
COMPACT-VA:自动驾驶长上下文,不是记得越多越好
机构 | NVIDIA Research / The University of Hong Kong
论文标题 | Planning-aligned Token Compression for Long-Context Autonomous Driving
arXiv | 2606.07464v1
关键词 | 自动驾驶 / Vision-Action Model / Token Compression / Working Memory / Conditional VQ-VAE / Q-former / Planning-aligned Compression
前言
端到端自动驾驶模型正在变得越来越像统一的 VA / VLA policy:多相机图像、历史轨迹、地图/语义提示被组织成一串 token,送进一个 Transformer backbone,再直接输出未来轨迹。
COMPACT-VA 的核心判断是:自动驾驶需要的 token compression,不只是为了省算力,而是要学会保留对规划决策有用的历史。换句话说,压缩目标必须和 stop / yield / proceed 这类驾驶意图绑定。
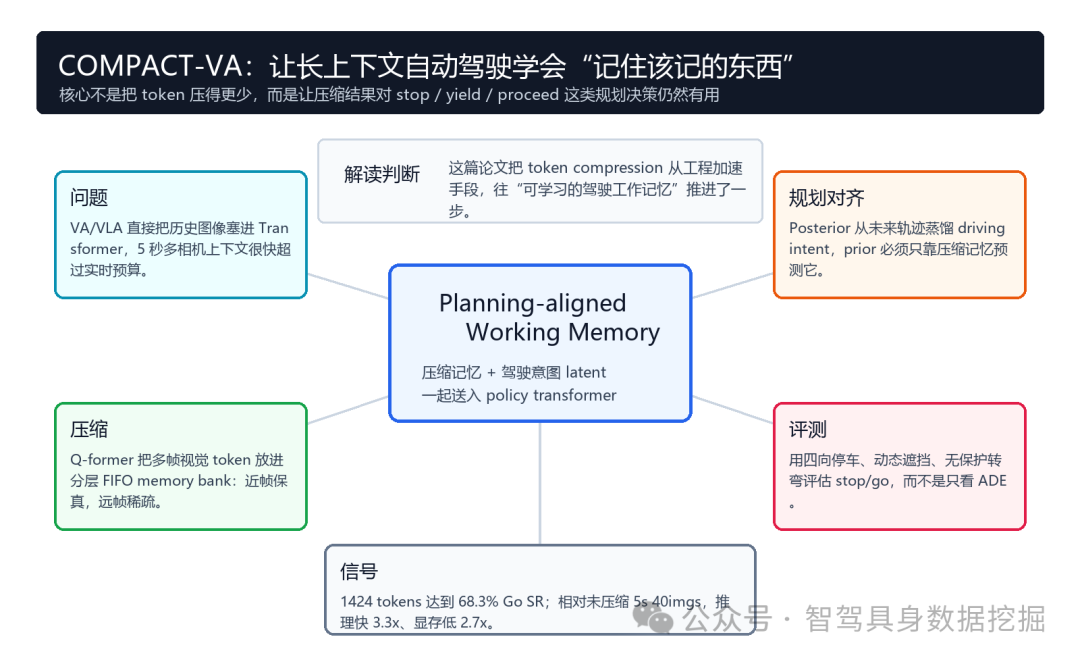

图 1:从有限上下文到规划对齐记忆。在 all-way stop 场景中,判断路权需要观察更长时间;2 秒时间窗口会丢掉 -3 秒处“对方先到”的信息,COMPACT-VA 通过 driving intent 约束压缩记忆,保留这类决策关键线索。
为什么普通压缩不够
对于统一 VA policy,历史 token 数量增长非常直接。若有 T 个时间步、Ncam 个相机、每张图 Nimg 个视觉 token,原始 token 数就是:
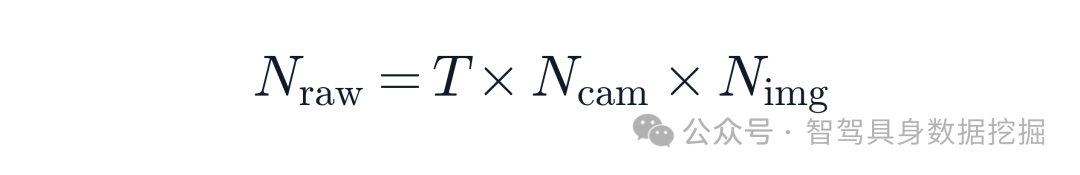
这意味着时间一长,注意力成本会快速变得不可部署。传统做法可以用 temporal decay:近处多留,远处少留;也可以 sparse sampling:把历史采样稀一点。但这些规则有一个共同问题:它们不知道什么信息对驾驶决策关键。
在 all-way stop 里,-3 秒处“谁先到”的线索可能比当前画面里某些纹理 token 更重要;在遮挡场景里,刚刚消失的交通参与者可能比当前画面里的背景更重要。规则压缩无法判断这一点。
这篇论文真正要解决的不是长上下文本身,而是长上下文里的因果线索如何在有限 token budget 里留下来。
