
引言
对于使用地平线J6各平台的用户而言,QAT量化感知训练是模型量化部署流程中重要的环节,同时也是量化调优的难点之一。在QAT训练过程中,受模型结构、量化配置、训练超参、硬件特性适配等多因素影响,可能出现训练Loss不收敛、前向反向过程存在NAN/INF异常值、量化精度指标相比校准阶段回退或无法通过QAT训练使指标达标等各类异常问题。
本文作为前序J6平台QAT精度调优教程的补充,总结地平线J6系列工具链QAT训练环节的各类典型异常问题以及定位解决的流程和思路。阅读前,请提前学习J6平台QAT精度调优教程:
- J6 E/M工具链QAT精度调优:https://developer\.horizon\.auto/blog/13132
- J6 H/P工具链QAT精度调优:https://developer\.horizon\.auto/blog/13157
QAT训练问题定位
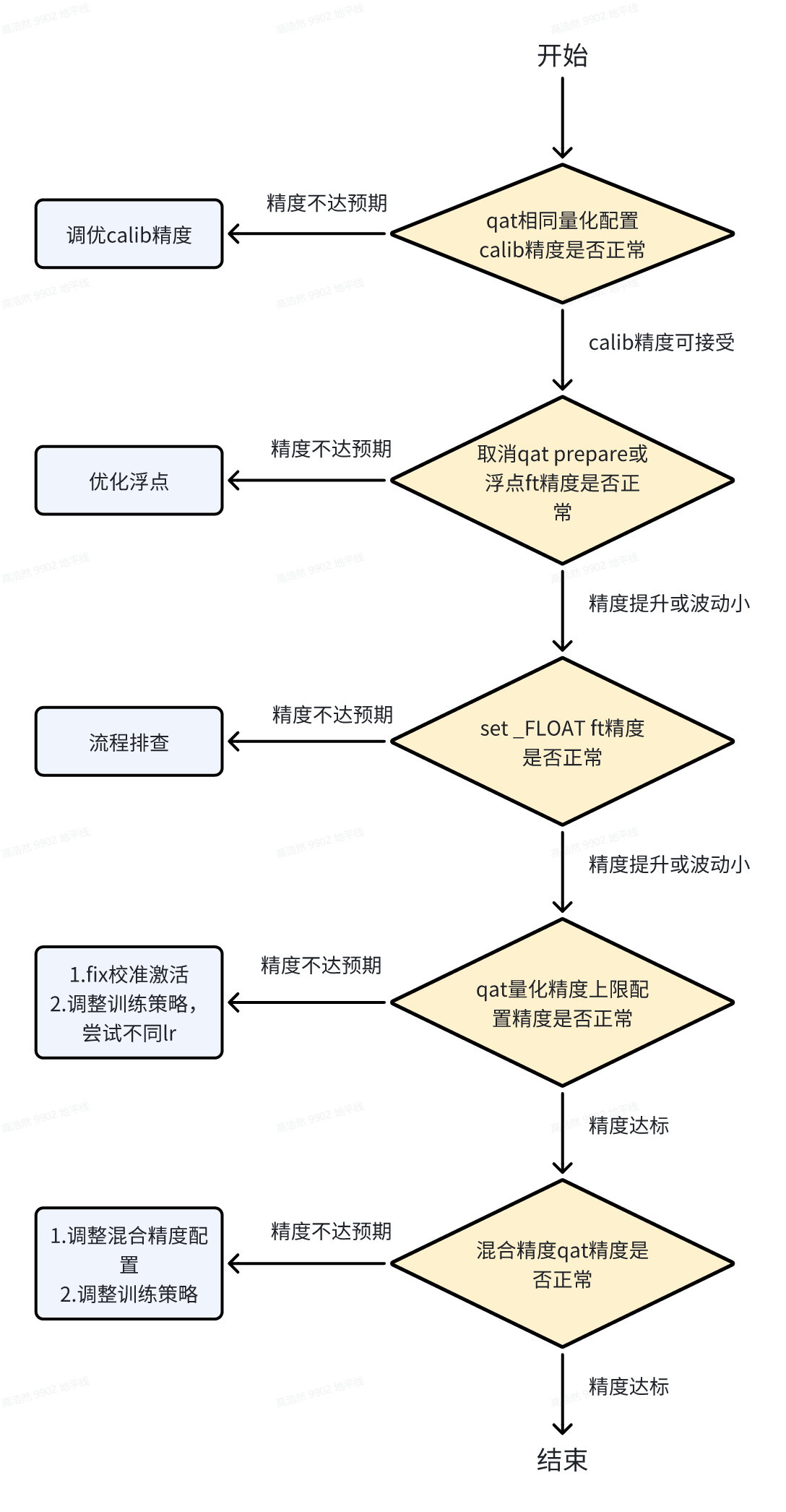
和qat训练相同的量化配置,检查calib阶段精度情况,如calib精度较差则回头通过debug工具定位calib阶段量化问题
在1的基础上,如果calib精度没问题,则取消qat链路的prepare,其他配置不变的情况下对模型做fine-tune,或者直接使用qat链路的参数配置对浮点模型做fine-tune,如指标明显下降则浮点大概率未收敛,优化浮点训练
- 在2的基础上,设置_FLOAT取消伪量化来进行fine-tune,模型相当于未引入量化误差,应和直接fine-tune浮点情况一致,如指标明显下降则需要检查是否qat链路和流程问题。特殊情况: 训练数据分布差异大的情况,训练早期数据可能出现极大值,而plugin工具对部分算子有clip操作进行数值约束,可能造成_FLOAT训练初期精度差的现象,但随着迭代次数增加,_FLOAT精度能对齐浮点
在3的基础上,设置全int16进行qat训练,如果精度指标下降或不达预期,需要结合固定校准激活scale以及with_bn的做法,设置不同lr进行实验
- 在4的基础上,回归到混合精度进行qat训练,如果精度指标下降或不达预期,需要增加更高精度量化的算子,结合固定校准激活scale以及withbn的做法,设置不同lr进行实验。特殊情况: 如果模型中有训练辅助头或者loss计算被量化,不符合我们量化适配预期,可能造成全int16下训练精度达标但是混合精度不达标的现象
