
自动驾驶领域从来不缺“颠覆性”的概念。从早年的DNN取代传统CV,到BEV+Transformer的鸟瞰统一,再到如今行业里言必称的“端到端”,以及最近开始冒头的“VLA”。
一、 旧王未老:传统模块化架构
在聊颠覆之前,我们必须先理解被颠覆的对象。目前市面上绝大多数量产车(L2+~L3),其底层架构依然是基于“感知-规划-控制”的解耦设计。
1.1 感知:从2D到BEV,再到占用网络
传统感知不再只是简单的目标检测。在基于高精地图的方案中,感知模块的核心任务是构建一个“几何+语义”的局部世界模型。
- 架构细节:目前最成熟的范式是 BEVFormer 及其变体。
我们利用6个相机的原始图像,通过共享的Backbone(如ResNet、Swin-T)提取多尺度特征。
- 通过可变形注意力机制,在预定义的BEV网格上,让每个Query在时间维度和空间维度上聚合图像特征。
- 时序融合:利用历史帧的BEV特征(通常缓存过去3-5帧),通过时序自注意力(Temporal Self-Attention)来获取速度、运动趋势等几何无法直接提供的动态信息。
- Occupancy Network:为了解决长尾异形物体(如翻倒的卡车、路上散落的碎石)问题,我们引入了占用网络。
它不输出“这是车还是人”,而是输出“这个3D体素是否被占据”。
- 这本质上是一个3D语义分割任务,通常采用稀疏卷积(SparseConv)来处理巨大的3D网格数据,输出分辨率常见为 0.2m/voxel 或 0.1m/voxel。
- 痛点:感知输出的结果是“列表式”的(List of Objects)。当我们将这些物体送入下游时,信息瓶颈产生了。感知丢失了“不确定性”和“隐式几何信息”,规划器只能基于感知给出的有限抽象做决策。
1.2 规划:基于搜索与优化的博弈树
- 行为决策:常见的是有限状态机(FSM)。例如:巡航 -> 跟车 -> 变道 -> 避让。为了处理交互场景,我们引入部分可观测马尔可夫决策过程(POMDP),但由于计算资源有限,工业界更多采用基于规则的层次化状态机。
- 运动规划:这是核心。目前最成熟的量产方案是基于二次规划(QP)的时空联合规划。
我们构建一个SL坐标系(Frenet坐标系),将路径规划分解为横向(l)和纵向(s)。
- 路径规划:通过采样候选路径,利用代价函数(Cost Function)选择最优路径。代价包括:偏离中心线代价、碰撞代价、曲率代价。
- 速度规划:在选定路径上,构建一个分段多项式(Piecewise Jerk),在满足加速度、加加速度舒适性约束下,求解一个QP问题,得到s-t曲线。
- 痛点:规则永远写不完。当遇到复杂交互(如中国式无保护左转、人车混行的菜市场路口)时,QP很容易陷入无解,导致车辆在原地“发呆”或急刹。我们戏称“规则是代码,补丁是信仰”。
二、 正在爆发的一体化革命:端到端(E2E)
2023年以后,随着UniAD、VAD等工作的出现,行业开始大规模转向“端到端”。
2.1 什么是真正的端到端?
- 统一BEV表示:不同于传统模块化(感知出一个列表传给规划),UniAD 在特征空间里就完成了所有任务。它通过一个Transformer Decoder结构,将感知、预测、规划统一在同一个特征空间优化。
- Query的贯穿:这是端到端的精髓。我们定义了多种 Query:
- Track Query:负责跟踪物体,建模物体的运动轨迹。
- Motion Query:基于Track Query,利用交互性注意力,建模物体之间的相互影响(例如,车辆A在让行,车辆B在抢行)。
- Planning Query:最终的规划Query,不仅接收感知特征,还通过注意力机制直接与Motion Query交互。
- 损失函数设计:端到端的训练非常困难。我们通常采用多任务损失:
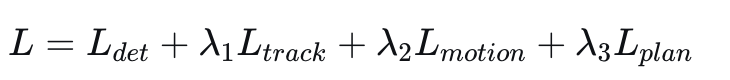
关键在于

的设计。我们不仅要让它拟合人工驾驶的轨迹(模仿学习),还要引入撞损失(让预测轨迹与Occupancy的交集最小化)和舒适性正则项(限制曲率、加速度变化率)。
2.2 训练困境与工程解法
- 数据闭环:端到端模型极度依赖高质量的数据。在传统方案中,感知模型可以用自动化标注。但在端到端中,我们需要的是“决策轨迹”。如果数据里驾驶员在这个路口选择踩油门,而在那个路口选择刹车,模型很难泛化。
