作者 | 自动驾驶之心团队
编辑 | 自动驾驶之心
2026年3月16日,圣何塞,座无虚席。
450+赞助商、1000场 session、2000位演讲者 ——G TC 2026 的信息密度,大概是普通行业峰会的十倍不止。
如果你只把 GTC 2026 看成一场 AI 行业大会,那大概率会低估它。 因为这次 GTC 的自动驾驶分会场,更像一次关于 “下一代自动驾驶到底该怎么做” 的集体摊牌。
端到端时代,自动驾驶的主线到底是什么?
黄仁勋在台上那句“Everything that moves will eventually be autonomous”,听起来像一句典型的 GTC 式口号。
但当你把四天的分享连起来看,就会发现,这已经不只是口号,而是一份越来越清晰的产业路线图。
大家表面上讲的是不同方案,底层上争的其实是同一件事:谁能先做出真正理解物理世界的驾驶智能。
所以,这也是这次 GTC 最值得写的地方。
笔者不打算讨论芯片路线图和英伟达的股价。这篇文章只关注三件事:各家在 GTC 上到底分享了什么技术、行业共识是什么、作为普通算法工程师我们该怎么办。
一、英伟达的"底牌":平台、模型、数据工厂
在展开各家分享之前,有必要先说清楚英伟达自己端了什么菜上桌。因为这些"基础设施",直接影响了后面每家公司的技术叙事。
DRIVE Hyperion:L4 的"朋友圈"炸了
GTC 2026 最大的商业新闻,是 DRIVE Hyperion 平台的合作阵容集体扩容——比亚迪、吉利、日产、五十铃四家宣布采用该平台开发 L4 级自动驾驶,现代/起亚扩大战略合作覆盖 L2+ 到 L4 全场景,奔驰新一代 S 级搭载 DRIVE AV,支持 L4-ready 架构。
更值得玩味的是出行端:Uber 宣布基于 DRIVE Hyperion 的 Robotaxi 将在 2028 年前覆盖 28 个城市、4 大洲,Bolt、Grab、Lyft 也开始布局。
说白了,从造车到出行,从中国到欧洲,从传统豪华品牌到新能源巨头,NVIDIA 在 L4 这张牌桌上,几乎把能叫的玩家都叫齐了。
图片来源于 NVIDIA 官方
Alpamayo 1.5:开放的"推理型 VLA"
如果说 Hyperion 是硬件底座,那 Alpamayo 就是英伟达在模型层的核心押注。
Alpamayo 1.5 是一个 10B 参数的推理型 VLA(Vision-Language-Action)模型,基于 Cosmos-Reason2 VLM 骨架,经强化学习后训练。它的输入是多路视频 + 自车运动历史 + 导航信息 + 自然语言提示,输出是驾驶轨迹 + 可解释的推理链(Chain-of-Thought)。