常见问题和原因
问题现象 | 问题原因 |
|---|---|
J6尝试开启POT量化后,QAT训练指标下降,或训不上去 | pot scale加大了qat fine-tune调优的难度 |
QAT链路去掉prepare qat环节,fine-tune指标就掉 | 浮点权重未收敛,往往取浮点训练中间权重易出现 |
1. Calib指标正常,QAT训练指标下降,越训越低 2. 全int16精度配置,QAT训练指标正常;混合精度配置QAT训练初始loss高,越训越差 | 1. 未按照标准建议流程设计调优实验,如QAT训练未尝试固定Calib阶段的激活scale 2. QAT训练超参学习率未调整到位 3. 训练过程中的训练辅助分支或loss相关计算被量化 4. Calib阶段的精度调优未做扎实,模型有量化敏感算子 |
1. QAT训练前向或反向过程存在NAN/INF异常值 2. QAT训练的Loss值极大,出现异常值 | 浮点模型或者Calib模型中就存在异常值,Calib阶段的精度调优未做扎实,异常值未排查出,一般异常值可能为数据mask操作引入 |
解决思路和方案
浮点模型权重未训收敛,QAT本质也是小学习率fine-tune,指标越训越低
J6B/P的POT策略可以提高部署模型一致性表现以及对性能有收益,但pot scale加大了qat fine-tune调优的难度
对于J6B/H/P,默认int16下开启POT,int8关闭POT;对于J6E/M,默认不开启POT。因此客户侧选择关闭POT再做验证,如果模型为全int量化,建议直接全局关闭POT:
calib阶段通过敏感度定位到具体POT量化敏感算子,针对性优化POT精度。目前未出现过calib pot精度好但是qat pot精度差的现象
- calib阶段的量化精度未做扎实,主要量化问题仍存在:敏感算子误差未解除、INF值或者极大的scale值影响
解决方案:
- 大部分模型进入到qat前calib精度应达到的标准:calib精度至少需要达到浮点的90%,建议达到浮点的95%。结合调优建议https://developer\.horizon\.auto/blog/13132 以及https://developer\.horizon\.auto/blog/13157 ;少数模型calib精度没有达到上述标准但通过qat也可以训回来,需要结合具体模型和case来看,通常来说如果qat训练指标上升但未达标,第一时间仍然是优化calib精度
