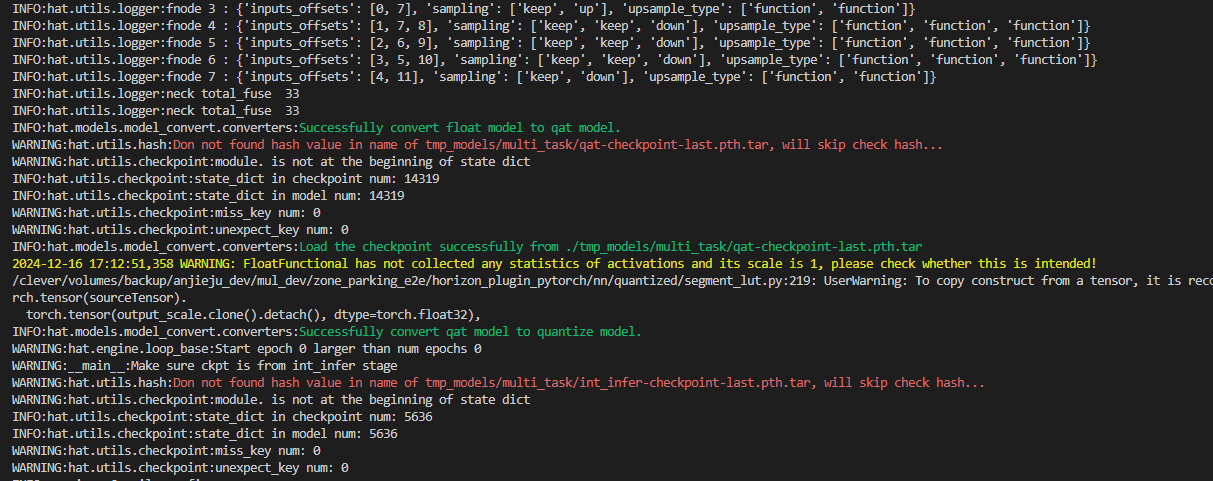
您好,我再compile_perf.py编译模型的时候遇到model中的key丢失问题,具体如附件中的附图所示,
我的deploy model 和int_infer_trainer如下所示:
deploy_model = copy.deepcopy(model)
deploy_model["compile_model"] = True
deploy_model["decoders"][0]["losses"] = None
deploy_model["decoders"][0]["postprocess"] = None
deploy_model["decoders"][1]["target"] = None
deploy_model["decoders"][1]["loss"] = None
deploy_model["decoders"][1]["decoder"] = None
deploy_model["decoders"][2]["target"] = None
deploy_model["decoders"][2]["loss"] = None
deploy_model["decoders"][2]["decoder"] = None
deploy_model["decoders"][3]["target"] = None
deploy_model["decoders"][3]["loss_cls"] = None
deploy_model["decoders"][3]["loss_reg"] = None
deploy_model["decoders"][3]["decoder"] = None
int_infer_trainer = dict(
type="Trainer",
model=deploy_model,
model_convert_pipeline=dict(
type="ModelConvertPipeline",
qat_mode="fuse_bn",
converters=[
dict(type="Float2QAT", convert_mode=convert_mode),
dict(
type="LoadCheckpoint",
checkpoint_path="./tmp_models/multi_task/qat-checkpoint-epoch-0000-4bce8b75.pth.tar",
allow_miss=True,
ignore_extra=True,
),
dict(type="QAT2Quantize", convert_mode=convert_mode),
],
),
data_loader=None,
optimizer=None,
batch_processor=batch_processor,
num_epochs=0,
device=None,
callbacks=[ckpt_callback],
)
我在deploy model的时候把模型decode出目标和loss部分去掉了,这部分是没有参数的。我不明白附件中图的丢失情况是否正常,如果不正常丢失的是我置为None部分的参数吗?
但是那部分就是一些解码模型输出的python代码,并没有参数。我该如何解决这个问题呢?