关键词有三个:**"开放"(任何人可用、可改、可微调)、"推理型"(不是黑箱,有可解释的思维链)、"长尾"(专攻极端场景)。自 CES 2026 发布以来,已被超过 10 万汽车开发者下载**。
NVIDIA 还提供了完整的后训练脚本(SFT + RL),支持开发者在自有数据上微调——这意味着 Alpamayo 不只是一个模型,更像是一个开放的 VLA 基座,让各家在其之上构建差异化方案。
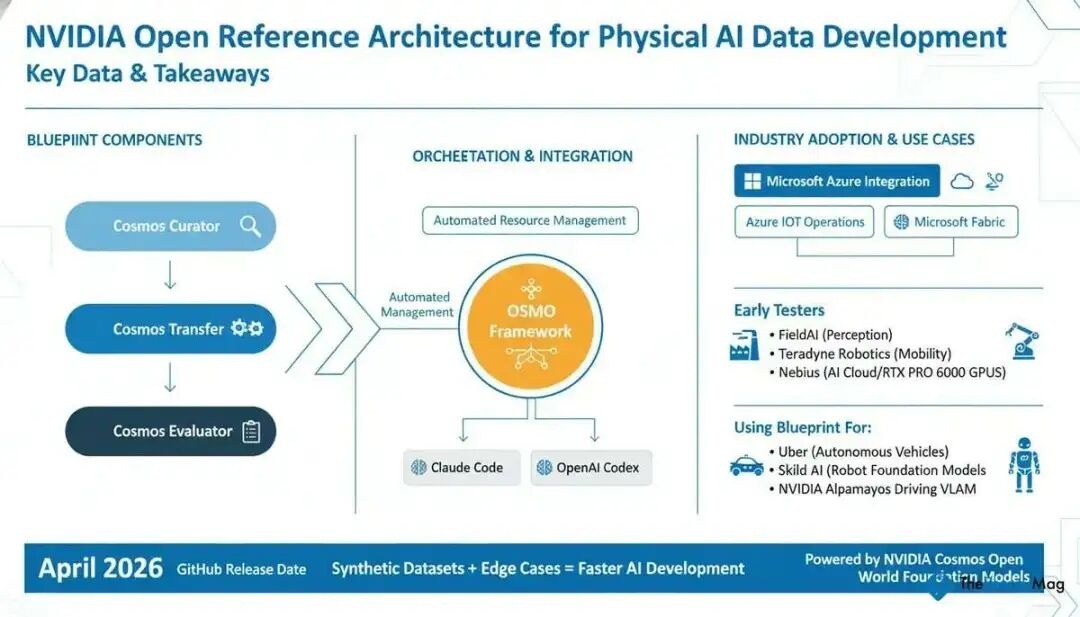
Physical AI Data Factory:"算力即数据"
NVIDIA 副总裁 Rev Lebaredian 在发布 Physical AI Data Factory Blueprint 时说了一句颇有哲学意味的话:**"In this new era, compute is data."**
这个蓝图包含三个核心组件:Cosmos Curator(数据处理/标注)、Cosmos Transfer(数据扩展/多样化)、Cosmos Evaluator(数据评分/验证/过滤)。本质上,它是一套用算力"制造"训练数据的参考架构,目标是用合成数据替代大量真实路测。
与此同时,NVIDIA AI 研究副总裁 Sanja Fidler 宣布:"We have entered the era of generative simulation." 配套的 AlpaDreams 系统可以实时生成多摄像头、物理感知的驾驶场景——这不是渲染出来的假数据,而是能直接用于策略测试的"生成式仿真"。
再加上 NuRec 基于 3D Gaussian Splatting 的场景重建(900+ 重建场景已在 Hugging Face 开放)、1700+ 小时的 Physical AI AV Dataset(新增人工验证的推理标注),英伟达在"数据-仿真-模型"三角关系上,基本补齐了闭环。
笔者的判断:英伟达已经不再只是自动驾驶的"卖铲人"——它在定义整个行业"怎么挖矿"。 从芯片到平台、从模型到数据工厂、从安全架构(Halos OS)到开放生态,它提供的不是一个产品,而是一整套"做 L4 的方法论"。
二、中国军团亮剑:GTC 上的"中国声音"
这次 GTC 2026 中最让笔者惊喜的,是中国公司在技术分享上的集体"亮剑"。不是去凑热闹,不是去站台背书,而是在全球最顶级的 AI 大会上,拿出自研技术框架做系统性分享。
笔者梳理了 GTC China Session 中与自动驾驶直接相关的几场核心分享,逐一拆解。
理想汽车:MindVLA-o1——五大创新构建"物理世界智能"
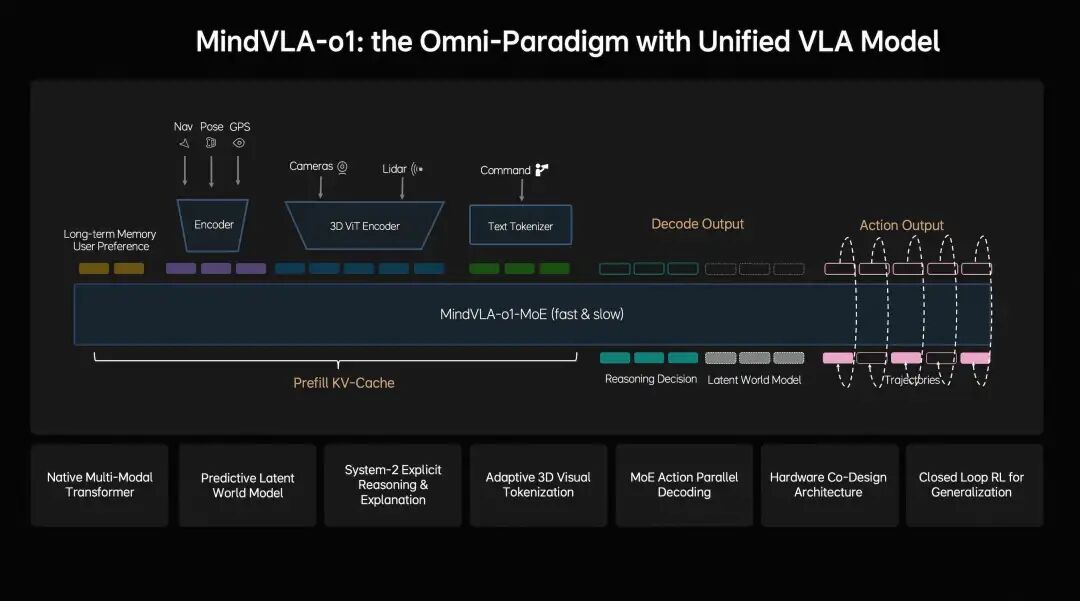
理想汽车基座模型负责人詹锟分享了下一代自动驾驶基础模型 MindVLA-o1,围绕五大技术创新展开:
一是 3D 空间理解。 采用以视觉为核心的 3D ViT Encoder,利用激光雷达点云作为三维几何提示,引导模型理解真实空间结构。同时引入前馈式 3DGS 表示,将场景拆分为静态环境与动态物体分别建模,并通过 Next-state Prediction 作为自监督信号,使模型同时学习深度、语义和运动信息。
二是多模态思考(Generative Multimodal Thinking)。 在语言模型承担语义理解的基础上,引入预测式隐世界模型(Latent World Model),在隐空间中高效模拟未来。训练分三阶段:先用海量视频预训练 Latent World Token,再在模型中持续推演形成隐空间未来推理能力,最后将世界模型、多模态推理与驾驶行为联合训练对齐。理想将这种能力定义为——模型不仅能理解当前场景,还能在隐空间中提前"想象"未来画面。
三是统一行为生成(Unified Action Generation)。 采用 VLA-MoE 架构 + 专门的 Action Expert,从 3D 场景特征、导航目标、驾驶指令等多维输入中提取信息,结合多模态思考生成轨迹。为满足实时性,采用并行解码同时生成所有轨迹点;再通过 Discrete Diffusion(离散扩散) 多轮迭代优化,确保轨迹空间连续、时间稳定且符合动力学约束。
四是闭环强化学习。 构建 World Simulator,将传统逐步重建升级为前馈场景重建,可瞬时生成大规模高保真场景。结合生成式模型扩展新场景,并开发统一的 3DGS 渲染引擎 + 分布式训练框架,渲染速度提升近 2 倍,整体训练成本降低约 75%。
五是软硬件协同设计。 将模型结构与验证损失建模,结合 Roofline 模型刻画硬件约束,评估近 2000 种架构配置,在 Orin 与 Thor 平台上找到模型精度与推理延迟的帕累托前沿,将架构探索时间从数月缩短至数天。
值得一提的是,MindVLA-o1 背后是一套完整的 AI 框架:MindData(数据引擎)→ MindVLA-o1(统一 VLA 模型)→ MindSim(世界模型仿真)→ RL Infra(强化学习基础设施),四大模块形成闭环。量产数据也很扎实:截至 2025 年底,VLA 司机大模型月使用率达 80%,VLA 指令累计使用 1225.4 万次。
詹锟在演讲中说了一句颇有野心的话:"基于同一套 VLA 模型,不仅可以控制车辆,也能够扩展到机器人。自动驾驶只是物理 AI 的起点。"理想是首家在 GTC 公开分享 VLA 模型完整架构的中国车企,这本身就是一个信号。
小米汽车:Reinforced Cognitive——"认知驱动不等于车端部署大模型"
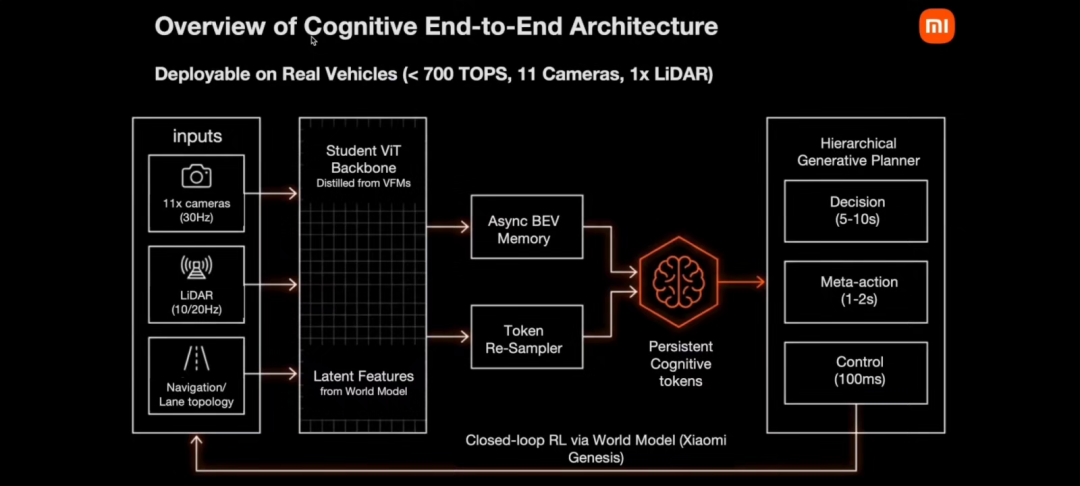