calib阶段做扎实敏感度分析:
什么是标准的敏感度:
- 敏感度值呈现梯度分布(主要),例如排序前20%算子应贡献80%的量化误差,下面敏感度靠前和最后的值基本一致,为常见的错误敏感度
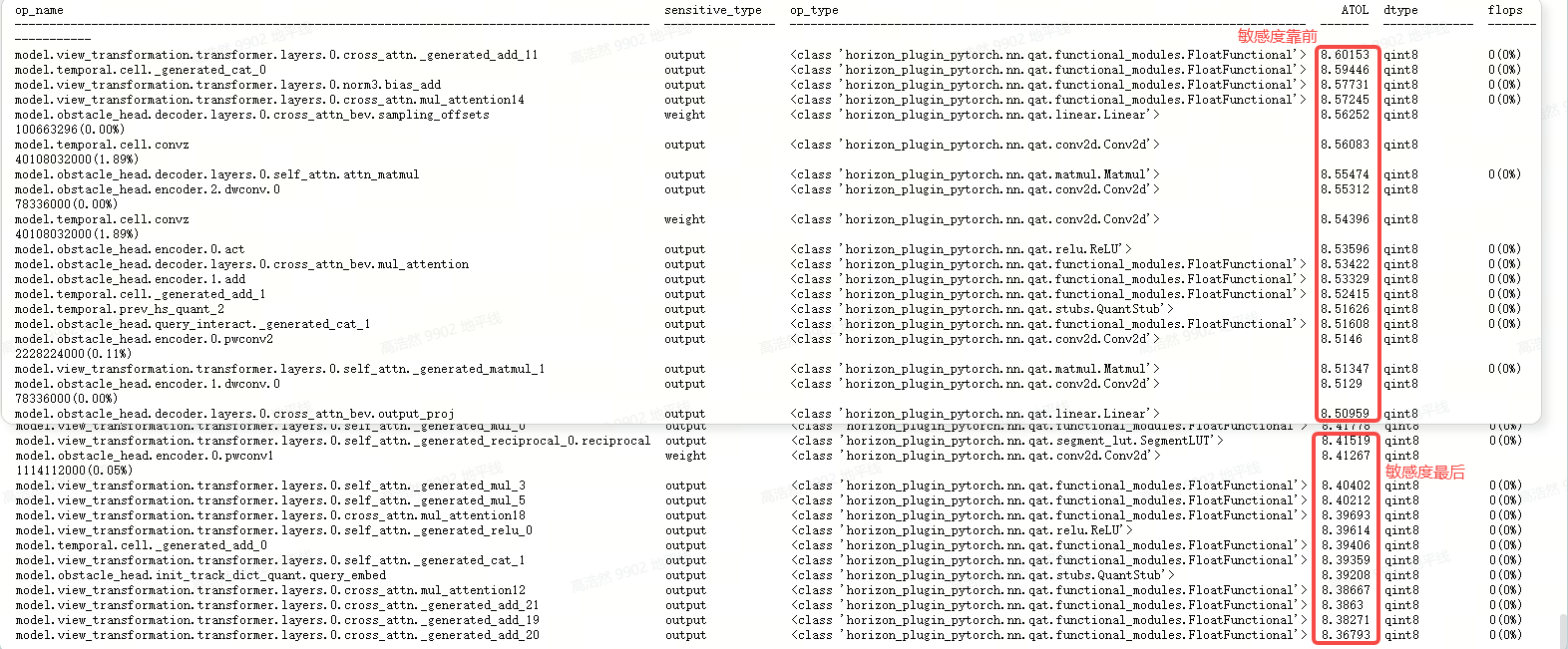
敏感算子分布合理,敏感算子应集中在模型关键结构,例如任务头、多尺度特征融合模块、backbone高维特征层等,不应该均匀地分布在整个网络
敏感度值的大小取决于模型输出物理特征或者语义特征,以及badcase的典型性,只要敏感度符合上面特征则可以协助我们定位量化问题,不用过多关注敏感度本身的数值量级
模型在badcase上的整体敏感度应高于单算子的敏感度;不同敏感度metric下的排序结果应接近
敏感度不正常时排查和解决方式:
在calib链路正确的前提下,确定analysis_model需要比对的量化结构和baseline_model是可以对的上的,下面提供一种方式
在跑敏感度时检查后处理算子是否正确处理:对于topk、nms、sort和argmax这类算子在跑敏感度时应从forward中去除;对于sigmoid算子在跑敏感度时应加在forward中
检查badcase是否数据异常,是否为校准数据集中的脏数据
对于多类别的回归模型,评测链路的后处理中一般会有根据置信度阈值筛选的操作,例如bbox框通过score按照不同的阈值进行过滤,这部分过滤的操作也需要加入到forward当中进行敏感度分析
异常值或极大scale出现场景和解决方式:
Attn mask、其他数据mask等设定的mask value。优化方式:手动设置较小值
clamp算子未指定最大最小值,或者最大最小值数值过大或过小:
norm算子的拆分算子如mul/input_mean/var_mean,实际对精度的影响需要结合敏感度分析。优化方式:手动截断大数值,以稀疏分布的截断换取更高的量化分辨率;J6P平台尝试设置fp16/fp32高精度,J6M尝试使用QAT训练,来进一步优化舍入误差
gemm(尤其指matmul)层输出。优化方式:数据归一化,增加norm层;有物理含义结合物理含义进行放缩;结合算子支持情况和目标部署平台,切换量化精度,例如int16->fp16、fp16->int16(在某些值域内int16表示范围更大)、fp16->fp32