分层记忆:先把 token 数压到可用范围
COMPACT-VA 先用一个分层 temporal buffer 管理历史。T 个时间步被划成 K 个压缩层,每层 Lk 包含 nk 帧,并对应一个累计压缩率 rk。压缩后的 token 数写成:
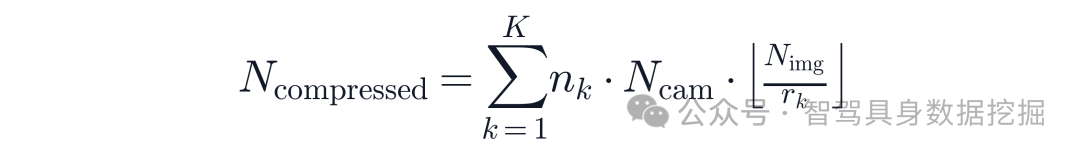
实验配置里,模型使用 5 秒历史、20 个时间步、2 个相机、每张图 160 个视觉 token。未压缩时是 6400 个视觉 token;分层压缩后变成 1424 个 token,约 4.5 倍压缩。
这个分层策略符合驾驶直觉:最近几帧保留高分辨率,因为它们和当前动作直接相关;中间帧适度压缩;更远帧强压缩,只保留足够支撑行为判断的线索。
但这里还只是“怎么压”。COMPACT-VA 更关键的是下一步:让模型知道“该压出什么”。
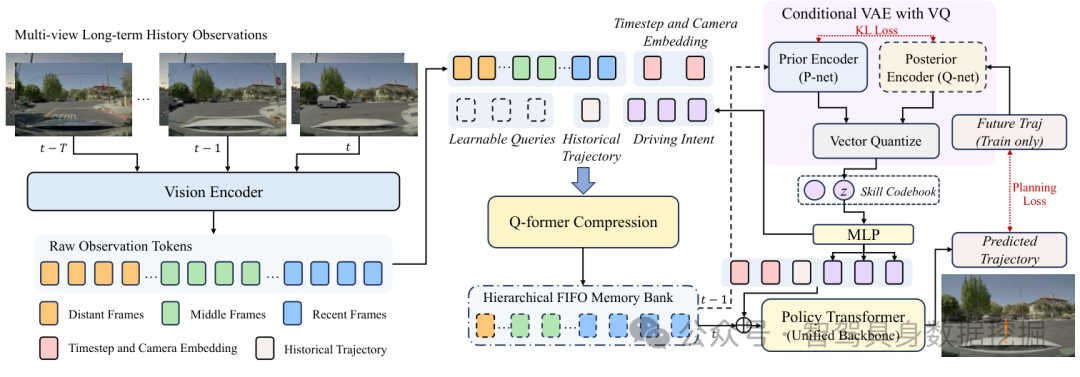
图 2:COMPACT-VA 总体架构。多视角历史 observation tokens 经 Q-former 压缩,posterior encoder 在训练时从未来轨迹蒸馏 intent,prior encoder 则只从压缩观测中预测 intent;压缩记忆和 latent 一起送入 policy transformer。
规划对齐:用未来轨迹反过来教模型记忆
论文把压缩和规划通过 conditional VQ-VAE 绑在一起。训练时有两条路径:
Posterior encoder
可以看未来轨迹,从真实 future trajectory 里提取 driving intent。
Prior encoder
不能看未来,只能从压缩后的历史观测里预测同一个 intent。
两者可以写成:
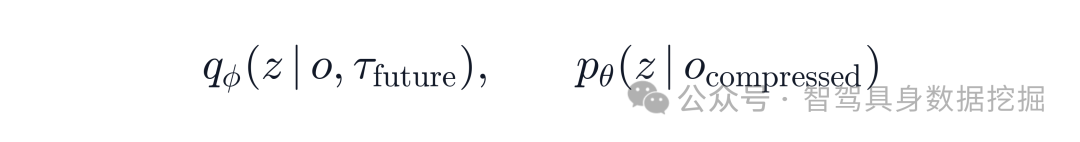
随后,latent 会通过 VQ codebook 离散化,得到一个 skill embedding:
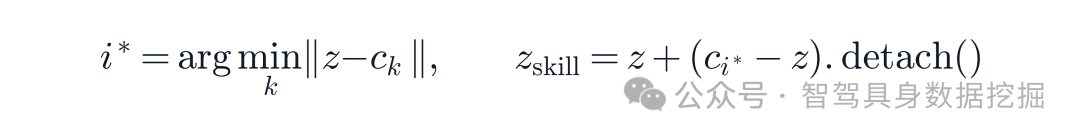
最终训练目标由轨迹预测损失、KL 对齐损失和 commitment loss 组成:
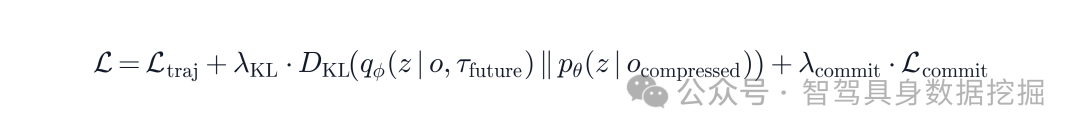
这里最妙的一点是:policy 在训练和推理时都使用 prior 侧的 latent,而不是训练时偷看 posterior。这样做避免了训练/推理不一致,也把压力真正传回压缩模块:压缩记忆必须足够支持 prior 预测 intent。