小米汽车辅助驾驶算法和交付负责人陈光分享了 Reinforced Cognitive(强化认知) 端到端框架。开场就点明了一个核心约束:车端算力仅 700-1000 TOPS,需实时处理 11 路 30Hz 高清相机 + 10Hz 前向激光雷达。在这个"铁律"下,小米给出的结论很明确:不在车端部署完整视觉语言大模型,而是将云端大模型认知转化为先验,注入轻量级车端模型。
围绕这一思路,这套框架包含四大核心支柱:
一是认知先验蒸馏。 在云端部署多组视觉基础模型作为"教师",通过跨模态蒸馏向车端"学生模型"注入稠密特征、概念边界、4D 占据网格等感知先验。其中 4D Occupancy 是核心武器——通过蒸馏未来 1-3 秒可行驶空间,让模型从"模仿行为"升级为"理解因果"。陈光举了个生动的例子:路口直行时,纯数据驱动模型易因邻车道车辆停车而错误制动,而注入先验后模型能判断自车前方畅通即可正常通行。
二是时序融合与记忆压缩。 通过异步 BEV 融合机制(运动对齐 → 新数据更新 → 新鲜度门控)实现 30Hz 相机与 10-20Hz 激光雷达的无缝融合;再用 Token 重采样将高维多帧特征压缩为紧凑的"持久化认知 Tokens",跨越秒级时间窗口编码交互意图和盲区风险——用极低算力成本替代 VLM 完成长时序因果推理。
三是层级生成式规划。 三层架构:顶层 Decision(5-10s,宏观意图)→ 中层 Meta-action(1-2s,扩散模型/自回归生成轨迹)→ 底层 Control(100ms,连续细化输出平顺指令)。支持并行候选生成 + RL 奖励快速评估筛选最优方案。
四是强化学习 + Genesis 世界模型。 小米自研的 Genesis 世界模型是业界首个跨模态对齐的多视图视频 + 激光雷达点云联合生成框架,具备高保真场景重建、可编辑环境、反事实数据生成三大能力。更巧妙的是,小米将车队数据中不到 1% 的人类接管数据作为核心监督信号,转化为惩罚与纠错示范投射进仿真器。
笔者认为,小米这套框架最聪明的地方在于它的务实定位:认知驱动 ≠ 车端部署大模型。在其他公司追求把更大的模型塞进车里时,小米选择了"云端赋能、车端执行"的协同路线。这不是技术妥协,而是对量产约束的清醒认知。
卓驭科技:从 VLA 到原生多模态基础模型
卓驭科技陈晓智在 GTC 2026 上系统分享了其智驾基础模型 VLA World Model 的完整技术路线,信息密度远超预期。卓驭一贯以低成本、高可靠性著称,但这次分享表明,它在模型架构层面的思考深度丝毫不亚于任何一家头部公司。
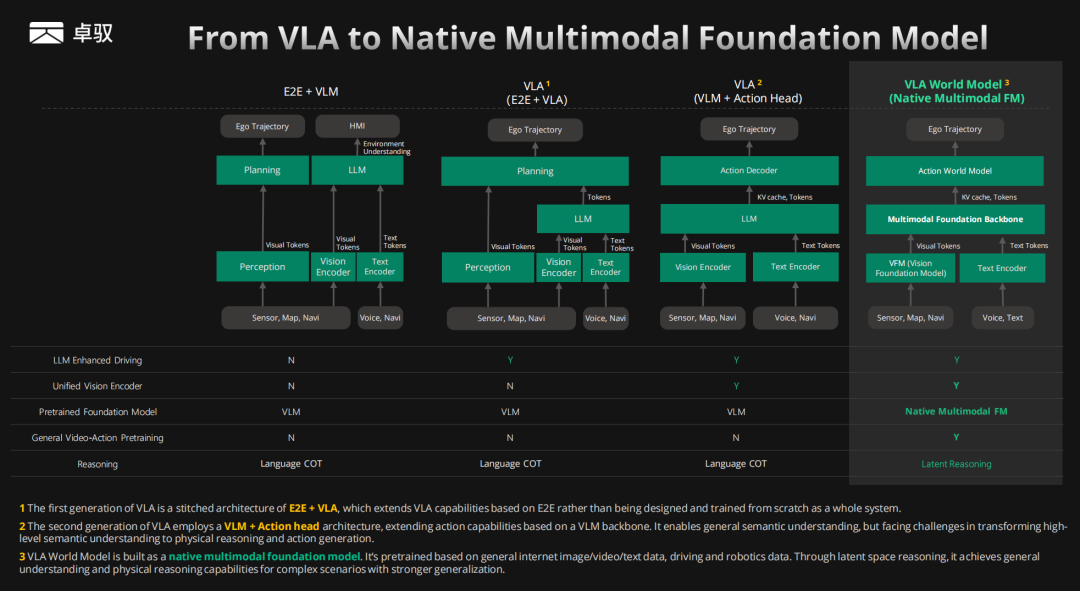
卓驭首先梳理了 VLA 的演进脉络,将其划分为四个阶段:
E2E + VLM:传统端到端模型与视觉语言模型的简单拼接,感知与规划各自独立,无 LLM 增强驾驶能力,无统一视觉编码器,推理依赖语言 COT。
VLA(E2E + VLA):在端到端基础上"缝合"VLA 能力,引入 LLM 增强驾驶,但视觉编码器仍未统一,本质上是在已有 E2E 系统上扩展 VLA,而非从头设计。
VLA(VLM + Action Head):以 VLM 为骨架,外接 Action Decoder 输出驾驶行为,实现了统一视觉编码器和 LLM 增强驾驶,但基座仍是 VLM,缺乏视频-动作联合预训练,推理仍是语言 COT。
VLA World Model(原生多模态基础模型):这是卓驭的核心押注。与前三阶段最大的区别在于三点——基座是原生多模态基础模型(Native Multimodal FM) 而非 VLM;支持通用视频-动作联合预训练;推理方式从语言 COT 升级为隐空间推理(Latent Reasoning)。
这一划分非常有价值:它清晰指出了行业从"模块拼接"到"原生统一"的演进方向,也解释了为什么简单地在 VLM 上加 Action Head 不足以解决深层问题。
而他们的 VLA World Model 架构分为四层:多模态输入层。 支持 8 种模态的高效 Token 化接入:视频、毫米波雷达、激光雷达、导航、地图、文本指令、音频、自车状态。不仅覆盖传统传感器输入,还将导航提示、用户语音命令、外部音频等全部纳入 Token 化体系。基础表征层(Multimodal Foundation Backbone)。 这是整个模型的核心——构建统一的时空世界表征,实现视频、文本、动作等多模态的对齐表示,并具备通用语义理解与 3D Grounding 能力。动作生成层。 在统一的连续隐空间中进行高效推理,经 Future State 预测 → Reasoning 推理 → Action Decoder 解码三阶段,自回归地生成 Ego Trajectory。
训练流程分三阶段:
笔者认为,卓驭的分享细节并不是很多,大多为一些行业共识,咱也说不清内部做的和 ppt 中展示出来的,有多大的 gap。但是不得不说,卓驭这两年单子确实多。
元戎启行:40B VLA——从"工程问题"到"模型问题"
元戎启行 CTO 曹通易的分享,抛出了一个尖锐的判断:自动驾驶撞上的不是算力墙,是"认知墙"。 数据在爆炸,车队在扩大,但系统的进步速度在放缓——端到端并没有带来想象中的跃迁,长尾问题依然顽固。问题不在工程,而在于现有模型更多是"记忆分布"而非"理解世界"。
元戎的解法是:40B 参数的 VLA 模型。这个模型不只是更大,而是从架构上让模型同时承担三种角色:
Driver(驾驶员):输出驾驶行为
Analyst(分析师):解释当前场景和决策依据
Critic(评估者):评估行为优劣