- 仿真的鸿沟:在仿真中测试端到端模型极其痛苦。因为传统仿真器是“基于规则”的,但端到端模型输出的是轨迹,两者之间存在“语义鸿沟”。目前业界主流解法是采用 NeRF(神经辐射场) 或 3DGS(三维高斯泼溅) 重建高保真场景,将模型置于其中进行闭环测试。
- 可解释性危机:当车撞上障碍物时,传统方案可以定位“是规划QP问题无解”。但端到端模型出问题,我们只能看到Loss曲线,却很难定位是“感知认错了路沿”还是“规划没理解意图”。为此,我们通常需要在端到端模型中间层强制输出 Intermediate Representation(如显式的Occupancy或Map),用于事后归因。
三、 下一代的想象:视觉语言动作模型(VLA)
传统的端到端模型,哪怕再强,它也不懂“为什么”。它不知道“警车亮起警灯意味着避让”,不知道“路边有人招手可能是要上车”,不知道“前方有积水应该减速”。
3.1 架构演进:从VLM到VLA
VLA 脱胎于多模态大语言模型。其典型架构如下:
- 视觉编码器:使用 SigLIP、DINOv2 或更强大的 InternViT 提取视觉特征,将图像或视频流Token化。
- 投影器(Projector):将视觉特征对齐到LLM的文本嵌入空间(类似LLaVA架构)。
- 大语言模型基座:通常采用 7B 或 13B 参数的模型(如 Qwen2.5-VL、Llama-3.2),负责推理与思维链(CoT)。
- 动作头(Action Head):这是最关键的区别。VLM只能输出文本(“我应该向左打方向”),而VLA需要输出连续动作。我们通常将规划轨迹(Waypoints)离散化或通过专门的 Action Token 输出,转化为控制指令。
3.2 数据飞轮与慢思考机制
- 数据飞轮:传统的端到端模型需要的是“感知-轨迹”对。VLA需要的是 “场景-推理-动作” 对。例如,我们需要标注:“因为前方有事故车辆,且左侧车道空闲,所以我选择变道”。这种高维度的标注成本是天文数字。目前行业主要靠 Teacher Model(利用GPT-4V或更强大的模型对海量数据进行自动化标注生成CoT)来解决。
- 推理机制:VLA引入了 System 2(慢思考)。当遇到Corner Case时,VLA可以利用CoT进行逻辑推理,输出其“思考过程”。但在高速行驶的车辆上,你不能让模型思考1秒钟。所以工业界现在的做法是 “双轨制”:一个轻量级的端到端模型负责90%的常规驾驶(System 1,快速响应),VLA作为 “兜底专家”,仅在检测到不确定性高或异常场景时被唤醒,进行推理并生成决策。
四、 工程师视角的横向对比
为了让大家更直观地理解这三种架构在工程落地中的区别,我将它们从多个维度做了对比:
架构耦合度
传统模块化:低(模块间通过接口解耦,独立迭代)。
端到端:高(特征空间统一,各任务共享主干)。
VLA:极高(语言+视觉+动作联合训练,推理与动作深度耦合)。
可解释性
传统模块化:中(中间结果可视化,易于单模块调试)。
端到端:低(黑盒,依赖仿真回放与特征图归因)。
VLA:高(可输出人类可读的思维链,解释决策原因)。
算力需求
传统模块化:中(通常 20-50 TOPS,可在量产域控运行)。
端到端:高(需 100+ TOPS,依赖Transformer引擎加速)。
VLA:极高(云端训练,车端需强推理卡,目前多用于预研)。
长尾处理能力
传统模块化:差(规则无法覆盖所有场景,新场景需人工写规则)。
端到端:中(依赖数据分布,分布外场景易失效,但泛化性优于规则)。
VLA:优(具备常识推理,能理解未见过的场景语义)。
实时性
传统模块化:优(全链路 < 50ms,流水线并行)。
端到端:中(< 100ms,受模型大小与加速库限制)。
VLA:差(目前 > 200ms,需模型量化、剪枝、甚至“慢思考+快路径”协同)。
维护成本
传统模块化:高(模块多,接口变动影响大,规则代码膨胀)。
端到端:中(单一模型,但数据清洗、版本管理、仿真回归成本高)。
VLA:低(模型化,但数据标注、评测维度、思维链对齐成本极高)。
五、 结语:工程师的务实选择
在写这篇文章的最后,我想说,作为工程师,我们不必盲目追逐热点。
文章转载自公众号:人工智能AI与算法
作者:小蒜子


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)