这就是“planning-aligned token compression”的含义:压缩不是独立模块,而是被轨迹预测任务约束。模型不是学习保留视觉上好重建的信息,而是学习保留规划上不能丢的信息。
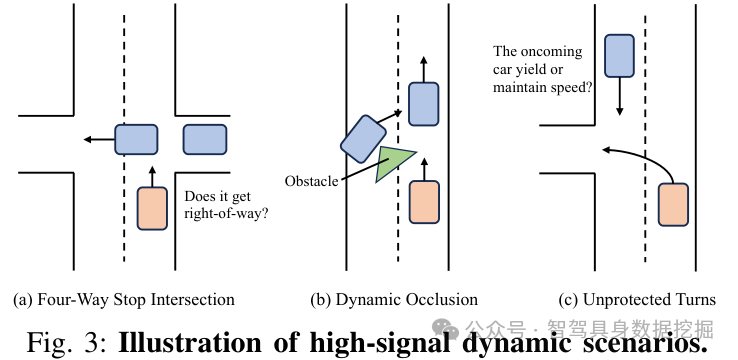
图 3:三类高信号动态场景:四向停车、动态遮挡、无保护转弯。这些场景的关键不是轨迹拟合,而是 stop / yield / proceed 的离散决策是否正确。
评测设计:不要只看 ADE
这篇论文的评测部分也很值得看。作者没有只用 minADE 这类轨迹拟合指标,因为在 stop-controlled intersection 里,ADE 可能会误导。
例如,一个 rolling stop 的轨迹可能和人类驾驶很接近,minADE 不一定高,但它是交通规则和安全层面的错误;反过来,车辆正确停车但晚了一点,ADE 可能较高,但决策更安全。
Go SR
:该走时是否能及时走。
Stop SR
:该停时是否真的停到速度阈值以下。
Roll-through Rate
:是否出现 rolling stop。
Stop Position Error
:停车位置和 stop line 的偏差。
Stop Duration Error
:停车时长是否接近真实驾驶。
这组指标和论文问题是对齐的:如果长上下文记忆真的有用,它应该提升的是路权判断、遮挡推理和 gap acceptance,而不仅是让轨迹曲线更像。
结果:不是更多 token,而是更会记忆
表 I 是整篇论文最关键的结果。几个数字值得放在一起看:
- Standard Alpamayo:1 秒 8 张图,1280 tokens,Go SR 为 63.8%。
- Sparse long history:5 秒但仍只有 8 张图,Go SR 降到 62.0%。
- Dense long history:5 秒 40 张图,6400 tokens,Go SR 只有 61.9%。
- Compression w/o plan-align:1424 tokens,Go SR 提升到 65.6%。
- COMPACT-VA:同样 1424 tokens,Go SR 达到 68.3%。
这组对比给出的信号很清楚:稀疏采样会丢关键中间帧;不加选择地塞满 6400 个 token,也可能让模型更难做 temporal reasoning;真正有效的是结构化压缩,再加上规划对齐。