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)



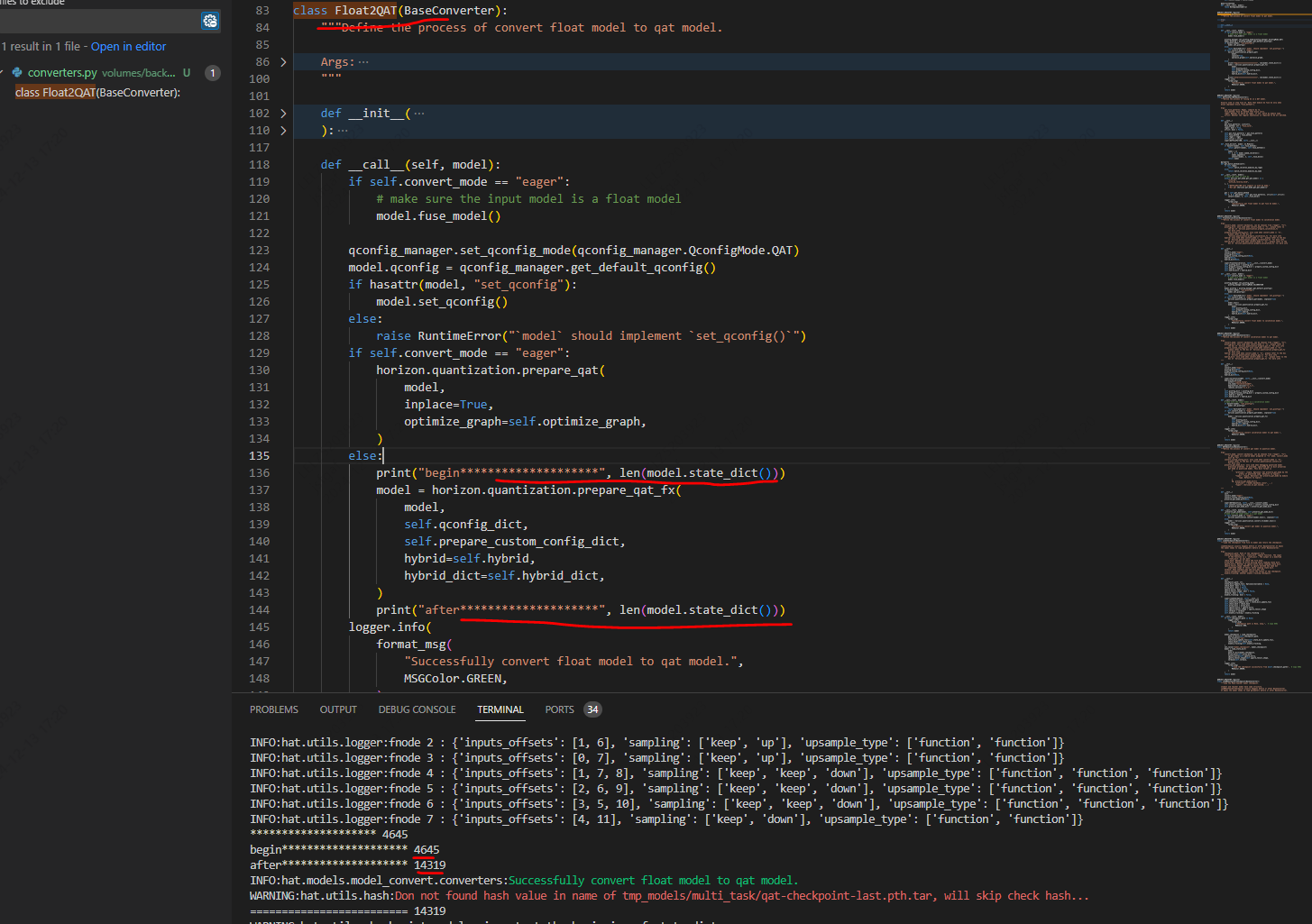
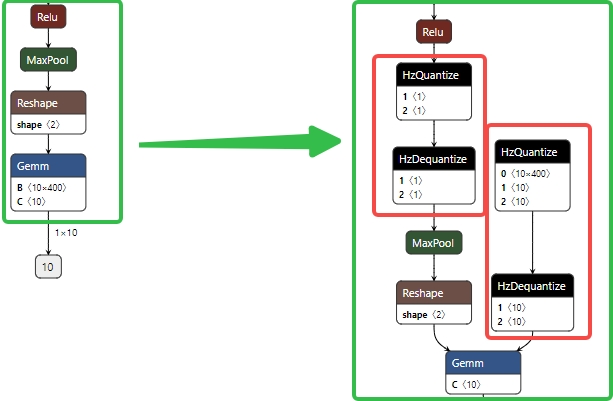 2.伪量化节点是自动插入的,工具链会自动分析哪些节点需要量化。从工具链逻辑看, fuse_model 是在“eager”mode时才会使用的,“fx”mode下会自动融合可以融合的节点。当然量化config都是需要的。
2.伪量化节点是自动插入的,工具链会自动分析哪些节点需要量化。从工具链逻辑看, fuse_model 是在“eager”mode时才会使用的,“fx”mode下会自动融合可以融合的节点。当然量化config都是需要的。