hihi, 我完全按照帖子
地平线开发者社区做了,我的原始nuscenes 数据目录严格按照贴子,,但任然报错:
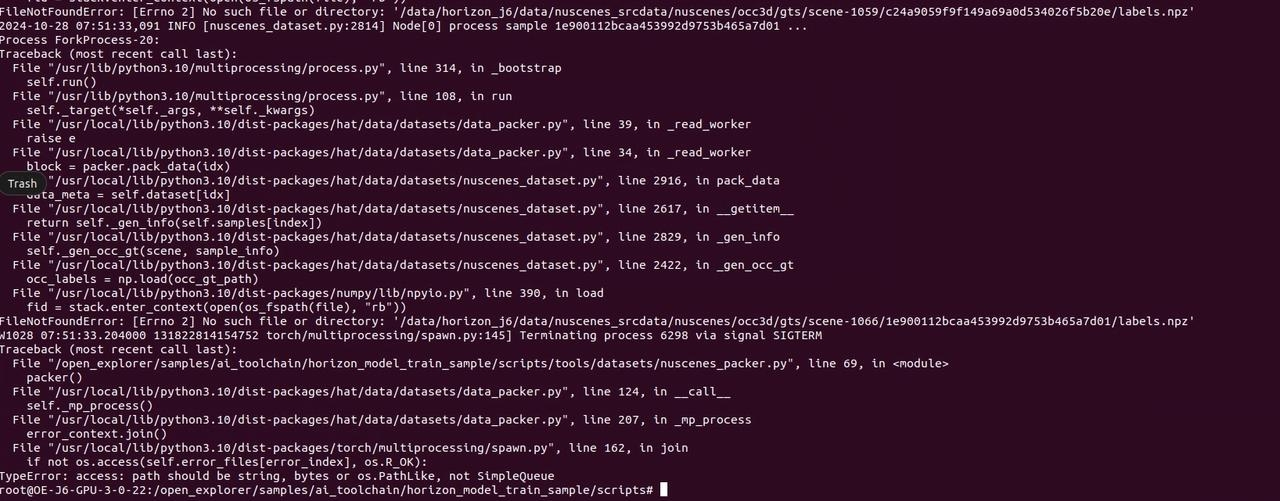
2024-10-31 05:47:55,174 INFO [nuscenes_dataset.py:2814] Node[0] process sample cef5745a54e24c7a9111d449e336b4ed ...
Process ForkProcess-2:
Traceback (most recent call last):
File "/usr/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.10/dist-packages/hat/data/datasets/data_packer.py", line 39, in _read_worker
raise e
File "/usr/local/lib/python3.10/dist-packages/hat/data/datasets/data_packer.py", line 34, in _read_worker
block = packer.pack_data(idx)
File "/usr/local/lib/python3.10/dist-packages/hat/data/datasets/nuscenes_dataset.py", line 2916, in pack_data
data_meta = self.dataset[idx]
File "/usr/local/lib/python3.10/dist-packages/hat/data/datasets/nuscenes_dataset.py", line 2617, in __getitem__
return self._gen_info(self.samples[index])
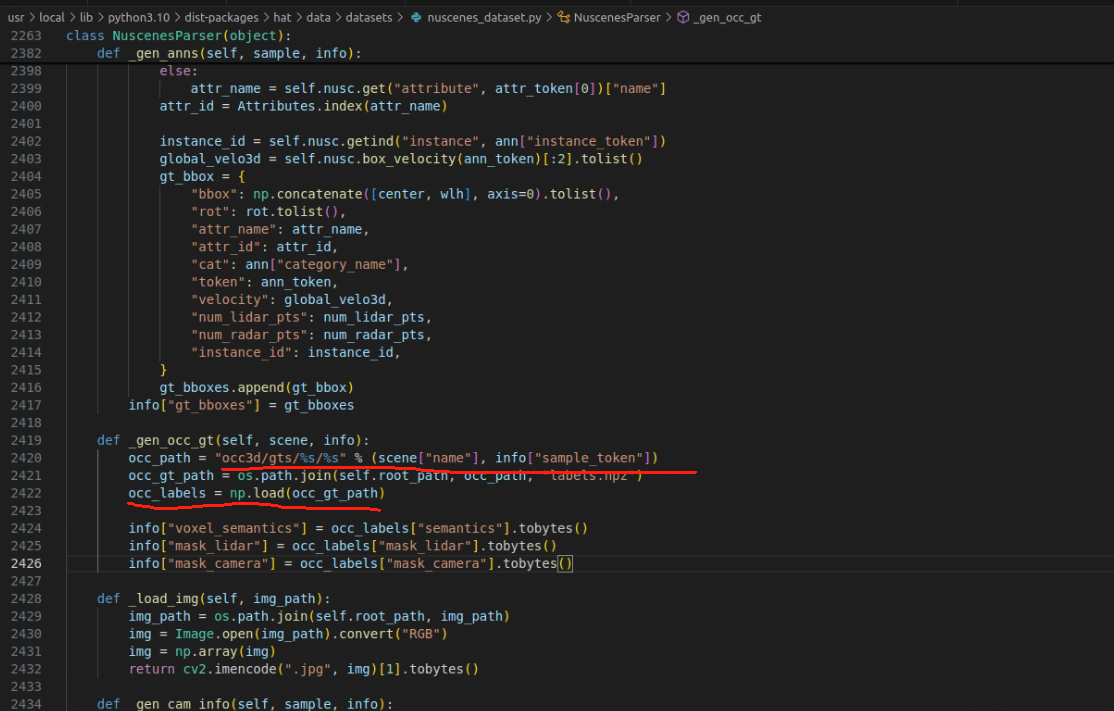
File "/usr/local/lib/python3.10/dist-packages/hat/data/datasets/nuscenes_dataset.py", line 2829, in _gen_info
self._gen_occ_gt(scene, sample_info)
File "/usr/local/lib/python3.10/dist-packages/hat/data/datasets/nuscenes_dataset.py", line 2422, in _gen_occ_gt
occ_labels = np.load(occ_gt_path)
File "/usr/local/lib/python3.10/dist-packages/numpy/lib/npyio.py", line 390, in load
fid = stack.enter_context(open(os_fspath(file), "rb"))
FileNotFoundError: [Errno 2] No such file or directory: '/data/horizon_j6/data/nuscenes_srcdata/nuscenes/occ3d/gts/scene-0273/cef5745a54e24c7a9111d449e336b4ed/labels.npz'
