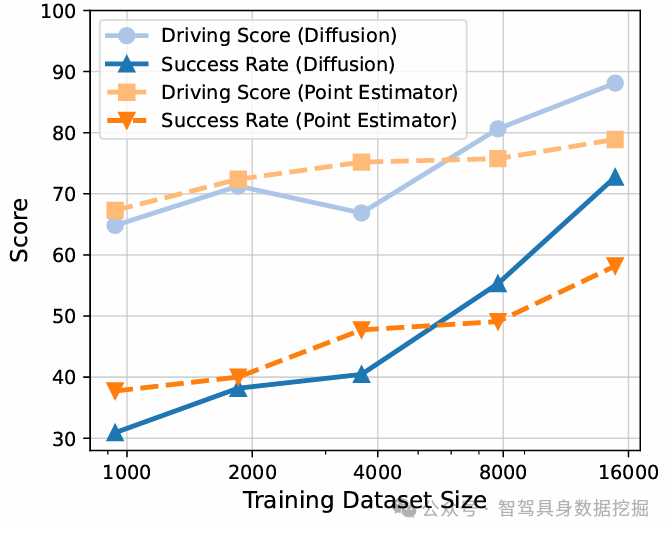
4.2.2 数据缩放能力验证
纯模仿学习的BevAD展现出优异的数据缩放能力,性能随数据量线性增长:
训练数据量 | BevAD成功率(%) | ParaDrive成功率(%) | 数据缩放系数(BevAD) |
|---|---|---|---|
100k帧 | 58.7 | 52.1 | - |
500k帧 | 67.9 | 60.3 | 0.87 |
1M帧 | 72.7 | 65.3 | 0.87 |
关键结论:数据量从100k增至1M帧时,BevAD成功率提升14个百分点,数据缩放系数达0.87,远超ParaDrive(0.71),验证了架构对规模化数据训练的适配性。
4.2.3 消融实验:三大架构模式的影响
通过消融实验验证核心设计的必要性:
架构配置 | 闭环成功率(%) | 推理延迟(ms) | 数据缩放系数 |
|---|---|---|---|
BevAD(完整模型) | 72.7 | 64 | 0.87 |
+高分辨率BEV | 69.8 | 92 | 0.75 |
+解纠缠轨迹表示(完全) | 70.5 | 71 | 0.81 |
+生成式规划 | 68.3 | 85 | 0.78 |
关键结论:高分辨率BEV导致成功率下降2.9个百分点,推理延迟提升43.8%;生成式规划使成功率下降4.4个百分点,证实冗余架构模式对闭环性能的负面影响。
5 挑战与未来方向
5.1 核心挑战
- 极端天气鲁棒性不足:当前聚焦常规天气场景,雨雾、强光等极端天气下,紧凑BEV特征的感知精度可能下降;
- 长时域规划能力有限:主要优化1-3秒短期轨迹,5秒以上长时域规划(如长距离变道)的稳定性仍需提升;
- 交互场景适配待强化:对多车博弈、行人横穿等复杂交互场景,全局语义关联的建模深度不足;
- 多传感器融合缺失:仅依赖相机输入,未整合LiDAR、雷达数据,低能见度场景鲁棒性受限。
5.2 未来方向
- 极端天气适配:增强BEV编码器的抗噪声能力,引入天气自适应特征增强模块,提升极端环境感知精度;
- 长时域规划优化:引入时序注意力机制,扩展规划时域至5-10秒,强化长距离路线的连贯性与安全性;
- 交互感知增强:在BEV注意力中融入交通参与者的交互意图建模(如前车减速=可能让行),提升复杂交互场景决策能力;
- 多传感器融合扩展:整合LiDAR点云与雷达信号,丰富BEV特征的几何与距离信息,适配低能见度场景;
- 跨区域法规适配:优化导航指令与交通规则的语义对齐,支持不同国家/地区的交通法规与驾驶习惯。
6❓ 核心QA(基于论文内容)
Q1:高分辨率BEV为何在闭环驾驶中表现不佳?