同时,COMPACT-VA 把 roll-through rate 从 Alpamayo 的 9.0% 降到 7.0% 左右,相对降低约 22%;Stop SR 也从 86.8% 提升到最高 89.2%。
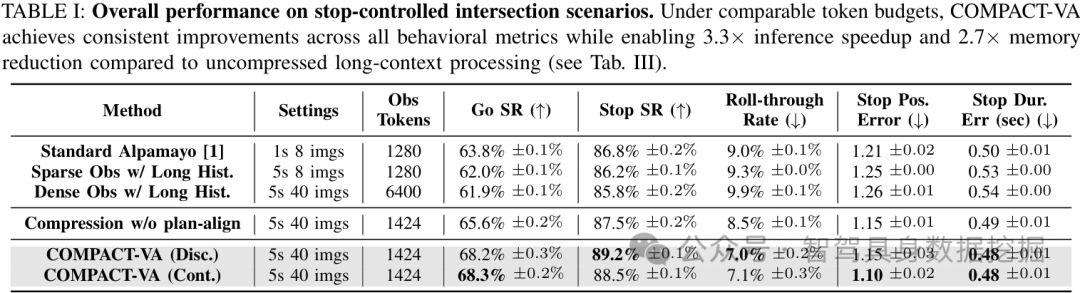
表 I:stop-controlled intersection 场景整体表现。COMPACT-VA 在相近 token budget 下提升 Go SR、Stop SR,并降低 roll-through。
效率:长上下文变得可部署
论文不仅追求正确率,也关心推理成本。表 III 显示,在 Alpasim 中,未压缩 5s 40imgs baseline 的平均推理时间是 1253.52ms,峰值显存 10.51GB;COMPACT-VA 平均推理时间是 377.08ms,峰值显存 3.95GB。
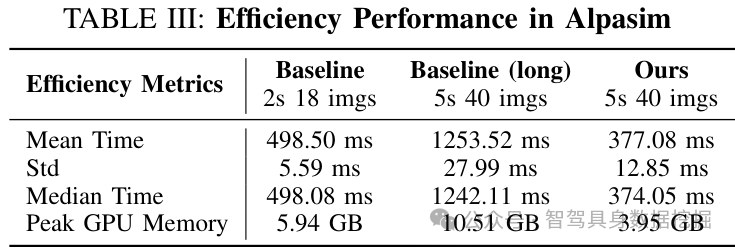
表 III:Alpasim 中的效率对比。相对未压缩 5s 40imgs 长上下文,COMPACT-VA 推理快 3.3 倍,峰值显存降低 2.7 倍。
闭环案例:停车等待也是一种正确规划
图 4 给了一个 all-way sign 右转案例。模型需要识别路口标志,并根据历史判断对向直行车先到,因此 ego 车辆应该停车等待。
这个例子有意思的地方在于,预测轨迹短并不是“不动了”的失败,而是规划决策正确:在当前路权关系下,短轨迹代表 stop-and-wait。
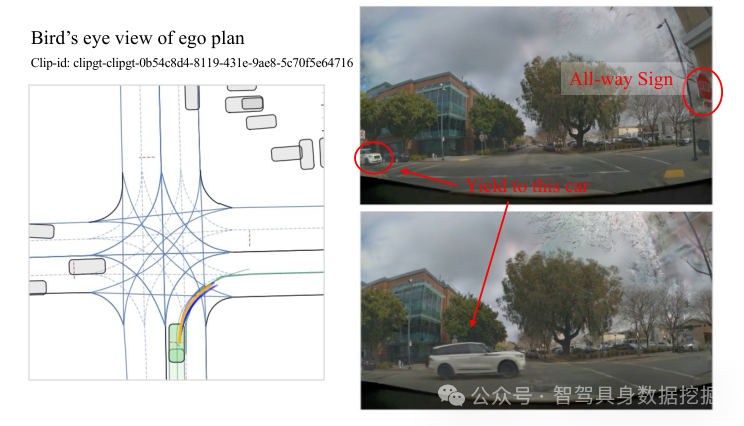
图 4:all-way sign 控制右转的闭环案例。方法识别到 all-way sign,并向先到达的对向直行车让行;鸟瞰图中预测轨迹很短,说明模型选择停车等待。
消融:哪些模块真正起作用
表 IV 逐步加入组件,可以看得很清楚:
- 不压缩、直接用 5s 40imgs,Go SR 是 61.9%。
- 朴素压缩后,Go SR 提到 63.5%。
- 加入历史轨迹 conditioning,Go SR 到 65.6%。
- 再加入 planning-aligned future information,Go SR 到 68.3%。
这说明 Q-former compression 自身有用,但它还不够。真正把记忆从“视觉压缩”推向“驾驶工作记忆”的,是历史轨迹 conditioning 和未来 intent 对齐。

表 IV:架构消融。压缩模块、历史信息、未来/规划信息逐步加入后,Go SR 从 61.9% 提升到 68.3%。