在预训练阶段,元戎没有沿用轨迹监督,而是转向视频预测——当模型被要求预测未来帧时,它必须学习物体运动、空间关系和因果逻辑,训练目标从"模仿行为"转向"建模世界"。进入 Midtrain 阶段,三个角色被同时训练,并通过 "Learning to Explain" 任务强制模型用自然语言描述场景和决策依据——能说清楚,才意味着真的理解。
推理阶段则抽象为 Observe → Reason → Act 三步:视觉输入编码为 Token,经过推理生成决策逻辑,再转化为控制指令。自动驾驶第一次有了类似"思考过程"的中间层。
更深层的变化在数据闭环:Foundation Model 重构了整个流程——数据挖掘、接管分析、标注、质量评估全部由模型完成,而非人工驱动。这让系统开始具备"自我进化"能力:模型越强,数据处理能力越强;数据越多,模型又进一步提升。
量产侧,元戎已实现超 20 万辆城市 NOA 量产交付,计划 2026 年达百万级。40B 模型如何部署是工程问题,但曹通易的判断很明确:这些问题不再决定上限,只约束落地节奏。
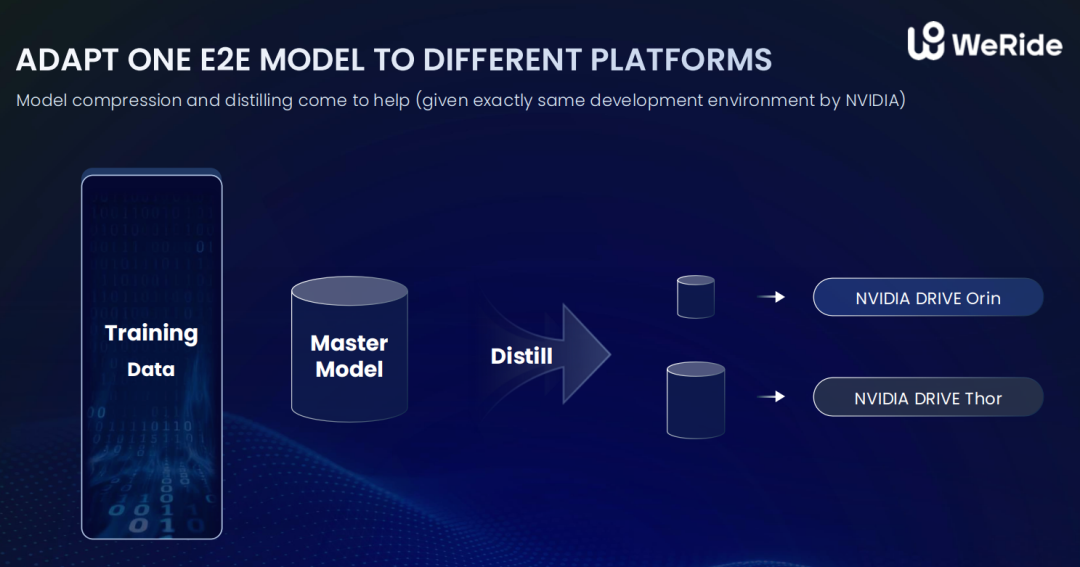
文远知行:双 Thor + GENESIS,从 L2 打到 L4
文远知行资深副总裁钟华分享了一套从 L2 到 L4 贯通的端到端部署方案。
技术亮点在于:
双 DRIVE Thor 芯片的 HPC 3.0 高性能平台,专为 L4 端到端推理和多任务并行设计
云端训练 + Thor 车端推理的协同架构,贯通云到车
自研仿真平台 WeRide GENESIS,集成 Smart Agent、视频生成、风格迁移等能力,可快速生成多视角传感器数据与长尾场景
BTW, 文远的"双 Thor + GENESIS"方案,是目前公开信息中最详尽的 NVIDIA Thor 在 Robotaxi 场景落地的技术描述。
三、Wayve 与全球 Robotaxi 阵营:另一种"端到端"叙事
中国公司之外,还有一条不容忽视的技术线索——Wayve。
这家英国公司在 GTC 2026 前完成了15 亿美元 D 轮融资,并与日产、Uber 联合展出了基于日产 LEAF 平台的 Robotaxi 原型车。硬件配置是双 DRIVE AGX Thor + 360 度摄像头 + 环绕雷达 + 前向 LiDAR,软件层则是 Wayve 自研的 AI Driver——一套端到端 AI 驾驶系统,不依赖高精地图。
计划是 2026 年底在东京启动试点,逐步扩展到 10+ 城市。
Wayve 的路线与中国方案有一个有趣的差异:它更强调 "embodied AI" 的概念——不是把自动驾驶做成一个工程问题去堆模块,而是训练一个能"理解物理世界"的 AI 系统,让它学会开车。这与 NVIDIA 自身的 Alpamayo 理念高度一致。