2024-10-31 05:47:55,275 INFO [nuscenes_dataset.py:2814] Node[0] process sample 2e3374eb19ee46e09fd0fa90281fbc7d ...
感觉这个pack过程还用到occ 3d的gts, 难道执行这个脚本前,需要执行摸个occ 3d gts生成脚本吗?
看call stack,这个已经是hat库里面的调用了,


'/%3e%3cpath%20d='M8%200.5C12.1421%200.5%2015.5%203.85786%2015.5%208C15.5%2012.1421%2012.1421%2015.5%208%2015.5C3.85786%2015.5%200.5%2012.1421%200.5%208C0.5%203.85786%203.85786%200.5%208%200.5Z'%20fill='url(%23paint1_linear_0_45845)'%20stroke='white'/%3e%3cpath%20d='M10.0597%204.5332C10.031%204.5332%2010.0036%204.54817%209.98859%204.57313L8.09724%207.79442C8.02613%207.90046%207.84897%208.23731%207.5483%208.7875C7.37863%209.0969%207.25387%209.32771%207.17152%209.48615C7.1341%209.55727%207.0293%209.53855%207.01807%209.45871C6.97191%209.11936%206.89456%208.6066%206.78727%207.91793L6.2483%204.61804C6.24207%204.57812%206.20713%204.54942%206.16721%204.54942H4.28085C4.2297%204.54942%204.18977%204.59683%204.201%204.64798L5.71059%2012.1959C5.71808%2012.2346%205.75176%2012.2621%205.79044%2012.2621H7.46845C7.49715%2012.2621%207.52335%2012.2471%207.53832%2012.2234L12.1869%204.65796C12.2205%204.60307%2012.1806%204.5332%2012.117%204.5332H10.0597Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_0_45845'%20x1='8.99711'%20y1='15.3526'%20x2='47.3575'%20y2='15.3526'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_0_45845'%20x1='1.1152'%20y1='15.1368'%20x2='15.3888'%20y2='15.1368'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23AF86FF'/%3e%3cstop%20offset='1'%20stop-color='%23774EFF'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)