表 V 和表 VI 则回答两个更工程的问题:应该怎么分配压缩率,以及历史是不是越长越好。
结果并不是简单的“越长越好”。5s 40imgs 在 Go SR 上达到 68.3%;继续增加到 60 或 80 imgs,Stop SR / overall 有变化,但 Go SR 并不线性提高。这说明历史长度和模型容量、预训练分布、压缩层分配都有耦合。
这对实际系统很重要:长上下文能力不应该只靠扩大窗口,而应该通过任务对齐的记忆机制,把有限算力用在真正影响决策的线索上。
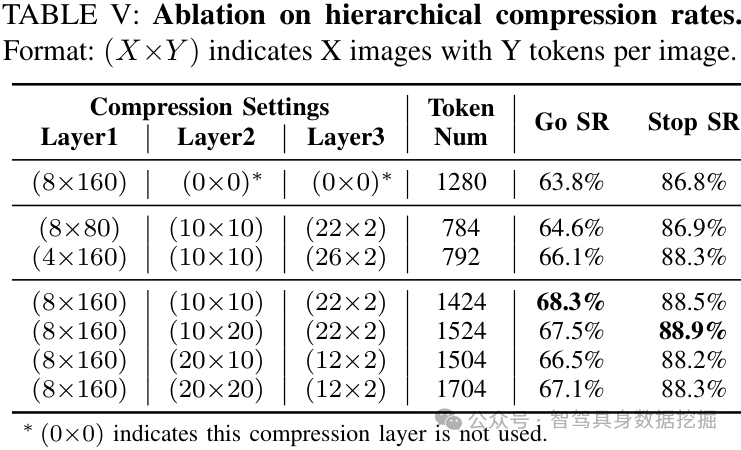
表 V:分层压缩率消融。最近帧保留完整 token、更远帧强压缩,是这篇方法的有效配置。
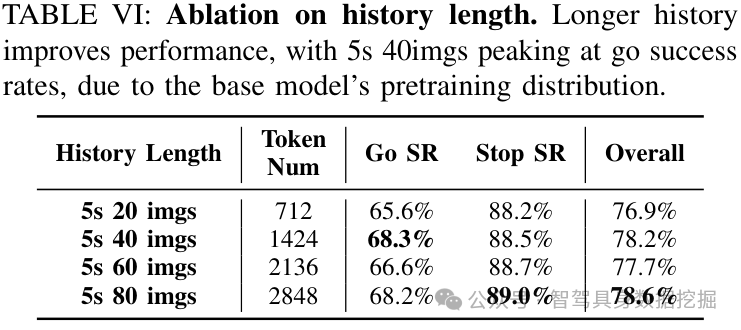
表 VI:历史长度消融。5s 40imgs 在 Go SR 上达到峰值,继续加长历史不一定线性提升。
Skill codebook 有没有学到东西
论文还分析了 VQ codebook 的使用情况。为了稳定统计每个 skill 的使用概率,作者用了指数滑动平均:
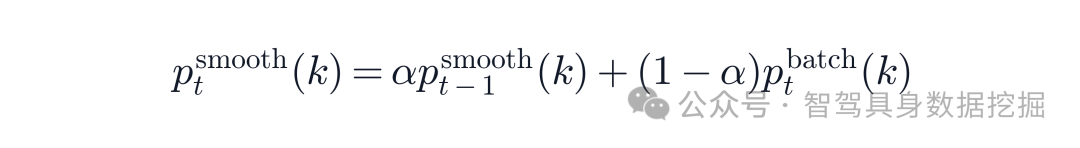
当某个 skill 的 smoothed probability 超过均匀基线 1/K=0.05 时,认为它是 active skill。结果显示,在 K=20 的 codebook 中,模型稳定激活 15-17 个 skill,约 80% codebook utilization。
这说明 latent 不是装饰性的 token。它确实在离散化不同驾驶意图,没有明显 mode collapse。
结论
COMPACT-VA 的价值可以拆成三点:
第一,它把长上下文自动驾驶的问题,从“能不能塞更多 token”改成“能不能学会工作记忆”。
第二,它用 conditional VQ-VAE 把压缩和未来轨迹意图对齐,让压缩模块为规划服务。
第三,它用 stop/go/roll-through 这类行为指标验证记忆是否真的影响驾驶决策。
这也让 COMPACT-VA 和一般 token compression 拉开了距离。它不是只想把 Transformer 跑快,而是在回答一个更底层的问题:端到端驾驶模型在没有显式世界状态的情况下,怎样形成一个可部署、可学习、对规划有因果意义的工作记忆。
文章转载自公众号:具身智能数据挖掘

'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)