再加上 Uber 28 城的 Robotaxi 计划,以及奔驰 S 级 L4-ready 的量产方案,L4 自动驾驶正在从 PPT 中的愿景,进入商业落地的前夜。当然,中国的公司在 L4 也未掉队,小马,文远,百度,都已交出不错的战绩,也有想哈啰这样的新鲜血液,L4的商业化的黎明来了!
四、五个"行业共识":横向对比之后,我们看到了什么
把上面所有分享放在一起做一次横向扫描,有五个趋势浮出水面:
共识一:端到端成为绝对主流。 从理想到小米,从卓驭到元戎再到文远,几乎每家的分享都围绕"端到端"展开。从感知到决策的一体化模型,已经不是"要不要做"的问题,而是"怎么做得更好"的问题。模块化的上一代架构,正在被快速替代。
共识二:VLA 统一架构成为新范式。 理想的 MindVLA-o1、卓驭的 VLA World Model、元戎的 40B VLA、NVIDIA 的 Alpamayo,多家背景迥异的公司殊途同归——都在用 Vision-Language-Action 的统一架构做自动驾驶。VLA 不再是论文里的概念,它正在成为行业的"通用语言"。
共识三:世界模型 + RL 成为技术新组合。 理想的隐世界模型 + 闭环强化学习、小米的 Genesis 世界模型 + RL 框架,不约而同地走向了"世界模型用于想象 + 强化学习用于优化"的技术组合。卓驭也将隐空间推理作为其 VLA World Model 的核心推理方式。这代表了一种更高阶的追求:模型不仅要会"反应",还要会"想象"和"推理"。
共识四:开放模型成为主旋律。 黄仁勋在开放模型圆桌上说了一句很有意思的话:**"Proprietary versus open is not a thing. It's proprietary AND open."** Alpamayo 的开放后训练、1700+ 小时数据集的开源、Cosmos 世界模型的开放——英伟达在用实际行动推动"开放 + 专有并行"的模式。
共识五:仿真数据工厂正在替代真实路测。 "生成式仿真时代"——Sanja Fidler 的这句话,可能是 GTC 2026 上被低估的最重要判断。当 NuRec 可以从真实数据重建仿真场景,当 AlpaDreams 可以实时生成物理感知的驾驶环境,当理想构建了前馈式 3DGS 世界模拟器、小米自研 Genesis 世界模型、文远推出 WeRide GENESIS 仿真平台——**"采集车跑一万公里"的时代,正在被"GPU 算一万小时"取代。**
五、聊聊我们自己:接下来怎么办
说了这么多行业和公司的事,最后还是想聊回我们自己。
坦白讲,看完这些分享,笔者心态挺复杂的——一方面觉得方向越来越清晰了,另一方面也很难不焦虑:技术迭代这么快,我们到底跟不跟得上?
