
本篇论文出发点:
传统端到端方法主要专注于模仿专家轨迹,缺乏对环境进行深入理解和推理,尤其是在一些少见或复杂的场景中表现不足。随着视觉-语言模型VLM的发展,视觉语言模型能够拥有大量世界知识并具备推理能力,因此备受关注。在VLM基础上,视觉-语言-动作模型VLA更近一步,将场景理解拓展为"行动",生成自车可执行的轨迹,但当前VLA模型中仍然存在着不少问题:
1.动作生成要么不符合物理约束,要么模型结构过于复杂。一些方法直接用VLM生成文本形式的动作或路径点,但这些结果可能不符合物理规律,甚至出现模态坍缩。为了解决这一问题,有研究引入中间层表示(如元动作或潜在动作token),再交由下游模块生成最终轨迹。但这样要么打破了端到端优化的优势,要么增加了系统复杂度和训练成本。
2.推理方式缺乏灵活性,效率不高。多数方法采用固定推理策略,无法根据场景难度在“直接决策”和“逐步推理(CoT)”之间灵活切换。虽然DriveVLM 提出了双系统方案,但它依赖多个独立模块,导致架构复杂、训练成本高且扩展性受限。因此本文提出AutoVLA解决以上问题
本文主要贡献:
1.提出AutoVLA,一种端到端自动驾驶框架。它将物理动作token直接嵌入预训练的VLM中,从而可以在同一个自回归模型中同时完成推理和决策。
2.结合监督和强化微调,这一统一架构使模型能够根据场景需要,在“直接生成轨迹”和“基于思维链推理”之间自适应切换。
知识点介绍:
本文方法介绍:
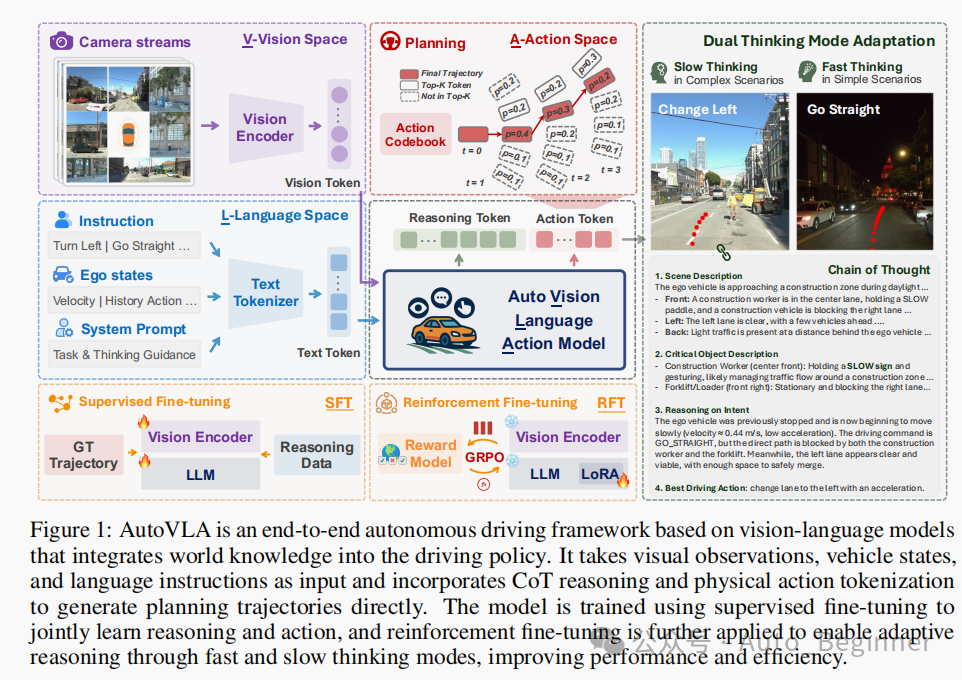
l自适应推理机制:如何实现模型自主决定要何时使用快思考和慢思考(CoT)?通过强化微调
l监督微调(SFT)阶段数据混用(轨迹和CoT混用),给定相同的输入(图像、状态、指令)下,模型既学会直接输出轨迹,也学会先输出CoT再输出轨迹

lCoT数据集构建:本文作者使用了一个更大的模型Qwen2.5-VL-72B自动生成推理注释。整个数据流程附录有写包含四个关键组件:系统提示、用户信息、推理数据生成、人工质检。如下图S2
1.System Prompt:作用:告诉大模型它的角色、任务、CoT 的输出格式,并提供若干示例。
a)CoT 结构被固定为 4 个步骤:
a)场景描述与分析(Scene description and analysis)例如:“前方是一个十字路口,有行人正在横穿……”
b)关键目标识别与描述(Critical object identification and description)例如:“右侧有一辆正在变道的车辆,车号xxx”
c)周围目标的意图推理(Intention reasoning of surrounding objects)例如:“这辆车可能想插到本车前方”
d)决策与元动作(Decision-making and meta-action)例如:“本车应减速让行,然后继续直行”
e)这样设计是为了让推理过程结构化、可预测,便于后续小模型学习。
2.用户消息(User Message):输入内容包含导航指令,自车状态还有多视角图像。关键技巧:在用户消息中显式加入从原始数据中提取的“真实元动作”(ground-truth meta-action),例如“实际驾驶中车辆在这里选择了减速”。这相当于给大模型一个提示(hint),引导它围绕这个真实决策生成因果解释,而不是随意编造。这显著减少了无意义输出,也降低了人工修正的工作量。

总结:
1.好的:
a)统一建模(Reasoning + Action)非常干净,确实解决了架构割裂问题
b)自适应推理,使用价值很高,很多工作一味强调CoT,没有关注过实际的推理延迟
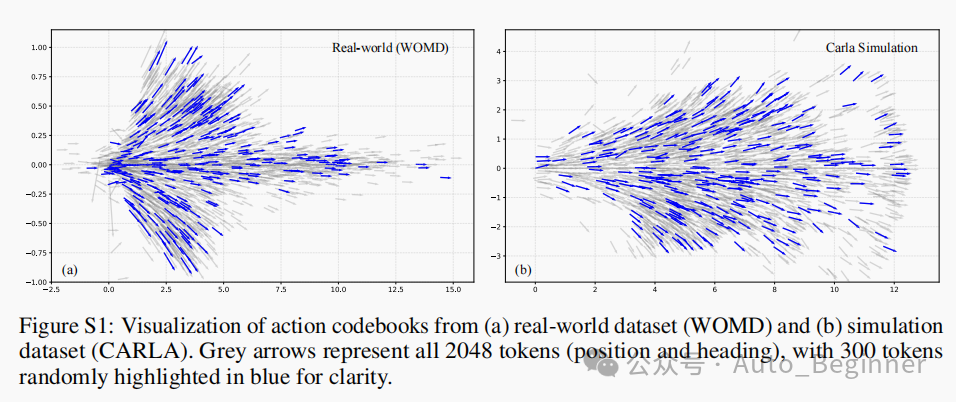
2.不好的:把连续轨迹量化成2048个token虽然方便接入LLM,但带来两个问题:
a)精度上限受codebook限制(特别是复杂动态场景)
b)泛化到未见动作模式可能受限,比如U-Turn
文章转载自公众号:自动驾驶新视界

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)