scale出现nan值:
原因:模型中有tensor包含inf/nan值
定位方式:日志中会打印建议把check_nan_scale打开,打开后可具体找到nan scale出现的代码位置,再逐步定位到inf/nan出现的最开始的位置
案例:参数初始化时未考虑到边界情况,通过添加clamp即可避免出现inf/nan
qat适配过程存在问题,一些辅助头分支或者loss相关计算被量化
解决方案:
关注qat train过程中miss_key/unexpected_key的信息,被量化的辅助头或者loss计算往往会以miss_key形式提醒,大部分情况被显式量化的操作在对比calib和qat各自生成的model_check_result生成物后可被发现
梳理qat train阶段计算图fx_graph调用关系,重点关注模型输出,可使用可视化工具:
对比calib train和qat train过程中生成的fx_graph,重点关注模型任务头输出部分trace到的算子和操作
未按照标准建议流程设计调优实验,未首先采取例如固定校准激活scale、取消warmup、使用较小的固定lr微调等优化手段
解决方案:
qat训练初始loss大或出现异常值,初始精度掉点,应按如下流程设计实验:
检查是否在训练时使用了特殊的数据增强策略例如旋转和马赛克等,应当去除;warmup应当去除
去掉prepare的步骤,用qat pipeline fine-tune浮点,实验是否正常。如异常需检查训练配置如优化器和lr_updater
保留qat的配置,设置_FLOAT或_CALIBRATION_V2(不会引入工具clip误差)状态关闭伪量化节点,实验是否正常,正常精度应基本对齐浮点,则继续固定校准激活scale的实验
固定校准激活scale,lr设置为0,实验是否正常,正常精度应对齐calib
固定校准激活scale,使用较小的固定lr微调,进行实验
qat训练loss收敛慢,精度相比calib无变化(训不上去),实验建议:
优先调整BN状态控制,默认fuse_bn(无需开启sync_bn),安排with_bn的实验(sync_bn对齐浮点训练配置)
取消固定校准激活scale,和固定scale做对比
取消warmup
采取较大的lr
延长qat迭代次数
其他

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)