焦虑归焦虑,但坐着也不是办法。以下是笔者看完 GTC 之后给自己列的几条 TODO,跟大家分享一下,也算互相打打气。
VLA 这棵技能树,得开始点了。 不是说看几篇论文就行。Alpamayo 1.5 开源了、后训练脚本有了、1700+ 小时数据也摆在那——从跑通推理到 SFT 微调,到 RL 后训练,到车端部署,整条链路都能自己上手。笔者自己也在啃,说实话,动手跑一遍比读十篇综述涨的功力多。
RL 的重要性,被严重低估了。 小米的 Reinforced Cognitive、理想的 RL 闭环、Alpamayo 的 RL 后训练——强化学习在自动驾驶里的戏份越来越重。但真正难的不是算法本身,而是怎么设计奖励函数。"安全-合规-效率-舒适"这四个维度怎么量化、怎么平衡、怎么防止 reward hacking——搞明白这些,可能比多会一个新架构更有竞争力。换句话说,以后除了"调参侠",可能还需要一批"奖励工程师"。
仿真能力,真的该补了。 "算力即数据"不再是口号。NuRec 的 3D Gaussian Splatting、AlpaSim 的开源框架、理想的前馈式 3DGS 世界模拟器、小米的 Genesis 世界模型——这些工具和方法都已经触手可及。笔者有个直觉:再过两年,会做仿真的工程师,身价可能和会训模型的不相上下。
别把自己锁死在自动驾驶里。 GTC 上有个容易被忽略的信号:自动驾驶 VLA 和机器人 VLA 正在趋同。NVIDIA 的 GR00T N2(人形机器人"世界动作模型")和 Alpamayo(自动驾驶推理型 VLA),底层架构高度相似。我们在自动驾驶上积累的端到端、世界模型、RL 经验,天然能迁移到机器人领域——反过来也一样。多看看隔壁赛道,说不定哪天就用上了。
最后,别光看,动手。 Alpamayo、Cosmos、Physical AI AV Dataset——英伟达正在把自动驾驶的"基础设施"一件件开源出来。与其刷信息流刷到焦虑,不如挑一个项目跑起来。能跑通、能改、能微调的开放项目,就是最好的学习素材。把手弄脏,比什么都管用。
写在最后
回看 GTC 2026 四天的密集输出,笔者认为最贴切的一个词是 —— 共振。
这不是某一家公司的独角戏。当英伟达拿出 Alpamayo 推理型 VLA,理想系统分享 MindVLA-o1 的五大创新与物理 AI 愿景,小米亮出 Reinforced Cognitive 四大核心支柱,卓驭勾勒从 VLA 到原生多模态基础模型的演进路线,元戎用 40B 参数 VLA 和 20 万辆量产数据说话,文远展示双 Thor 的 L2-L4 贯通方案,Wayve 带着 15 亿美元融资和端到端 Robotaxi 原型车走上展台——整个行业在同一方向上产生了共振。
这种共振带来了效率:技术路线趋同意味着工具链可以复用、人才可以流动、经验可以迁移。但硬币的另一面是:当所有人都在做端到端 VLA,差异化的壁垒到底在哪?
是数据?规模最大的公司未必有最好的数据质量。是算力?英伟达已经把算力做成了标准品。是模型架构?大家正在快速趋同。
或许,真正的差异化不在技术本身,而在于对真实世界的理解深度——哪些 corner case 是致命的、哪些交互模式是文化特异的、怎样的驾驶行为是用户真正需要的。这些东西,不在论文里,不在 GPU 上,只在真实道路的无数个日日夜夜中。
GTC 2026 给出了方向,但没有给出答案。答案在路上 —— 字面意义上的。






'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)