A1:核心原因是“因果混淆”与“注意力冗余”:1. 高分辨率BEV包含大量远处无关区域特征,规划器易学习训练数据中的虚假关联(如特定地标与动作的绑定),而非因果关系;2. Transformer在长序列token上的注意力分配效率低,易出现“关注噪声区域”的异常激活(如图3a中对远处 occlusion 区域的高关注);3. 空间瓶颈通过压缩token数量,强制规划器聚焦核心场景信息,从根源缓解该问题。
Q2:解耦轨迹表示与扩散生成的协同优势体现在哪里?
A2:二者互补解决多模态行为建模的两大痛点:1. 解耦表示(Path+Speed)将横向路径与纵向速度分离,避免纠缠式waypoint的监督模糊(如动态场景中“何时减速”与“往哪拐”的歧义),降低静态违规;2. 扩散生成通过去噪过程覆盖多种合理轨迹(如路口让行的不同时机),避免点估计的“单点偏见”,降低动态违规;3. 联合使用时,解耦表示为扩散生成提供结构化约束,扩散生成为解耦表示补充多模态多样性,达成1+1>2的效果。
Q3:BevAD为何能突破点估计规划器的数据扩展性瓶颈?
A3:关键在于“分布建模”而非“单点回归”:1. 点估计规划器仅学习输出最优轨迹,无法捕捉驾驶行为的完整分布,数据规模扩大后易因分布偏移导致性能饱和;2. 扩散生成规划器学习整个驾驶行为分布,能从大规模数据中挖掘更多细粒度模式(如不同场景下的让行策略);3. 轻量架构设计降低了训练开销,支持更大规模数据训练,进一步放大扩散模型的分布建模优势。
Q4:BevAD的纯视觉配置为何能超越LiDAR增强的基线?
A4:核心是“高效感知-规划交互”而非“传感器堆砌”:1. 6相机360°感知提供完整环境覆盖,配合BEV融合能弥补纯视觉的几何精度不足;2. 场景Tokenizer过滤冗余信息,让规划器聚焦有效感知特征,提升信息利用效率;3. 解耦+扩散规划对感知噪声的鲁棒性更强,降低了对LiDAR高精度几何信息的依赖;4. 基线模型虽集成LiDAR,但未优化感知-规划的交互效率,未能充分发挥多传感器优势。
7 总结
核心价值
- 范式校准:首次系统性分析三大核心架构模式对闭环驾驶的联合影响,提出闭环导向的架构设计准则,打破“开环优化=闭环实用”的认知误区,为端到端规划器设计提供统一参考框架。
- 性能突破:BevAD在Bench2Drive闭环基准中实现72.7%的SOTA成功率,同时具备低延迟、高平滑度、优异数据缩放能力,验证了轻量极简架构的实用价值。
- 工程落地友好:纯模仿学习训练、轻量架构设计、无复杂模块,可直接嵌入现有自动驾驶流水线,适配车载实时部署,降低规模化落地成本。
- 研究引领:揭示高分辨率感知、生成式规划等冗余设计对闭环性能的负面影响,为后续端到端驾驶规划器的架构优化划定核心方向,推动领域从“开环性能竞赛”转向“闭环实用导向”。
总结金句
👉 “BevAD以闭环鲁棒性与可扩展性为核心,用系统性架构分析破除冗余设计迷思,靠轻量感知-直接规划的极简范式实现性能-效率-数据友好的三重平衡,首次为端到端驾驶规划器的规模化实用提供了‘架构精简-闭环最优’的完整技术路径。”
8 原论文信息
- 论文题目:What Matters for Scalable and Robust Learning in End-to-End Driving Planners?
- 作者团队:David Holtz、Niklas Hanselmann、Simon Doll、Marius Cordts、Bernt Schiele(Mercedes-Benz AG、Max-Planck-Institute for Informatics, SIC)
- 发表状态:arXiv preprint(cs.CV领域),2026年3月16日,arXiv编号:2603.15185v1
- 核心创新:三大架构模式的系统分析、闭环导向的BevAD轻量端到端架构、纯模仿学习的优异数据缩放能力
- 关键性能数据:
闭环成功率:Bench2Drive基准72.7%(SOTA);
数据缩放系数:0.87(性能随数据量线性增长);
推理延迟:64ms/帧(车载GPU适配);
轨迹平滑度:曲率方差0.043(优于所有对比模型);
- 开源资源:
项目主页:https://dmholtz.github.io/bevad/
文章转载自公众号:具身智能数据挖掘

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)